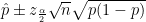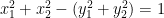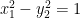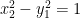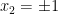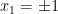Here, we derive the expectation, variance, and moment generating function for the binomial distribution.
Video, when available, will be posted below.

Here, we derive the expectation, variance, and moment generating function for the binomial distribution.
Video, when available, will be posted below.
The video, when ready, will be posted below.


I made a short video; no, I did NOT have “risk factor”/”age group” breakdown, but the overall point is that vaccines, while outstanding, are NOT a suit of perfect armor.
Upshot: I used this local data:

The vaccination rate of the area is slightly under 50 percent; about 80 percent for the 65 and up group. But this data doesn’t break it down among age groups so..again, this is “back of the envelope”:


Again, the efficacy is probably better than that because of the lack of risk factor correction.
Note: the p-value for the statistical test of 
The video:
Let’s start with an example from sports: basketball free throws. At a certain times in a game, a player is awarded a free throw, where the player stands 15 feet away from the basket and is allowed to shoot to make a basket, which is worth 1 point. In the NBA, a player will take 2 or 3 shots; the rules are slightly different for college basketball.
Each player will have a “free throw percentage” which is the number of made shots divided by the number of attempts. For NBA players, the league average is .672 with a variance of .0074.
Now suppose you want to determine how well a player will do, given, say, a sample of the player’s data? Under classical (aka “frequentist” ) statistics, one looks at how well the player has done, calculates the percentage (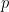
\
Yes, I know..for someone who has played a long time, one has career statistics ..so imagine one is trying to extrapolate for a new player with limited data.
That seems straightforward enough. But what if one samples the player’s shooting during an unusually good or unusually bad streak? Example: former NBA star Larry Bird once made 71 straight free throws…if that were the sample, 
Classical frequentist statistics doesn’t offer a way out but Bayesian Statistics does.
This is a good introduction:
But here is a simple, “rough and ready” introduction. Bayesian statistics uses not only the observed sample, but a proposed distribution for the parameter of interest (in this case, p, the probability of making a free throw). The proposed distribution is called a prior distribution or just prior. That is often labeled 
Since we are dealing with what amounts to 71 Bernoulli trials where p = .672 so the distribution of each random variable describing the outcome of each individual shot has probability mass fuction 


Our goal is to calculate what is known as a posterior distribution (or just posterior) which describes 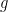

How we go about it: use the principles of joint distributions, likelihood functions and marginal distributions to calculate 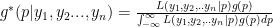
The denominator “integrates out” p to turn that into a marginal; remember that the 

What works well is to use the beta distribution for the prior. Note: the pdf is 




Now look at the numerator which consists of the product of a likelihood function and a density function: up to constant 

The denominator: same thing, but
So, in effect, we have 

So, I will spare you the calculation except to say that that the NBA prior with 
Now the update: 
What does this look like? (I used this calculator)

That is the prior. Now for the posterior:

Yes, shifted to the right..very narrow as well. The information has changed..but we avoid the absurd contention that 
We can now calculate a “credible interval” of, say, 90 percent, to see where

And note that 
We are using Mathematical Statistics with Applications (7’th Ed.) by Wackerly, Mendenhall and Scheaffer for our calculus based probability and statistics course.
They present the following Theorem (5.5 in this edition)
Let 









Ok, that is fine as it goes, but then they apply the above theorem to the joint density function: 
![(y_1,y_2) \in [0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%28y_1%2Cy_2%29+%5Cin+%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

It isn’t that hard to fix, I don’t think.
Now there is the density function 
![[0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

But how does one KNOW that 
I played around a bit and came up with the following:
Statement: 
Proof of the statement: substitute 




Now substitute 

This is hardly profound but I admit that I’ve been negligent in pointing this out to classes.
This blog isn’t about cosmology or about arguments over religion. But it is unusual to hear “on all but a set of measure zero” in the middle of a pop-science talk: (2:40-2:50)
I’ve used the presentation in the our Probability and Statistics text; it is appropriate given that many of our students haven’t seen the Fourier Transform. But this presentation is excellent.
Upshot: use the convolution to derive the density function for 




Ok, a mathematician who is known to be brilliant self-publishes (on the internet) a dense, 512 page proof of a famous conjecture. So what happens?
The Internet exploded. Within days, even the mainstream media had picked up on the story. “World’s Most Complex Mathematical Theory Cracked,” announced the Telegraph. “Possible Breakthrough in ABC Conjecture,” reported the New York Times, more demurely.
On MathOverflow, an online math forum, mathematicians around the world began to debate and discuss Mochizuki’s claim. The question which quickly bubbled to the top of the forum, encouraged by the community’s “upvotes,” was simple: “Can someone briefly explain the philosophy behind his work and comment on why it might be expected to shed light on questions like the ABC conjecture?” asked Andy Putman, assistant professor at Rice University. Or, in plainer words: I don’t get it. Does anyone?
The problem, as many mathematicians were discovering when they flocked to Mochizuki’s website, was that the proof was impossible to read. The first paper, entitled “Inter-universal Teichmuller Theory I: Construction of Hodge Theaters,” starts out by stating that the goal is “to establish an arithmetic version of Teichmuller theory for number fields equipped with an elliptic curve…by applying the theory of semi-graphs of anabelioids, Frobenioids, the etale theta function, and log-shells.”
This is not just gibberish to the average layman. It was gibberish to the math community as well.
[…]
Here is the deal: reading a mid level mathematics research paper is hard work. Refereeing it is even harder work (really checking the proofs) and it is hard work that is not really going to result in anything positive for the person doing the work.
Of course, if you referee for a journal, you do your best because you want YOUR papers to get good refereeing. You want them fairly evaluated and if there is a mistake in your work, it is much better for the referee to catch it than to look like an idiot in front of your community.
But this work was not submitted to a journal. Interesting, no?
Of course, were I to do this, it would be ok to dismiss me as a crank since I haven’t given the mathematical community any reason to grant me the benefit of the doubt.
And speaking of idiots; I made a rather foolish remark in the comments section of this article by Edward Frenkel in Scientific American. The article itself is fine: it is about the Abel prize and the work by Pierre Deligne which won this prize. The work deals with what one might call the geometry of number theory. The idea: if one wants to look for solutions to an equation, say, 

such as x2 + y2 = 1, we can look for its solutions in different domains: in the familiar numerical systems, such as real or complex numbers, or in less familiar ones, like natural numbers modulo N. For example, solutions of the above equation in real numbers form a circle, but solutions in complex numbers form a sphere.
The comment that I bolded didn’t make sense to me; I did a quick look up and reviewed that 

This is easy to see: if 

Frenkel made a patient, kind response …and as soon as I read “equate real and imaginary parts” I winced with self-embarrassment.
Of course, he admits that the complex version of this equation really yields a PUNCTURED sphere; basically a copy of 
Just for fun, let’s look at this beast.
Real part of the equation:
Imaginary part: 
Now let’s look at the intersection of this surface in 4 space with some coordinate planes:
Clearly this surface misses the 
Intersection with the 

Intersection with the 
Intersection with the 
Intersection with the 
Intersection with the 
(so we know that this object is non-compact; this is one reason the “sphere” remark puzzled me)
Science and the media
This Guardian article points out that it is hard to do good science reporting that goes beyond information entertainment. Of course, one of the reasons is that many “groundbreaking” science findings turn out to be false, even if the scientists in question did their work carefully. If this sounds strange, consider the following “thought experiment”: suppose that there are, say, 1000 factors that one can study and only 1 of them is relevant to the issue at hand (say, one place on the genome might indicate a genuine risk factor for a given disease, and it makes sense to study 1000 different places). So you take one at random, run a statistical test at 
So let P represent a positive outcome of a test, N a negative outcome, T means that this is a genuine factor, and F that it isn’t.
Note: P(T) = .001, P(F) = .999, 

So we seek: the probability that a result is true given that a positive test occurred: we seek 
I got this from Mano Singham’s blog: he is a physics professor who mostly writes about social issues. But on occasion he writes about physics and mathematics, as he does here. In this post, he talks about the transitive property.
Most students are familiar with this property; roughly speaking it says that if one has a partially ordered set and 
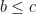


What we have going here: Red beats green 4 out of 6 times. Green beats blue 4 out of 6 times. Blue beats red 4 out of 6 times. All the colored dice tie the “normal” die. Yet, the means of the numbers are all the same.
Note: that this can happen is probably not a surprise to sports fans; for example, in boxing: Ken Norton beat Muhammed Ali (the first time), George Foreman destroyed Ken Norton and, Ali beat Foreman in a classic. Of course things like this happen in sports like basketball but when team doesn’t always play its best or its worst.
But this dice example works so beautifully because this “impossibility of the dice obeying a transitive ordering relation is theoretically impossible, by design.
Movies
Since the wife has been gone on a trip, I’ve watched some old movies at night. One of them was the Cincinnati Kid, which features this classic scene:
Basically, the Kid has a full house, but ends up losing to a straight flush. Yes, the odds of the ten cards (in stud poker) ending up in “one hand a full house, the other a straight flush” are extremely remote. I haven’t done the calculations but this assertion seems plausible:
Holden states that the chances of both such hands appearing in one deal are “a laughable” 332,220,508,619 to 1 (more than 332 billion to 1 against) and goes on: “If these two played 50 hands of stud an hour, eight hours a day, five days a week, the situation would arise about once every 443 years.”
But there is one remark from this Wikipedia article that seems interesting:
The unlikely nature of the final hand is discussed by Anthony Holden in his book Big Deal: A Year as a Professional Poker Player, “the odds against any full house losing to any straight flush, in a two-handed game, are 45,102,781 to 1,”
I haven’t done the calculation but that seems plausible. But, here is the real point to the final scene: the Kid knows that he has a full house but The Man is showing 8, 9, 10, Q of diamonds. He knows that the only “down” card that can beat him is the J of diamonds but he knows that he has 3 10’s, 2 A’s. So there are, to his knowledge,