Reminder: this series is NOT for the student who is attempting to learn calculus for the first time.
Derivatives This is dealing with differentiable functions  and no, I will NOT be talking about maps between tangent bundles. Yes, my differential geometry and differential topology courses were on the order of 30 years ago or so. 🙂
and no, I will NOT be talking about maps between tangent bundles. Yes, my differential geometry and differential topology courses were on the order of 30 years ago or so. 🙂
In calculus 1, we typically use the following definitions for the derivative of a function at a point:  . This is opposed to the derivative function which can be thought of as the one dimensional gradient of
. This is opposed to the derivative function which can be thought of as the one dimensional gradient of  .
.
The first definition is easier to use for some calculations, say, calculating the derivative of  at a point. (hint, if you need one: use
at a point. (hint, if you need one: use  then it is easier to factor). It can be used for proving a special case of the chain rule as well (the case there we are evaluating at
then it is easier to factor). It can be used for proving a special case of the chain rule as well (the case there we are evaluating at  and
and  for at most a finite number of points near
for at most a finite number of points near  .)
.)
When introducing this concept, the binomial expansion theorem is very handy to use for many of the calculations.
Now there is another definition for the derivative that is helpful when proving the chain rule (sans restrictions).
Note that as  we have
we have  . We can now view
. We can now view  as a function of
as a function of 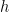 which goes to zero as does.
which goes to zero as does.
That is,  where
where  and
and  is the best linear approximation for at .
is the best linear approximation for at .
We’ll talk about the chain rule a bit later.
But what about the derivative and examples?
It is common to develop intuition for the derivative as applied to nice, smooth..ok, analytic functions. And this might be a fine thing to do for beginning calculus students. But future math majors might benefit from being exposed to just a bit more so I’ll give some examples.
Now, of course, being differentiable at a point means being continuous there (the limit of the numerator of the difference quotient must go to zero for the derivative to exist). And we all know examples of a function being continuous at a point but not being differentiable there. Examples:  are all continuous at zero but none are differentiable there; these give examples of a corner, vertical tangent and a cusp respectively.
are all continuous at zero but none are differentiable there; these give examples of a corner, vertical tangent and a cusp respectively.
But for many of the piecewise defined examples, say,  for
for  and
and  for
for 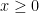 the derivative fails to exist because the respective derivative functions fail to be continuous at
the derivative fails to exist because the respective derivative functions fail to be continuous at  ; the same is true of the other stated examples.
; the same is true of the other stated examples.
And of course, we can show that  has
has  continuous derivatives at the origin but not
continuous derivatives at the origin but not  derivatives.
derivatives.
But what about a function with a discontinuous derivative? Try  for
for  and zero at . It is easy to see that the derivative exists for all
and zero at . It is easy to see that the derivative exists for all  but the first derivative fails to be continuous at the origin.
but the first derivative fails to be continuous at the origin.
The derivative is 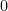 at
at 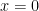 and
and  for which is not continuous at the origin.
for which is not continuous at the origin.
Ok, what about a function that is differentiable at a single point only? There are different constructions, but if  for rational,
for rational,  for irrational is both continuous and, yes, differentiable at (nice application of the Squeeze Theorem on the difference quotient).
for irrational is both continuous and, yes, differentiable at (nice application of the Squeeze Theorem on the difference quotient).
Yes, there are everywhere continuous, nowhere differentiable functions.


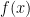






 which transforms this to the dreaded
which transforms this to the dreaded  integral, which is a double integration by parts.
integral, which is a double integration by parts.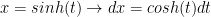 so upon substituting we obtain
so upon substituting we obtain  and noting that
and noting that  alaways:
alaways: Now this can be integrated by parts: let
Now this can be integrated by parts: let 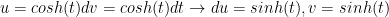
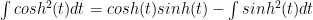 but this easily reduces to:
but this easily reduces to: 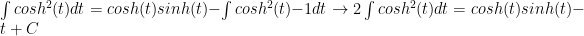


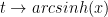 ?
? 
 to get
to get  and use the quadratic formula to get
and use the quadratic formula to get 
 so
so 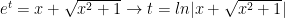 and that is our integral:
and that is our integral: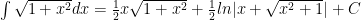
 and you are told to calculate the derivative?
and you are told to calculate the derivative? 



 only after simplifying ..which one might see as a limit process.
only after simplifying ..which one might see as a limit process. and then took the log of both sides. Where is the log defined? And when does
and then took the log of both sides. Where is the log defined? And when does  ? You got it: this only works when
? You got it: this only works when  .
. is justified only when each
is justified only when each  .
. is a differentiable function then
is a differentiable function then 
 material but here goes: write
material but here goes: write 
 we get
we get  as usual. If
as usual. If  then
then  and so in either case:
and so in either case: where
where  : just calculate
: just calculate  . noting that
. noting that 
 ?
? is a product of differentiable functions and
is a product of differentiable functions and 
 then
then
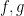 are differentiable and
are differentiable and  . Then
. Then  and
and 
 . Then
. Then  and
and 
 then
then  by inductive application of 1.
by inductive application of 1.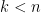 then let
then let  as in 2. Then by 2, we have
as in 2. Then by 2, we have  Now this quantity is zero unless
Now this quantity is zero unless  and
and  . But in this case note that
. But in this case note that 
 . That is all well and good.
. That is all well and good. only makes sense when
only makes sense when  by using logarithmic differentiation,
by using logarithmic differentiation, 
 , etc.
, etc. 
 and that expansion is valid only for
and that expansion is valid only for because we need
because we need  and
and  .
. where
where  is differentiable, then
is differentiable, then  and verifying this is an easy exercise in induction.
and verifying this is an easy exercise in induction.  where it is essential that
where it is essential that 

 some constant. Then
some constant. Then  and the formula becomes
and the formula becomes  which is just the usual constant power rule with the chain rule.
which is just the usual constant power rule with the chain rule. for some positive constant. Then
for some positive constant. Then 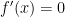 and the formula becomes
and the formula becomes  which is the usual exponential function differentiation formula combined with the chain rule.
which is the usual exponential function differentiation formula combined with the chain rule. and then use, say, the implicit function theorem or perhaps the chain rule.
and then use, say, the implicit function theorem or perhaps the chain rule.  And yes, one way to do this is to simplify the difference quotient
And yes, one way to do this is to simplify the difference quotient  by factoring
by factoring  from both the numerator and the denominator of the difference quotient. But this is rather ad-hoc, I think.
from both the numerator and the denominator of the difference quotient. But this is rather ad-hoc, I think. where
where  are positive integers?
are positive integers?  and do the following (before attempting a limit, of course): let
and do the following (before attempting a limit, of course): let  at which our difference quotient becomes:
at which our difference quotient becomes: 
 is a common factor..but HOW it factors is essential.
is a common factor..but HOW it factors is essential.
 (hint: very much like the geometric sum proof).
(hint: very much like the geometric sum proof). Now as
Now as  we have
we have  (for the purposes of substitution) so we end up with:
(for the purposes of substitution) so we end up with: (the number of terms is easy to count).
(the number of terms is easy to count). which, of course, is the familiar formula.
which, of course, is the familiar formula.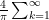
 yields the “square wave” function (plus zero at the jump discontinuities)
yields the “square wave” function (plus zero at the jump discontinuities) 


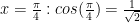


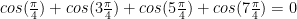
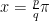 where
where 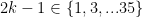

 as a type of “envelope function”)
as a type of “envelope function”)

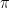 ). But SOMETHING is going on!
). But SOMETHING is going on!

 and we can somehow get close to
and we can somehow get close to  for given values of
for given values of  where
where 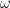 is some point in the interval.
is some point in the interval. .
.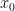 or using the Lagrange polynomial through the given points and differentiating.
or using the Lagrange polynomial through the given points and differentiating. . Now use the three point derivative estimates on the following functions:
. Now use the three point derivative estimates on the following functions: .
. .
. . It is easy to see why.
. It is easy to see why.

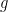 , the degree that
, the degree that  wanders away from
wanders away from  where
where  is some number in
is some number in ![[x_0 -h, x_0 + h]](https://s0.wp.com/latex.php?latex=%5Bx_0+-h%2C+x_0+%2B+h%5D+&bg=ffffff&fg=000000&s=0&c=20201002) ; of course we assume that the third derivative is continuous in this interval.
; of course we assume that the third derivative is continuous in this interval. and differentiate or one can use the degree 2 Taylor polynomial expanded about
and differentiate or one can use the degree 2 Taylor polynomial expanded about  and use
and use  and solve for
and solve for  ; of course one runs into some issues with the remainder term if one uses the Taylor method.
; of course one runs into some issues with the remainder term if one uses the Taylor method. but rather
but rather  where
where  where
where  is the round off error used in calculating the function at
is the round off error used in calculating the function at  and the magnitude of the actual error is bounded by
and the magnitude of the actual error is bounded by  where
where  on some small neighborhood of
on some small neighborhood of  .
. .
.  and then do some experimentation to determine
and then do some experimentation to determine  (a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for
(a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for  ; of course
; of course  and
and  is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of
is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of  respectively. In the first case, use
respectively. In the first case, use 

 ; the same sort of thing appears to happen for
; the same sort of thing appears to happen for  ; it is roughly
; it is roughly  at
at  .
. instead; something interesting happens in the
instead; something interesting happens in the  scale by doing the following (approximating
scale by doing the following (approximating  for
for 
 . The graph looks like:
. The graph looks like:
 axis: let
axis: let  and run plot(N, LE):
and run plot(N, LE):
 , which is the same as EXCEL.
, which is the same as EXCEL.
 if
if  where
where  .
. 
 be given and choose a positive integer
be given and choose a positive integer  . Let
. Let  . Now if
. Now if  and
and  .
. and
and  .
.  ,
,  .
.