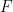The MAA Mathfest in Chicago was a success for me. I talked about some other talks I went to; my favorite was probably the one given by Douglas Arnold. I wish I had had this talk prior to teaching numerical analysis for the fist time.
Confession: my research specialty is knot theory (a subset of 3-manifold topology); all of my graduate program classes have been in pure mathematics. I last took numerical analysis as an undergraduate in 1980 and as a “part time, not taking things seriously” masters student in 1981 (at UTSA of all places).
In each course…I. Made. A. “C”.
Needless to say, I didn’t learn a damned thing, even though both professors gave decent courses. The fault was mine.
But…I was what my department had, and away I went to teach the course. The first couple of times, I studied hard and stayed maybe 2 weeks ahead of the class.
Nevertheless, I found the material fascinating.
When it came to understanding how to find a numerical approximation to an ordinary differential equation (say, first order), you have:  with some initial value for both
with some initial value for both  . All of the techniques use some sort of “linearization of the function” technique to: given a step size, approximate the value of the function at the end of the next step. One chooses a step size, and some sort of schemes to approximate an “average slope” (e. g. Runga-Kutta is one of the best known).
. All of the techniques use some sort of “linearization of the function” technique to: given a step size, approximate the value of the function at the end of the next step. One chooses a step size, and some sort of schemes to approximate an “average slope” (e. g. Runga-Kutta is one of the best known).
This is a lot like numerical integration, but in integration, one knows  for all values; here you have to infer from previous approximations of %latex y(t) $. And there are things like error (often calculated by using some sort of approximation to
for all values; here you have to infer from previous approximations of %latex y(t) $. And there are things like error (often calculated by using some sort of approximation to 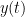 such as, say, the Taylor polynomial, and error terms which are based on things like the second derivative.
such as, say, the Taylor polynomial, and error terms which are based on things like the second derivative.
And yes, I faithfully taught all that. But what was unknown to me is WHY one might choose one method over another..and much of this is based on the type of problem that one is attempting to solve.
And this is the idea: take something like the Euler method, where one estimates  . You repeat this process a bunch of times thereby obtaining a sequence of approximations for . Hopefully, you get something close to the “true solution” (unknown to you) (and yes, the Euler method is fine for existence theorems and for teaching, but it is too crude for most applications).
. You repeat this process a bunch of times thereby obtaining a sequence of approximations for . Hopefully, you get something close to the “true solution” (unknown to you) (and yes, the Euler method is fine for existence theorems and for teaching, but it is too crude for most applications).
But the Euler method DOES yield a piecewise linear approximation to SOME 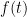 which might be close to
which might be close to  (a good approximation) or possibly far away from it (a bad approximation). And this that you actually get from the Euler (or other method) is important.
(a good approximation) or possibly far away from it (a bad approximation). And this that you actually get from the Euler (or other method) is important.
It turns out that some implicit methods (using an approximation to obtain  and then using THAT to refine your approximation can lead to a more stable system of (the solution that you actually obtain…not the one that you are seeking to obtain) in that this system of “actual functions” might not have a source or a sink…and therefore never spiral out of control. But this comes from the mathematics of the type of equations that you are seeking to obtain an approximation for. This type of example was presented in the talk that I went to.
and then using THAT to refine your approximation can lead to a more stable system of (the solution that you actually obtain…not the one that you are seeking to obtain) in that this system of “actual functions” might not have a source or a sink…and therefore never spiral out of control. But this comes from the mathematics of the type of equations that you are seeking to obtain an approximation for. This type of example was presented in the talk that I went to.
In other words, we need a large toolbox of approximations to use because some methods work better with certain types of problems.
I wish that I had known that before…but I know it now. 🙂