This is making the rounds on social media:

Now a good explanation as to what is going on can be found here; it is written by an experienced high school math teacher.
I’ll give my take on this; I am NOT writing this for other math professors; they would likely be bored by what I am about to say.
My take
First of all, I am NOT defending the mathematics standards of Common Core. For one: I haven’t read them. Another: I have no experience teaching below the college level. What works in my classroom would probably not work in most high school and grade school classrooms.
But I think that I can give some insight as to what is going on with this example (in the photo).
When one teaches mathematics, one often teaches BOTH how to calculate and the concepts behind the calculation techniques. Of course, one has to learn the calculation technique; no one (that I know) disputes that.
What is going on in the photo
The second “calculation” is an exercise designed to help students learn the concept of subtraction and NOT “this is how you do the calculation”.
Suppose one wants to show the students that subtracting two numbers yields “the distance on the number line between those numbers”. So, “how far away from 12 is 32? Well, one moves 3 units to get to 15, then 5 to get to 20. Now that we are at 20 (a multiple of 10), it is easy to move one unit of 10 to get to 30, then 2 more units to get to 32. So we’ve moved 20 units total.
Think of it this way: in the days prior to google maps and gps systems, imagine you are taking a trip from, say, Morton, IL to Chicago and you wanted to take interstate highways all of the way. You wanted to figure the mileage.
You notice (I am making these numbers up) that the “distance between big cities” map lists 45 miles from Peoria to Bloomington and 150 miles from Bloomington to Chicago. Then you look at the little numbers on the map to see that Morton is between Peoria and Bloomington: 10 miles away from Peoria.
So, to find the distance, you calculate (45-10) + 150 = 185 miles; you used the “known mileages” as guide posts and used the little map numbers as a guide to get from the small town (Morton) to the nearest city for which the “table mileage” was calculated.
That is what is going on in the photo.
Why the concept is important
There are many reasons. The “distance between nodes” concept is heavily used in graph theory and in operations research. But I’ll give a demonstration in numerical methods:
Suppose one needs a numerical approximation of 
But one notices that the integrand is periodic; there is no need to integrate along the entire range.
Note that there are 7 complete periods of 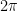

In fact, why not approximate 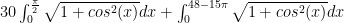
The concept of calculating distance in terms of set segment lengths comes in handy.
Or, one can think of it this way
When we teach derivatives, we certainly teach how to calculate using the standard differentiation rules. BUT we also teach the limit definition as well, though one wouldn’t use that definition in the middle of, say, “find the maximum and minimum of 
![[\frac{1}{4}, 3]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7B1%7D%7B4%7D%2C+3%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
But if you saw some kid’s homework and saw 

 figure: IF you assume that this figure is correct, what is different about this figure and those on its row and the row beneath it? If the figure is assumed to be wrong, how might you fix the formula to make this right?
figure: IF you assume that this figure is correct, what is different about this figure and those on its row and the row beneath it? If the figure is assumed to be wrong, how might you fix the formula to make this right?  figure, what assumption is made about
figure, what assumption is made about  ?
? figure, what assumption is made about
figure, what assumption is made about 
 has 3 continuous derivatives on the appropriate interval)
has 3 continuous derivatives on the appropriate interval) where
where  is some point in the interval.
is some point in the interval. .
.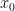 or using the Lagrange polynomial through the given points and differentiating.
or using the Lagrange polynomial through the given points and differentiating. vary from, say, 0 to 3 and let
vary from, say, 0 to 3 and let  . Now use the three point derivative estimates on the following functions:
. Now use the three point derivative estimates on the following functions: .
. .
.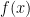 and
and  . It is easy to see why.
. It is easy to see why.

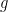 , the degree that
, the degree that  wanders away from
wanders away from 
 described as follows:
described as follows:  Now the projection map to the
Now the projection map to the  plane is given by
plane is given by  and the image set is
and the image set is  which is a disk (in the yellow).
which is a disk (in the yellow).  plane is given by
plane is given by  and the image is
and the image is  which is a rectangle (in the blue).
which is a rectangle (in the blue). 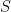 . In fact, both of these projections, taken together, do not determine the object. For example: the “hollow can” in the shape of our
. In fact, both of these projections, taken together, do not determine the object. For example: the “hollow can” in the shape of our  to be a manifold of either 2 or 3 dimensions, or some other criteria. But THAT would be adding more information to the mix and thereby, in a sense, providing yet another projection map.
to be a manifold of either 2 or 3 dimensions, or some other criteria. But THAT would be adding more information to the mix and thereby, in a sense, providing yet another projection map. values as well as the correlation coefficient and the regression coefficients.
values as well as the correlation coefficient and the regression coefficients. 

 where
where  is some number in
is some number in ![[x_0 -h, x_0 + h]](https://s0.wp.com/latex.php?latex=%5Bx_0+-h%2C+x_0+%2B+h%5D+&bg=ffffff&fg=000000&s=0&c=20201002) ; of course we assume that the third derivative is continuous in this interval.
; of course we assume that the third derivative is continuous in this interval. and differentiate or one can use the degree 2 Taylor polynomial expanded about
and differentiate or one can use the degree 2 Taylor polynomial expanded about  and use
and use  and solve for
and solve for  ; of course one runs into some issues with the remainder term if one uses the Taylor method.
; of course one runs into some issues with the remainder term if one uses the Taylor method.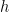 ?” In theory, we should get a better approximation if we make
?” In theory, we should get a better approximation if we make  but rather
but rather  where
where  where
where  is the round off error used in calculating the function at
is the round off error used in calculating the function at  and the magnitude of the actual error is bounded by
and the magnitude of the actual error is bounded by  where
where  on some small neighborhood of
on some small neighborhood of  is a bound on the round-off error of representing
is a bound on the round-off error of representing  .
. .
.  and then do some experimentation to determine
and then do some experimentation to determine 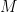 (a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for
(a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for  ; of course
; of course  and
and  is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of
is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of  and at
and at 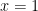 respectively. In the first case, use
respectively. In the first case, use 

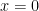 case, we see that the error starts to increase again at about
case, we see that the error starts to increase again at about  ; the same sort of thing appears to happen for
; the same sort of thing appears to happen for  ; it is roughly
; it is roughly  at
at  .
. instead; something interesting happens in the
instead; something interesting happens in the  scale by doing the following (approximating
scale by doing the following (approximating  for
for 
 . The graph looks like:
. The graph looks like:
 axis: let
axis: let  and run plot(N, LE):
and run plot(N, LE):
 , which is the same as EXCEL.
, which is the same as EXCEL. with the usual geometry induced by the usual “dot product”.
with the usual geometry induced by the usual “dot product”.
 is said to be convex if for any two points
is said to be convex if for any two points  , the straight line segment connecting
, the straight line segment connecting 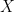 ; that is, the set
; that is, the set  for all
for all ![t \in [0,1]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) .
. 
 . The convex hull
. The convex hull 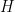 for
for 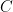 is the smallest convex set which contains all of
is the smallest convex set which contains all of  is any convex set that contains
is any convex set that contains  . In the case where the set of points is finite (say,
. In the case where the set of points is finite (say,  then
then  where
where  and
and  .
.  is a positive integer and
is a positive integer and  numbers (real, complex, or even arbitrary field elements),
numbers (real, complex, or even arbitrary field elements),  , where
, where  . For example,
. For example,  .
. Note that this expression is equal to 1 for ALL values of
Note that this expression is equal to 1 for ALL values of 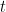 and that for
and that for  is positive or zero.
is positive or zero.  . We now see that for all
. We now see that for all ![t \in [0,1], 0 \le b_{j,n}(t) \le 1](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C1%5D%2C+0+%5Cle+b_%7Bj%2Cn%7D%28t%29+%5Cle+1+&bg=ffffff&fg=000000&s=0&c=20201002) and
and 
 be a collection of distinct points in
be a collection of distinct points in  . One can think of these points as vectors.
. One can think of these points as vectors.![B(t)= \sum^n_{j=0}b_{j,n}(t)P_j, t \in [0,1]](https://s0.wp.com/latex.php?latex=B%28t%29%3D++%5Csum%5En_%7Bj%3D0%7Db_%7Bj%2Cn%7D%28t%29P_j%2C+t+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) .
. . This is clear because
. This is clear because  and for
and for  .
. is called the control polygon for the Bézier curve.
is called the control polygon for the Bézier curve.![t \in [0,1], B(t)](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C1%5D%2C+B%28t%29+&bg=ffffff&fg=000000&s=0&c=20201002) is in the convex hull of
is in the convex hull of  . This is clear because
. This is clear because  is positive.
is positive. 
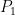 and
and  directly affect the (one sided) tangent to the Bézier curve at
directly affect the (one sided) tangent to the Bézier curve at  . In fact we will show that if we use the one-sided parametric curve derivative, we see that
. In fact we will show that if we use the one-sided parametric curve derivative, we see that  . The text calls
. The text calls  the scaling factor and notes that the scaling factor is 3 when
the scaling factor and notes that the scaling factor is 3 when  .
. for the general degree
for the general degree  . Now take the derivative and we see:
. Now take the derivative and we see:
 has both a factor of
has both a factor of  in it; hence this middle term evaluates to zero when
in it; hence this middle term evaluates to zero when  and is therefor irrelevant to the calculation of
and is therefor irrelevant to the calculation of  and
and  .
. (the last two terms are zero at
(the last two terms are zero at  and
and  (the first two terms are zero at
(the first two terms are zero at  ).
).  respectively. Of course, the tangent vector has a magnitude (norm) as well, and that certainly affects the curve.
respectively. Of course, the tangent vector has a magnitude (norm) as well, and that certainly affects the curve. 
 and the points that are filled in with gray are the control points
and the points that are filled in with gray are the control points  . The last curve is two Bézier cubics joined together.
. The last curve is two Bézier cubics joined together.  and
and  .
.