One of the many good things about my teaching career is that as I teach across the curriculum, I fill in the gaps of my own education.
I got my Ph. D. in topology (low dimensional manifolds; in particular, knot theory) and hadn’t seen much of differential equations beyond my “engineering oriented” undergraduate course.
Therefore, I learned more about existence and uniqueness theorems when I taught differential equations; though I never taught the existence and uniqueness theorems in a class, I learned the proofs just for my own background. In doing so I learned about the Picard iterated integral technique for the first time; how this is used to establish “uniqueness of solution” can be found here.
However I recently discovered (for myself) what thousands of mathematicians already know: the Picard process can be used to yield an interval of existence for a solution for a differential equation, even if we cannot obtain the solution in closed form.
The situation
I assigned my numerical methods class to solve  with
with  and to produce the graph of
and to produce the graph of 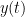 from
from  to
to  .
.
There is a unique solution to this and the solution is valid so long as the  and
and  value of the solution curve stays finite; note that
value of the solution curve stays finite; note that 
So, is it possible that the values for this solution become unbounded?
Answer: yes.
What follows are the notes I gave to my class.
Numeric output seems to indicate this, but numeric output is NOT proof.
To find a proof of this, let’s turn to the Picard iteration technique. We
know that the Picard iterates will converge to the unique solution.




The integrals get pretty ugly around here; I used MATLAB to calculate the
higher order iterates. I’ll show you 

where  means assorted polynomial terms from order 6 to 11.
means assorted polynomial terms from order 6 to 11.
Here is one more:

We notice some patterns developing here. First of all, the coefficient of
the  term is staying the same for all
term is staying the same for all  where
where 
That is tedious to prove. But what is easier to show (and sufficient) is
that the coefficients for the terms for  all appear to be
all appear to be
bigger than 1. This is important!
Why? If we can show that this is the case, then our ”limit” solution  will have an interval of convergence less than 1. Why? Substitute
will have an interval of convergence less than 1. Why? Substitute  and see that the sum
and see that the sum
diverges because the  not only fail to converge to zero, but they
not only fail to converge to zero, but they
stay greater than 1.
So, can we prove this general pattern?
YES!
Here is the idea:  where
where  is a polynomial of order
is a polynomial of order 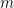
and  is a polynomial whose terms all have order
is a polynomial whose terms all have order  or greater.
or greater.
Now put into the Picard process:


Note: all of the terms of  of degree
of degree  or higher must come from
or higher must come from
the second integral.
Now by induction we can assume that all of the coefficients of the
polynomial 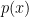 are greater than or equal to one.
are greater than or equal to one.
When we ”square out” the polynomial, the coefficients of the new
polynomial will consist of the sum of positive numbers, each of which is
greater than 1. For the coefficients of the polynomial  of
of
degree  or higher: if one is interested in the
or higher: if one is interested in the 
coefficient, one has to add at least 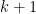 numbers together, each of which
numbers together, each of which
is bigger than one.
Now when one does the integration on these particular terms, one, of course,
divides by  (power rule for integration). But that means that the
(power rule for integration). But that means that the
coefficient (after integration) is then greater than 1.
Here is a specific example:
Say 
Now 
Remember that 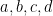 are all greater than or equal to one.
are all greater than or equal to one.
Now 
Now when we integrate term by term, we get:

But note that  and
and 
Since all of the factors are greater than or equal to 1.
Hence in our new polynomial approximation, the order 4 terms or less all
have coefficients which are greater than or equal to one.
We can make this into a Proposition:
Proposition
Suppose  where each
where each 
If 
Then for all 
Proof. Of course,  and
and 
Let 
Then we can calculate: (since all of the  are
are
defined):
If  is odd, then
is odd, then 
If is even then 
The Proposition is proved.
Of course, this possibly fails for  where
where  as we would fail to
as we would fail to
have a sufficient number of terms in our sum.
Now if one wants a challenge, one can modify the above arguments to show that the coefficients of the approximating polynomial never get ”too big”; that is, the coefficient of the  order term is less than, say,
order term is less than, say,  .
.
It isn’t hard to show that  where
where 
Then one can compare to the derivative of the geometric series to show that
one gets convergence on an interval up to but not including 1.




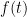


 ,
,  for
for 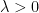 . Example:
. Example:  . Note that the solution
. Note that the solution  decays very quickly to zero though the differential equation is 20 times larger.
decays very quickly to zero though the differential equation is 20 times larger.  which becomes
which becomes  . There is a way of assigning a method to a polynomial; in this case the polynomial is
. There is a way of assigning a method to a polynomial; in this case the polynomial is  and if the roots of this polynomial have modulus less than 1, then the method will converge. Well here, the root is
and if the roots of this polynomial have modulus less than 1, then the method will converge. Well here, the root is  and calculating:
and calculating:  which implies that
which implies that  . This
. This  we find that
we find that 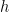 has to be less than
has to be less than  . And so I ran Euler’s method for the initial problem on
. And so I ran Euler’s method for the initial problem on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and showed that the solution diverged wildly for using 9 intervals, oscillated back and forth (with equal magnitudes) for using 10 intervals, and slowly converged for using 11 intervals. It is just plain fun to see the theory in action.
and showed that the solution diverged wildly for using 9 intervals, oscillated back and forth (with equal magnitudes) for using 10 intervals, and slowly converged for using 11 intervals. It is just plain fun to see the theory in action.![[1, 1.2]](https://s0.wp.com/latex.php?latex=%5B1%2C+1.2%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and the initial step size was….
and the initial step size was….  and what is 5 times .05? Yep, the correction part overshot the right endpoint and the “next h” was indeed negative.
and what is 5 times .05? Yep, the correction part overshot the right endpoint and the “next h” was indeed negative.  one selects a step size
one selects a step size  and then one rides the slope of the tangent line:
and then one rides the slope of the tangent line:  and repeat the process. This is the basic Euler method; one can do an averaging process to get a better slope (Runge-Kutta) and one, if one desires, can use previous points in a multi-step process (e. g. Adams-Bashforth, etc.). Ultimately, it is starting at a point and using the slope at that point to get a piece wise linear approximation to a solution curve.
and repeat the process. This is the basic Euler method; one can do an averaging process to get a better slope (Runge-Kutta) and one, if one desires, can use previous points in a multi-step process (e. g. Adams-Bashforth, etc.). Ultimately, it is starting at a point and using the slope at that point to get a piece wise linear approximation to a solution curve.
 columns, is the approximate solution…a piece wise approximation of one anyway. What we have is a set
columns, is the approximate solution…a piece wise approximation of one anyway. What we have is a set  where these ordered pairs are points in the approximate solution to the differential equation that runs through those points. One cannot assume that the students understand this, even when they can do the algorithm.
where these ordered pairs are points in the approximate solution to the differential equation that runs through those points. One cannot assume that the students understand this, even when they can do the algorithm.
 and I got the following output.
and I got the following output. is an equilibrium solution and that this differential equation meets the “existence and uniqueness” criteria everywhere; hence the graph of the proposed solution intersecting the equilibrium solution is impossible.
is an equilibrium solution and that this differential equation meets the “existence and uniqueness” criteria everywhere; hence the graph of the proposed solution intersecting the equilibrium solution is impossible.  , the new slope it picked up was a near zero slope from the RK approximation for the same value of
, the new slope it picked up was a near zero slope from the RK approximation for the same value of 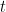 (which was near, but below the
(which was near, but below the  and gave them the phrase: “hint: THINK first; this is NOT a hard calculation”. A few students got it, but mostly the A students. There was ONE D student who got it right!
and gave them the phrase: “hint: THINK first; this is NOT a hard calculation”. A few students got it, but mostly the A students. There was ONE D student who got it right! 