I am sitting in the main ballroom waiting for the large public talks to start. I should be busy most of the day; it looks as if there will be some interesting all day long.
I like this conference not only for the variety but also for the timing; it gives me some momentum going into the academic year.
I regret not taking my camera; downtown Madison is scenic and we are close to the water. The conference venue is just a short walk away from the hotel; I see some possibilities for tomorrow’s run. Today: just weights and maybe a bit of treadmill in the afternoon.
The Talks
The opening lecture was the MAA-AMS joint talk by David Mumford of Brown University. This guy’s credentials are beyond stellar: Fields Medal, member of the National Academy of Science, etc.
His talk was about applied and pure mathematics and how there really shouldn’t be that much of a separation between the two, though there is. For one thing: pure mathematics prestige is measured by the depth of the result; applied mathematical prestige is mostly measured by the utility of the produced model. Pure mathematicians tend to see applied mathematics as shallow and simple and they resent the fact that applied math…gets a lot more funding.
He talked a bit about education and how the educational establishment ought to solicit input from pure areas; he also talked about computer science education (in secondary schools) and mentioned that there should be more emphasis on coding (I agree).
He mentioned that he tended to learn better when he had a concrete example to start from (I am the same way).
What amused me: his FIRST example was on PDE (partial differential equations) model of neutron flux through nuclear reactors used for submarines; note that these reactors were light water, thermal reactors (in that the fission reaction became self sustaining via the absorption of neutrons whose energy levels had been lowered by a moderator (the neutrons lose energy when they collide with atoms that aren’t too much heavier).
Of course, in nuclear power school, we studied the PDEs of the situation after the design had been developed; these people had to come up with an optimal geometry to begin with.
Note that they didn’t have modern digital computers; they used analogue computers modeled after simple voltage drops across resistors!
About the PDE: you had two neutron populations: “fast” neutrons (ones at high energy levels) and “slow” neutrons (ones at lower energy levels). The fast neutrons are slowed down to become thermal neutrons. But thermal neutrons in turn cause more fissions thereby increasing the fast neutron flux; hence you have two linked PDEs. Of course there is leakage, absorption by control rods, etc., and the classical PDEs can’t be solved in closed form.
Another thing I didn’t know: Clairaut (from the “symmetry of mixed partial derivatives” fame) actually came up with the idea of the Fourier series before Fourier did; he did this in an applied setting.
Next talk Amie Wilkinson of Northwestern (soon to be University of Chicago) gave a talk about dynamical systems. She is one of those who has publication in the finest journals that mathematics has to offer (stellar).
The whole talk was pretty good. Highlights: she mentioned Henri Poincare and how he worked on the 3-body problem (one massive body, one medium body, and one tiny body that didn’t exert gravitational force on the other bodies). This creates a 3-dimensional system whose dynamics live in 3-space (the system space is, of course, has much higher dimension). Now consider a closed 2 dimensional manifold in that space and a point on that manifold. Now study the orbit of that point under the dynamical system action. Eventually, that orbit intersects the 2 dimensional manifold again. The action of moving from the first point to the first intersection point actually describes a motion ON THE TWO MANIFOLD and if we look at ALL intersections, we get a the orbit of that point, considered as an action on the two dimensional manifold.
So, in some sense, this two manifold has an “inherited” action on it. Now if we look at, say, a square on that 2-dimensional manifold, it was proved that this square comes back in a “folded” fashion: this is the famed “Smale Horseshoe map“:

Other things: she mentioned that there are dynamical systems that are stable with respect to perturbations that have unstable orbits (with respect to initial conditions) and that these instabilities cannot be perturbed away; they are inherent to the system. There are other dynamical systems (with less stability) that have this property as well.
There is, of course, much more. I’ll link to the lecture materials when I find them.
Last morning Talk
Bernd Sturmfels on Tropical Mathematics
Ok, quickly, if you have a semi-ring (no additive inverses) with the following operations:
 min
min  and
and  (check that the operations distribute), what good would it be? Why would you care about such a beast?
(check that the operations distribute), what good would it be? Why would you care about such a beast?
Answer: many reasons. This sort of object lends itself well to things like matrix operations and is used for things such as “least path” problems (dynamic programming) and “tree metrics” in biology.
Think of it this way: if one is considering, say, an “order n” technique in numerical analysis, then the products of the error terms adds to the order, and the sum of the errors gives the, ok, maximum of the two summands (very similar).
The PDF of the slides in today’s lecture can be found here.
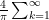




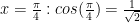


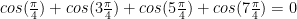
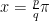

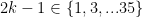




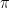





 .
. )
)
![[-l,l]](https://s0.wp.com/latex.php?latex=%5B-l%2Cl%5D+&bg=ffffff&fg=000000&s=0&c=20201002) derive the middle formula.
derive the middle formula. 
 subject to boundary conditions:
subject to boundary conditions:
 where
where 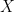 is a function of
is a function of 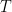 is a function of
is a function of 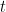 alone. Then when we substitute into the partial differential equation we obtain:
alone. Then when we substitute into the partial differential equation we obtain: which leads to
which leads to 

 is an eigenvalue. What is that about?
is an eigenvalue. What is that about? and
and 
 with the operator
with the operator  denoting the first derivative. Then the second can be written as
denoting the first derivative. Then the second can be written as  where
where  denotes the second derivative operator. Recall from linear algebra that these operators meet the requirements for a linear transformation if the vector space is the set of all functions that are “differentiable enough”. So what we are doing, in effect, are trying to find eigenvectors for these operators.
denotes the second derivative operator. Recall from linear algebra that these operators meet the requirements for a linear transformation if the vector space is the set of all functions that are “differentiable enough”. So what we are doing, in effect, are trying to find eigenvectors for these operators.
 ; the real valued form of the equation in
; the real valued form of the equation in  cannot meet the zero at the boundaries conditions; we can rule out the
cannot meet the zero at the boundaries conditions; we can rule out the  condition as well.
condition as well. solution and then
solution and then  solution.
solution. If we look at the end conditions and note that
If we look at the end conditions and note that  ) and we can ensure that
) and we can ensure that  which implies that
which implies that  So we get a whole host of functions:
So we get a whole host of functions:  .
. ) and that is where Fourier analysis comes in. Because the equation was linear, we can add the solutions and get another solution; hence the
) and that is where Fourier analysis comes in. Because the equation was linear, we can add the solutions and get another solution; hence the  in terms of sines.
in terms of sines.  and the solution is:
and the solution is:
 and obtain measurement
and obtain measurement  then the new system eigenvector is
then the new system eigenvector is  regardless of what
regardless of what  was prior to measurement. Of course, this eigenvector can (and usually will) evolve with time.
was prior to measurement. Of course, this eigenvector can (and usually will) evolve with time.  as a measurement. Recall: remember all of those “orbitals” from chemistry class? Those were the energy levels of the electrons and the orbital level was a permissible energy state that we could obtain by a measurement.
as a measurement. Recall: remember all of those “orbitals” from chemistry class? Those were the energy levels of the electrons and the orbital level was a permissible energy state that we could obtain by a measurement.  .
.![[-\pi, \pi]](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C+%5Cpi%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and let our “state vector”
and let our “state vector” 
 so our new state vector is
so our new state vector is  . These polynomials obey the orthogonality relation
. These polynomials obey the orthogonality relation  hence
hence  .
.
 and multiply each polynomial
and multiply each polynomial  by the factor
by the factor  to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule.
to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule. denote the adjusted Legendre polynomial with eigenvalue
denote the adjusted Legendre polynomial with eigenvalue  .
. is observed as an observable with the Lengendre operator; this corresponds to eigenvector
is observed as an observable with the Lengendre operator; this corresponds to eigenvector  which is now the new state vector.
which is now the new state vector. which has an eigenbasis
which has an eigenbasis  and
and  with eigenvalues
with eigenvalues  (note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).
(note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).  as required for an orthonormal basis with this inner product.
as required for an orthonormal basis with this inner product. 




 .
. 