My interest in “beta” functions comes from their utility in Bayesian statistics. A nice 78 minute introduction to Bayesian statistics and how the beta distribution is used can be found here; you need to understand basic mathematical statistics concepts such as “joint density”, “marginal density”, “Bayes’ Rule” and “likelihood function” to follow the youtube lecture. To follow this post, one should know the standard “3 semesters” of calculus and know what the gamma function is (the extension of the factorial function to the real numbers); previous exposure to the standard “polar coordinates” proof that 
So, what it the beta function? it is 




Now it turns out that the beta density function is defined as follows: 


I'll do this in two steps. Step one will convert the beta integral into an integral involving powers of sine and cosine. Step two will be to write 

Step one: converting the beta integral to a sine/cosine integral. Limit ![t \in [0, \frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+%5Cfrac%7B%5Cpi%7D%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)


Step two: transforming the product of two gamma functions into a double integral and evaluating using polar coordinates.
Write 
Now do the conversion 

From which we now obtain

Now we switch to polar coordinates, remembering the 


This splits into two integrals:

The first of these integrals is just 

The second integral: we just use 

And so the result follows.
That seems complicated for a simple little integral, doesn’t it?
 is said to be sufficient for
is said to be sufficient for  if the conditional distribution
if the conditional distribution  , that is, doesn’t depend on
, that is, doesn’t depend on 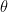 . Intuitively, we mean that a given statistic provides as much information as possible about
. Intuitively, we mean that a given statistic provides as much information as possible about  alone and a function of the
alone and a function of the  alone.
alone.  come from a uniform distribution on
come from a uniform distribution on ![[-\theta, \theta]](https://s0.wp.com/latex.php?latex=%5B-%5Ctheta%2C+%5Ctheta%5D+&bg=ffffff&fg=000000&s=0&c=20201002) .
.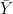 could be sufficient for
could be sufficient for  goes to infinity.
goes to infinity.  where
where ![H_{[a,b]}](https://s0.wp.com/latex.php?latex=H_%7B%5Ba%2Cb%5D%7D+&bg=ffffff&fg=000000&s=0&c=20201002) is the standard Heavyside function on the interval
is the standard Heavyside function on the interval ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) (equal to one on the support set
(equal to one on the support set  is the
is the  order statistic for the absolute values of the observations).
order statistic for the absolute values of the observations).