The mathematics major is not one that often gets cut, but that is what happened to us. I admit that I saw it coming. Yes, there will be litigation, law suits etc, but most of that is personnel oriented. The fact is that, for now, our math major is gone; not that we won’t try to bring it back when our current top administrators leave, one way or another.
Yes, tenured faculty were cut. That is where litigation will come in. And yes, there is grief over that…a lot of it.
But that is not what this post will focus on.
For some of my colleagues, there is a profound sense of grief of being a math professor at a university that will no longer offer a math major. For them: a big part of their identity was being a mathematician.
Sadly, that isn’t true of me; I lost my identity of being a mathematician decades ago.
Time and time again, I’d go to a conference, be fired up about what I saw, return to campus…and watched the ideas in my head die a slow death under 11-12 hour teaching loads, committee work, etc. Over time, I started switching to MAA type conferences (Mathfest, for example) and finding joy in teaching “out of area” courses, even actuarial science ones. I sort of became “known” for that.
And yeah, I did research, picking off a problem here and there and did enough to make Full Professor at my institution. But more and more, by research became more shallow and more broad. And frankly I lost the appetite for all of the BS that comes with publication (type setting, figures, dealing with pedantic referees, etc) Yes, I have a paper at the referee’s now and I owe a referee’s report as well.
But..well, when I see what the mathematicians are doing at the R1 universities (e. g. Big Ten);, well, what I do simply does not compare..it never did. I came to accept that decades ago.
This is a long winded way of saying that I suffered no ego bruise from this.
Note: I am not saying this is totally over; if/when we get better leardership I might attempt to bring a math major back (yes, I am the incoming chair of the department).
Moving forward: I think that the math major is on the wane, at least at the non-elite universities.
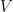 be a vector space with some scalars
be a vector space with some scalars 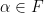 . I’ll assume you know what a spanning set is and what it means to be linearly independent.
. I’ll assume you know what a spanning set is and what it means to be linearly independent.  , say,
, say,  . The coefficients are real numbers and the set of scalars
. The coefficients are real numbers and the set of scalars 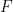 will be the real numbers. (note: the set of scalars are sometimes called a “field”). So one basis (there are many others) is
will be the real numbers. (note: the set of scalars are sometimes called a “field”). So one basis (there are many others) is 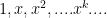 and since there is no limit to the degree of the polynomial, the basis must have an infinite number of vectors.
and since there is no limit to the degree of the polynomial, the basis must have an infinite number of vectors.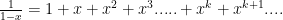 (
( ) this definition depends on infinite series, which in turn requires a limiting process, which then requires a notion of “being close” (the delta- epsilon stuff) In some vector spaces there IS a way to do that, but you need the notion of “inner product” to define size and closeness (remember the dot product from calculus?) and then you can introduce ideas like convergence of an infinite sum. For example, check out
) this definition depends on infinite series, which in turn requires a limiting process, which then requires a notion of “being close” (the delta- epsilon stuff) In some vector spaces there IS a way to do that, but you need the notion of “inner product” to define size and closeness (remember the dot product from calculus?) and then you can introduce ideas like convergence of an infinite sum. For example, check out  on
on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . The scalars will be the real numbers. Now this is a weird vector space. Remember that what is included are things like polynomials, rational functions without roots in
. The scalars will be the real numbers. Now this is a weird vector space. Remember that what is included are things like polynomials, rational functions without roots in 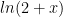 and even piecewise defined functions whose graphs meet up at all points. And that is only the beginning.
and even piecewise defined functions whose graphs meet up at all points. And that is only the beginning.  . Let
. Let  denote the span of this vector. Now if the span is not all of
denote the span of this vector. Now if the span is not all of 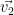 not in the span. Let the span of
not in the span. Let the span of  be denoted by
be denoted by  . If
. If  we have our basis, we are done. Otherwise, we continue on.
we have our basis, we are done. Otherwise, we continue on.  we obtain a chain of nested subsets
we obtain a chain of nested subsets 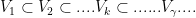 and this chain has an upper bound, namely
and this chain has an upper bound, namely 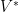 .
. 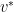 are linearly independent and span all of
are linearly independent and span all of  .
.
 and, by construction, are linearly dependent (order these vectors and remember how we got them: we added vectors by adding what was NOT in the span of the previous vectors.
and, by construction, are linearly dependent (order these vectors and remember how we got them: we added vectors by adding what was NOT in the span of the previous vectors. is NOT in the span. Then let
is NOT in the span. Then let 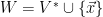 . This is then in the chain and contains
. This is then in the chain and contains 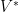 which violates the fact that
which violates the fact that  is maximal.
is maximal.  (expand about 0) and assume that
(expand about 0) and assume that  has as many continuous derivatives as desired on an interval connecting 0 to
has as many continuous derivatives as desired on an interval connecting 0 to 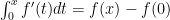 , of course. But we could do the integral another way: let’s use parts and say
, of course. But we could do the integral another way: let’s use parts and say 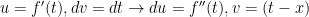 . Note the choice for
. Note the choice for  and that
and that 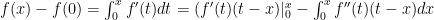 . Evaluation:
. Evaluation: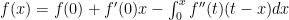 and we’ve completed the first step.
and we’ve completed the first step. 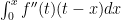 by parts again, with
by parts again, with 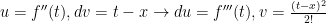 and insert into our previous expression:
and insert into our previous expression: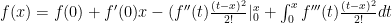 which works out to:
which works out to: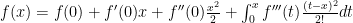 and note the alternating sign of the integral.
and note the alternating sign of the integral. 
 . Taking some care with the signs we end up with
. Taking some care with the signs we end up with which works out to
which works out to 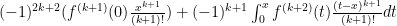 .
.  and the integral picks that up, but it may well be hidden, or at least non-obvious.
and the integral picks that up, but it may well be hidden, or at least non-obvious. . We know from work with the geometric series that its series expansion is
. We know from work with the geometric series that its series expansion is 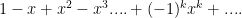 and that the interval of convergence is
and that the interval of convergence is  But note that
But note that 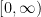 and so our Taylor polynomial, with integral correction, should work for
and so our Taylor polynomial, with integral correction, should work for 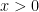 .
. our k-th Taylor polynomial relation is:
our k-th Taylor polynomial relation is:
 .
. 
 so our integral is transformed into:
so our integral is transformed into:
 no matter how big we make
no matter how big we make 
 and now solve for
and now solve for  algebraically .
algebraically . 






