This blog isn’t about cosmology or about arguments over religion. But it is unusual to hear “on all but a set of measure zero” in the middle of a pop-science talk: (2:40-2:50)
This blog isn’t about cosmology or about arguments over religion. But it is unusual to hear “on all but a set of measure zero” in the middle of a pop-science talk: (2:40-2:50)
One thing that surprised me about the professor’s job (at a non-research intensive school; we have a modest but real research requirement, but mostly we teach): I never knew how much time I’d spend doing tasks that have nothing to do with teaching and scholarship. Groan….how much of this do I tell our applicants that arrive on campus to interview? 🙂
But there is something mathematical that I want to talk about; it is a follow up to this post. It has to do with what string theorist tell us: 
Where I think the problem is: when we hear “series” we think of something related to the usual process of addition. Clearly, this non-standard assignment doesn’t related to addition in the way we usually think about it.
So, it might make more sense to think of a “generalized series” as a map from the set of sequences of real numbers (or: the infinite dimensional real vector space) to the real numbers; the usual “limit of partial sums” definition has some nice properties with respect to sequence addition, scalar multiplication and with respect to a “shift operation” and addition, provided we restrict ourselves to a suitable collection of sequences (say, those whose traditional sum of components are absolutely convergent).
So, this “non-standard sum” can be thought of as a map 

One “fun” math book is Knopp’s book Theory and Application of Infinite Series. I highly recommend it to anyone who frequently teaches calculus, or to talented, motivated calculus students.
One of the more interesting chapters in the book is on “divergent series”. If that sounds boring consider the following:
we all know that 

Consider
of course this is a divergent geometric series by the usual definition. But note that if one uses the geometric series formula:


Now this is nonsense unless we use a different definition of sum convergence, such as the Cesaro summation: if 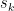



(see here)
So for our 

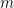



Now, we have this weird type of assignment.
But that won’t help with 

What the heck? Well, one way this is done is explained here:
Consider 







Now of course, if one uses the usual definitions of convergence, I played fast and loose with the usual intervals of convergence and when I could differentiate term by term. This theory is NOT the usual calculus theory.
Now if you want to see some “fun nonsense” applied to this (spot how many “errors” are made….it is a nice exercise):
And read this to see exploding heads. 🙂
What is going on: when one sums a series, one is really “assigning a value” to an object; think of this as a type of morphism of the set of series to the set of numbers. The usual definition of “sum of a series” is an especially nice morphism as it allows, WITH PRECAUTIONS, some nice algebraic operations in the domain (the set of series) to be carried over into the range. I say “with precautions” because of things like the following:
1. If one is talking about series of numbers, then one must have an absolutely convergent series for derangements of a given series to be assigned the same number. Example: it is well known that a conditionally convergent alternating series can be arranged to converge to any value of choice.
2. If one is talking about a series of functions (say, power series where one sums things like 
So when one tries to go with a different notion of convergence, one must be extra cautious as to which operations in the domain space carry through under the “assignment morphism” and what the “equivalence classes” of a given series are (e. g. can a series be deranged and keep the same sum?)
This Phil Plait article started this post in motion for me and I got to it via 3-quarks daily.
I was blogging about the topic of how “classroom knowledge” turns into “walking around knowledge” and came across an “elementary physics misconceptions” webpage at the University of Montana. It is fun, but it helped me realize how easy things can be when one thinks mathematically.

This becomes very easy if one does a bit of mathematics. Let 






Let’s look at another example:

So what is going on? Force 


These problems are easier with mathematics, aren’t they? 🙂
Via Jerry Coyne’s website; you’ll see some great comments there.
Watch standing waves in action:
Here is what is going on; the particles collect at the “stationary” points.
This is an excellent reason to take a course that deals with Fourier Series!
Here is an example of a projection, and what happens when you take the image and move it a little.
This is a fun little post about the interplay between physics, mathematics and statistics (Brownian Motion)
Here is a teaser video:
The article itself has a nice animation showing the effects of a Poisson process: one will get some statistical clumping in areas rather than uniform spreading.
Treat yourself to the whole article; it is entertaining.
The purpose of this note is to give a bit of direction to the perplexed student.
I am not going to go into all the possible uses of eigenvalues, eigenvectors, eigenfuntions and the like; I will say that these are essential concepts in areas such as partial differential equations, advanced geometry and quantum mechanics:
Quantum mechanics, in particular, is a specific yet very versatile implementation of this scheme. (And quantum field theory is just a particular example of quantum mechanics, not an entirely new way of thinking.) The states are “wave functions,” and the collection of every possible wave function for some given system is “Hilbert space.” The nice thing about Hilbert space is that it’s a very restrictive set of possibilities (because it’s a vector space, for you experts); once you tell me how big it is (how many dimensions), you’ve specified your Hilbert space completely. This is in stark contrast with classical mechanics, where the space of states can get extraordinarily complicated. And then there is a little machine — “the Hamiltonian” — that tells you how to evolve from one state to another as time passes. Again, there aren’t really that many kinds of Hamiltonians you can have; once you write down a certain list of numbers (the energy eigenvalues, for you pesky experts) you are completely done.
(emphasis mine).
So it is worth understanding the eigenvector/eigenfunction and eigenvalue concept.
First note: “eigen” is German for “self”; one should keep that in mind. That is part of the concept as we will see.
The next note: “eigenfunctions” really are a type of “eigenvector” so if you understand the latter concept at an abstract level, you’ll understand the former one.
The third note: if you are reading this, you are probably already familiar with some famous eigenfunctions! We’ll talk about some examples prior to giving the formal definition. This remark might sound cryptic at first (but hang in there), but remember when you learned 


The basic concept of eigenvectors (eigenfunctions) and eigenvalues is really no more complicated than that. Let’s do another one from calculus:
the function 



Answer: 
So hopefully you are seeing the basic idea: we have a collection of objects called vectors (can be traditional vectors or abstract ones such as differentiable functions) and an operator (linear transformation) that acts on these objects to yield a new object. In our example, the vectors were differentiable functions, and the operators were the derivative operators (the thing that “takes the derivative of” the function). An eigenvector (eigenfunction)-eigenvalue pair for that operator is a vector (function) that is transformed to a scalar multiple of itself by the operator; e. g., the derivative operator takes 
Formal Definition
We will give the abstract, formal definition. Then we will follow it with some examples and hints on how to calculate.
First we need the setting. We start with a set of objects called “vectors” and “scalars”; the usual rules of arithmetic (addition, multiplication, subtraction, division, distributive property) hold for the scalars and there is a type of addition for the vectors and scalars and the vectors “work together” in the intuitive way. Example: in the set of, say, differentiable functions, the scalars will be real numbers and we have rules such as 
![[a, b, c]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%2C+c%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we need a linear transformation, which is sometimes called a linear operator. A linear transformation (or operator) is a function 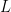


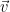
Common linear transformations (and there are many others!) and their eigenvectors and eigenvalues.
Consider the vector space of two-dimensional vectors with real numbers as scalars. We can create a linear transformation by matrix multiplication:
![L([x,y]^T) = \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} ax+ by \\ cx+dy \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+a+%26+b+%5C%5C+c+%26+d+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+ax%2B+by+%5C%5C+cx%2Bdy+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002)
![[x,y]^T](https://s0.wp.com/latex.php?latex=%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002)
It is easy to check that the operation of matrix multiplying a vector on the left by an appropriate matrix is yields a linear transformation.
Here is a concrete example:
So, does this linear transformation HAVE non-zero eigenvectors and eigenvalues? (not every one does).
Let’s see if we can find the eigenvectors and eigenvalues, provided they exist at all.
For ![L([x,y]^T) = \lambda [x,y]^T](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Clambda+%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002)
So, using the matrix we get: ![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]= \lambda \left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
At this point it is tempting to try to use a distributive law to factor out ![\left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Notice that by doing this, we haven’t changed anything except now we can factor out that vector; this would leave:
Which leads to:
Now we use a fact from linear algebra: if 


Now to find the associated eigenvectors: if we start with 
![(\left[ \begin{array}{cc} 0 & 2 \\ 0 & 2 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+2+%5C%5C+0+%26+2+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
If we next try 
![(\left[ \begin{array}{cc} -2 & 2 \\ 0 & 0 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+-2+%26+2+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
In the general “k-dimensional vector space” case, the recipe for finding the eigenvectors and eigenvalues is the same.
1. Find the matrix 
2. Form the matrix 
3. Note that 

4. Start with 


Practical note
Yes, this should work “in theory” but practically speaking, there are many challenges. For one: for equations of degree 5 or higher, it is known that there is no formula that will find the roots for every equation of that degree (Galios proved this; this is a good reason to take an abstract algebra course!). Hence one must use a numerical method of some sort. Also, calculation of the determinant involves many round-off error-inducing calculations; hence sometimes one must use sophisticated numerical techniques to get the eigenvalues (a good reason to take a numerical analysis course!)
Consider a calculus/differential equation related case of eigenvectors (eigenfunctions) and eigenvalues.
Our vectors will be, say, infinitely differentiable functions and our scalars will be real numbers. We will define the operator (linear transformation) 

We can also use these operators to form new operators; that is 
So, what does it mean to find eigenvectors and eigenvalues of such beasts?
Suppose we with to find the eigenvectors and eigenvalues of 
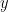









Of course, reading this little note won’t make you an expert, but it should get you started on studying.
I’ll close with a link on how these eigenfunctions and eigenvalues are calculated (in the context of solving a partial differential equation).
Suppose we are trying to solve the following partial differential equation:

It turns out that we will be using techniques from ordinary differential equations and concepts from linear algebra; these might be confusing at first.
The first thing to note is that this differential equation (the so-called heat equation) is known to satisfy a “uniqueness property” in that if one obtains a solution that meets the boundary criteria, the solution is unique. Hence we can attempt to find a solution in any way we choose; if we find it, we don’t have to wonder if there is another one lurking out there.
So one technique that is often useful is to try: let 
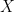
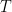
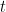

The next step is to note that the left hand side does NOT depend on
Hence we have 
So far, so good. But then you are told that
The thing to notice is that 
First, the equation in 



So in this sense, solving a homogeneous differential equation is really solving an eigenvector problem; often this is termed the “eigenfucntion” problem.
Note that the differential equations are not difficult to solve:


But the point is that we are merely solving a constant coefficient differential equation just as we did in our elementary differential equations course with one important difference: we don’t know what the constant (the eigenvalue) is.
Now if we turn to the boundary conditions on 

Hence we know that 

But now we notice that these solutions have a
So what values of 




Now we still need to meet the last condition (set at 

The coefficients are 
I feel a bit guilty as I haven’t gone over an example of how one might work out a problem. So here goes:
Suppose our potential function is some sort of energy well: 


Note: I am too lazy to keep writing 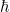
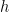
So, we have the two Schrödinger equations with 

Where 
Now apply the potential for
Yes, I know that equation II is a consequence of equation I.
Now we use a fact from partial differential equations: the first equation is really a form of the “diffusion” or “heat” equation; it has been shown that once one takes boundary conditions into account, the equation posses a unique solution. Hence if we find a solution by any means necessary, we don’t have to worry about other solutions being out there.
So attempt a solution of the form 
Now put into the second equation:
Now assume 
from our knowledge of elementary differential equations.
Now for 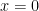


We want zero at 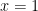


Now let’s look at the first Schrödinger equation:
This gives the equation:
Note: in partial differential equations, it is customary to note that the left side of the equation is a function of 


So our solution is 
This becomes 
Here are some graphs: we use 




Up to now, I’ve used mathematical notation for state vectors, inner products and operators. However, physicists use something called “Dirac” notation (“bras” and “kets”) which we will now discuss.
Recall: our vectors are integrable functions 

Our inner product is:
Here is the Dirac notation version of this:
A “ket” can be thought of as the vector 


Similarly there are the “bra” vectors which are “dual” to the “kets”; these are denoted by 



Now 
By convention: if 


This leads to the following: let 

Then 




![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} x+ 2y \\ 3y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x%2B+2y+%5C%5C+3y+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![(\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] )\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D++-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%29%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![(\left[ \begin{array}{cc} 1-\lambda & 2 \\ 0 & 3-\lambda \end{array} \right] ) \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1-%5Clambda+%26+2+%5C%5C+0+%26+3-%5Clambda+%5Cend%7Barray%7D+%5Cright%5D+%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)



















{kind=link}