In the first part of this series, we reviewed some of the mathematical background that we’ll use. Now we get into a bit of the physics.
For simplification, we’ll assume one dimensional, non-relativistic motion. No, nature isn’t that simple; that is why particle physics is hard! 🙂
What we will do is to describe a state of a system and the observables. The state of the system is hard to describe; in the classical case (say the damped mass-spring system in harmonic motion), the state of the system is determined by the system parameters (mass, damping constant, spring constant) and the velocity and acceleration at a set time.
And observable is, roughly speaking, something that can give us information about the state of the system. In classical mechanics, one observable might be  where
where 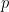 is the system’s momentum and
is the system’s momentum and  represents the potential energy at position
represents the potential energy at position  . If this seems strange, remember that
. If this seems strange, remember that  therefore kinetic energy is
therefore kinetic energy is  and solving for momentum gives us the formula. We bring this up because something similar will appear later.
and solving for momentum gives us the formula. We bring this up because something similar will appear later.
In quantum mechanics, certain postulates are assumed. I’ll present the ones that Gillespie uses:
Postulate 1: Every possible physical state of a given system corresponds to a Hilbert space vector  of unit norm (using the inner product that we talked about) and every such vector corresponds to a possible state of a system. The correspondence of states to the vectors is well defined up to multiplication of a vector by a complex number of unit modulus.
of unit norm (using the inner product that we talked about) and every such vector corresponds to a possible state of a system. The correspondence of states to the vectors is well defined up to multiplication of a vector by a complex number of unit modulus.
Note: this state vector, while containing all of the knowable information of the system, says nothing about what could be known or how such knowledge might be observed. Of course, this state vector might evolve with time and sometimes it is written as  for this reason.
for this reason.
Postulate 2 There is a one to one correspondence between physical observables and linear Hermitian operators  , each of which possesses a complete, orthonormal set of eigenvectors
, each of which possesses a complete, orthonormal set of eigenvectors  and a corresponding set of real eigenvalues
and a corresponding set of real eigenvalues  and the only possible values of any measurement of this observable is one of these eigenvalues.
and the only possible values of any measurement of this observable is one of these eigenvalues.
Note: in the cases when the eigenvalues are discretely distributed (e. g., the eigenvalues fail to have a limit point), we get “quantized” behavior from this observable.
We’ll use observables with discrete eigenvalues unless we say otherwise.
Now: is a function of an observable itself an observable? The answer is “yes” if the function is real analytic and we assume that  . To see this: assume that
. To see this: assume that  and note that if is an observable operator then so is
and note that if is an observable operator then so is  for all
for all  . Note: one can do this by showing that the eigenvectors for
. Note: one can do this by showing that the eigenvectors for  do not change and that the eigenvalues merely go up by power. The completeness of the eigenvectors imply convergence when we pass to
do not change and that the eigenvalues merely go up by power. The completeness of the eigenvectors imply convergence when we pass to  .
.
Now we have states and observables. But how do they interact?
Remember that we showed the following:
Let be a linear operator with a complete orthonormal eigenbasis  and corresponding real eigenvalues . Let be an element of the Hilbert space with unit norm and let
and corresponding real eigenvalues . Let be an element of the Hilbert space with unit norm and let  .
.
Then the function  is a probability density function. (note:
is a probability density function. (note:  ).
).
This will give us exactly what we need! Basically, if the observable has operator system and is in state , then the probability of a measurement yielding a result of is  Note: it follows that if the state
Note: it follows that if the state  then the probability of obtaining is exactly one.
then the probability of obtaining is exactly one.
We summarize this up by Postulate 3: (page 49 of Gillespie, stated for the “scattered eigenvalues” case):
Postulate 3: If an observable operator has eigenbasis with eigenvalues and if the corresponding observable is measured on a system which, immediately prior to the measurement is in state then the strongest predictive statement that can be made concerning the result of this measurement is as follows: the probability that the measurement will yield  is .
is .
Note: for simplicity, we are restricting ourselves to observables which have distinct eigenvalues (e. g., no two linearly independent eigenvectors have the same eigenvalues). In real life, some observables DO have different eigenvectors with the same eigenvalue (example from calculus; these are NOT Hilbert Space vectors, but if the operator is  then
then  and
and  both have eigenvalue -1. )
both have eigenvalue -1. )
Where we are now: we have a probability distribution to work with which means that we can calculate an expected value and a variance. These values will be fundamental when we tackle uncertainty principles!
Just a reminder from our courses in probability theory: if  is a random variable with density function
is a random variable with density function 
 and
and  .
.
So with our density function (we use to save space), then if  is the expected observed value of the observable (the expected value of the eigenvalues):
is the expected observed value of the observable (the expected value of the eigenvalues):
 . But this quantity can be calculated in another way:
. But this quantity can be calculated in another way:
 . Yes, I skipped some easy steps.
. Yes, I skipped some easy steps.
Using this we find  and it is customary to denote the standard deviation
and it is customary to denote the standard deviation 
In our next installment, I give an illustrative example.
In a subsequent installment, we’ll show how a measurement of an observable affects the state and later how the distribution of the observable changes with time.





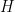



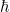

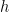
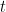












 . We assume some state vector
. We assume some state vector  given state vector
given state vector 
 we get:
we get:  which is how it is often stated.
which is how it is often stated.  and
and  ; note that
; note that  . The following are routine exercises:
. The following are routine exercises: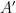 and
and  are Hermitian
are Hermitian
 .
.


 . The assumption is that these observations are made so quickly that no time evolution of the state vector can take place; all of the change to the state vector will be due to the effect of the observations.
. The assumption is that these observations are made so quickly that no time evolution of the state vector can take place; all of the change to the state vector will be due to the effect of the observations. are compatible if, upon three successive measurements
are compatible if, upon three successive measurements  for
for  just prior to the first measurement. Then the first measurement is
just prior to the first measurement. Then the first measurement is  which means the system is in state
which means the system is in state 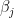 , in which case the third measurement is guaranteed to be
, in which case the third measurement is guaranteed to be  . An argument about completeness and orthogonality finishes the proof of this implication.
. An argument about completeness and orthogonality finishes the proof of this implication.  which implies that
which implies that  is an eigenvector for
is an eigenvector for  where
where  has unit modulus; hence
has unit modulus; hence  of observing eigenvalue
of observing eigenvalue 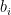 . Now
. Now  of observing eigenvalue
of observing eigenvalue  in the second measurement of observable
in the second measurement of observable 
![V(A)V(B) \geq (1/4)|\langle \psi, [AB-BA]\psi \rangle |^2.](https://s0.wp.com/latex.php?latex=V%28A%29V%28B%29+%5Cgeq+%281%2F4%29%7C%5Clangle+%5Cpsi%2C+%5BAB-BA%5D%5Cpsi+%5Crangle+%7C%5E2.++&bg=ffffff&fg=000000&s=0&c=20201002)
 for all possible state vectors
for all possible state vectors  .
.![[-\pi, \pi]](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C+%5Cpi%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and let our “state vector”
and let our “state vector” 
 so our new state vector is
so our new state vector is  . These polynomials obey the orthogonality relation
. These polynomials obey the orthogonality relation  hence
hence  .
.
 and multiply each polynomial
and multiply each polynomial  by the factor
by the factor  to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule.
to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule. denote the adjusted Legendre polynomial with eigenvalue
denote the adjusted Legendre polynomial with eigenvalue  .
. is observed as an observable with the Lengendre operator; this corresponds to eigenvector
is observed as an observable with the Lengendre operator; this corresponds to eigenvector  which is now the new state vector.
which is now the new state vector. and
and  with eigenvalues
with eigenvalues  (note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).
(note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).  as required for an orthonormal basis with this inner product.
as required for an orthonormal basis with this inner product. 




 .
.  (complex valued functions of a real variable) for which
(complex valued functions of a real variable) for which  is finite. Note: the square root of a probability density function is a vector of this vector space. Scalars are complex numbers and the operation is the usual function addition.
is finite. Note: the square root of a probability density function is a vector of this vector space. Scalars are complex numbers and the operation is the usual function addition.  has the following type of symmetry:
has the following type of symmetry:  and
and  .
.  It is an easy exercise to see that such a linear transformation can only have real eigenvalues. We will also be interested in the subset (NOT a vector subspace) of vectors
It is an easy exercise to see that such a linear transformation can only have real eigenvalues. We will also be interested in the subset (NOT a vector subspace) of vectors  .
. then we say that
then we say that 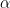 . If there is a countable number of orthornormal eigenvectors whose “span” (allowing for infinite sums) includes every element of the vector space, then we say that
. If there is a countable number of orthornormal eigenvectors whose “span” (allowing for infinite sums) includes every element of the vector space, then we say that  and expand
and expand  in terms of the eigenbasis; of course the linear operator
in terms of the eigenbasis; of course the linear operator  is the complete set of eigenvectors for
is the complete set of eigenvectors for  and
and 

 to not be square integrable.
to not be square integrable.  .
.  ).
). follows easily from the Cauchy-Schwartz inequality. Also note that
follows easily from the Cauchy-Schwartz inequality. Also note that 
