
April 16, 2023
April 11, 2023
Annoying calculations in Statistics: correlation coefficient is always between -1 and 1.
Yes, I misspelled “Cauchy-Schwarz” in the video.

March 26, 2023


March 11, 2023
Annoying calculations: Binomial Distribution
Here, we derive the expectation, variance, and moment generating function for the binomial distribution.
Video, when available, will be posted below.

Why the binomial coefficients are integers
The video, when ready, will be posted below.


August 23, 2021
Vaccine efficacy wrt Hospitalization
I made a short video; no, I did NOT have “risk factor”/”age group” breakdown, but the overall point is that vaccines, while outstanding, are NOT a suit of perfect armor.
Upshot: I used this local data:

The vaccination rate of the area is slightly under 50 percent; about 80 percent for the 65 and up group. But this data doesn’t break it down among age groups so..again, this is “back of the envelope”:


Again, the efficacy is probably better than that because of the lack of risk factor correction.
Note: the p-value for the statistical test of 

The video:
April 5, 2019
Bayesian Inference: what is it about? A basketball example.
Let’s start with an example from sports: basketball free throws. At a certain times in a game, a player is awarded a free throw, where the player stands 15 feet away from the basket and is allowed to shoot to make a basket, which is worth 1 point. In the NBA, a player will take 2 or 3 shots; the rules are slightly different for college basketball.
Each player will have a “free throw percentage” which is the number of made shots divided by the number of attempts. For NBA players, the league average is .672 with a variance of .0074.
Now suppose you want to determine how well a player will do, given, say, a sample of the player’s data? Under classical (aka “frequentist” ) statistics, one looks at how well the player has done, calculates the percentage (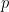
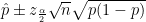
\
Yes, I know..for someone who has played a long time, one has career statistics ..so imagine one is trying to extrapolate for a new player with limited data.
That seems straightforward enough. But what if one samples the player’s shooting during an unusually good or unusually bad streak? Example: former NBA star Larry Bird once made 71 straight free throws…if that were the sample, 
Classical frequentist statistics doesn’t offer a way out but Bayesian Statistics does.
This is a good introduction:
But here is a simple, “rough and ready” introduction. Bayesian statistics uses not only the observed sample, but a proposed distribution for the parameter of interest (in this case, p, the probability of making a free throw). The proposed distribution is called a prior distribution or just prior. That is often labeled 
Since we are dealing with what amounts to 71 Bernoulli trials where p = .672 so the distribution of each random variable describing the outcome of each individual shot has probability mass fuction 


Our goal is to calculate what is known as a posterior distribution (or just posterior) which describes 

How we go about it: use the principles of joint distributions, likelihood functions and marginal distributions to calculate 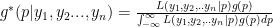
The denominator “integrates out” p to turn that into a marginal; remember that the 

What works well is to use the beta distribution for the prior. Note: the pdf is 




Now look at the numerator which consists of the product of a likelihood function and a density function: up to constant 

The denominator: same thing, but

So, in effect, we have 

So, I will spare you the calculation except to say that that the NBA prior with 

Now the update: 
What does this look like? (I used this calculator)

That is the prior. Now for the posterior:

Yes, shifted to the right..very narrow as well. The information has changed..but we avoid the absurd contention that 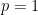
We can now calculate a “credible interval” of, say, 90 percent, to see where

And note that 
March 16, 2019
The beta function integral: how to evaluate them
My interest in “beta” functions comes from their utility in Bayesian statistics. A nice 78 minute introduction to Bayesian statistics and how the beta distribution is used can be found here; you need to understand basic mathematical statistics concepts such as “joint density”, “marginal density”, “Bayes’ Rule” and “likelihood function” to follow the youtube lecture. To follow this post, one should know the standard “3 semesters” of calculus and know what the gamma function is (the extension of the factorial function to the real numbers); previous exposure to the standard “polar coordinates” proof that 
So, what it the beta function? it is 




Now it turns out that the beta density function is defined as follows: 


I'll do this in two steps. Step one will convert the beta integral into an integral involving powers of sine and cosine. Step two will be to write 

Step one: converting the beta integral to a sine/cosine integral. Limit ![t \in [0, \frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+%5Cfrac%7B%5Cpi%7D%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)


Step two: transforming the product of two gamma functions into a double integral and evaluating using polar coordinates.
Write 
Now do the conversion 

From which we now obtain

Now we switch to polar coordinates, remembering the 


This splits into two integrals:

The first of these integrals is just 

The second integral: we just use 

And so the result follows.
That seems complicated for a simple little integral, doesn’t it?
March 14, 2019
Sign test for matched pairs, Wilcoxon Signed Rank test and Mann-Whitney using a spreadsheet
Our goal: perform non-parametric statistical tests for two samples, both paired and independent. We only assume that both samples come from similar distributions, possibly shifted.
I’ll show the steps with just a bit of discussion of what the tests are doing; the text I am using is Mathematical Statistics (with Applications) by Wackerly, Mendenhall and Scheaffer (7’th ed.) and Mathematical Statistics and Data Analysis by John Rice (3’rd ed.).
First the data: 56 students took a final exam. The professor gave some questions and a committee gave some questions. Student performance was graded and the student performance was graded as a “percent out of 100” on each set of questions (committee graded their own questions, professor graded his questions).
The null hypothesis: student performance was the same on both sets of questions. Yes, this data was close enough to being normal that a paired t-test would have been appropriate and one was done for the committee. But because I am teaching a section on non-parametric statistics, I decided to run a paired sign test and a Wilcoxon signed rank test (and then, for the heck of it, a Mann-Whitney test which assumes independent samples..which these were NOT (of course)). The latter was to demonstrate the technique for the students.
There were 56 exams and “pi” was the score on my questions, “pii” the score on committee questions. The screen shot shows a truncated view.

The sign test for matched pairs.
The idea behind this test: take each pair and score it +1 if sample 1 is larger and score it -1 if the second sample is larger. Throw out ties (use your head here; too many ties means we can’t reject the null hypothesis ..the idea is that ties should be rare).
Now set up a binomial experiment where 




This is easy to do in a spreadsheet. Just use the difference in rows:

Now use the “sign” function to return a +1 if the entry from sample 1 is larger, -1 if the entry from sample 2 is larger, or 0 if they are the same.

I use “copy, paste, delete” to store the data from ties, which show up very easily.

Now we need to count the number of “+1”. That can be a tedious, error prone process. But the “countif” command in Excel handles this easily.

Now it is just a matter of either using a binomial calculator or just using the normal approximation (I don’t bother with the continuity correction)

Here we reject the null hypothesis that the scores are statistically the same.
Of course, this matched pairs sign test does not take magnitude of differences into account but rather only the number of times sample 1 is bigger than sample 2…that is, only “who wins” and not “by what score”. Clearly, the magnitude of the difference could well matter.
That brings us to the Wilcoxon signed rank test. Here we list the differences (as before) but then use the “absolute value” function to get the magnitudes of such differences.

Now we need to do an “average rank” of these differences (throwing out a few “zero differences” if need be). By “average rank” I mean the following: if there are “k” entries between ranks n, n+1, n+2, ..n+k-1, then each of these gets a rank

(use 
Needless to say, this can be very tedious. But the “rank.avg” function in Excel really helps.
Example: rank.avg(di, $d$2:$d$55, 1) does the following: it ranks the entry in cell di versus the cells in d2: d55 (the dollar signs make the cell addresses “absolute” references, so this doesn’t change as you move down the spreadsheet) and the “1” means you rank from lowest to highest.

Now the test works in the following manner: if the populations are roughly the same, the larger or smaller ranked differences will each come from the same population roughly half the time. So we denote 

One easy way to tease this out: 





One can use a T table (this is a different T than “student T”) or one can use the normal approximation (if n is greater than, say, 25) with


How these are obtained: the expectation is merely the one half the sum of all the ranks (what one would expect if the distributions were the same) and the variance comes from 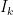


Here is a nice video describing the process by hand:
Mann-Whitney test
This test doesn’t apply here as the populations are, well, anything but independent, but we’ll pretend so we can crunch this data set.
Here the idea is very well expressed:
Do the following: label where the data comes from, and rank it all together. Then add the ranks of the population, of say, the first sample. If the samples are the same, the sums of the ranks should be the same for both populations.
Again, do a “rank average” and yes, Excel can do this over two different columns of data, while keeping the ranks themselves in separate columns.
And one can compare, using either column’s rank sum: the expectation would be 

Where this comes from: this is really a random sample of since 




So this is how it goes:


Note: I went ahead and ran the “matched pairs” t-test to contrast with the matched pairs sign test and Wilcoxon test, and the “two sample t-test with unequal variances” to contrast to the Mann-Whitney test..use the “unequal variances” assumption as the variance of sample pii is about double that of pi (I provided the F-test).



February 18, 2019
An easy fact about least squares linear regression that I overlooked
The background: I was making notes about the ANOVA table for “least squares” linear regression and reviewing how to derive the “sum of squares” equality:
Total Sum of Squares = Sum of Squares Regression + Sum of Squares Error or…
If 
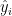


Now for each 

And it was going over the derivation of this that reminded me about an important fact about least squares that I had overlooked when I first presented it.
If you go in to the derivation and calculate:

Which equals 

But why?
Let’s go back to how the least squares equations were derived:
Given that 


Now 

That is, the sum of the residuals, weighted by the corresponding x values (inputs) is also zero. Note: this holds with multilinear regreassion as well.
Really, that is what the least squares process does: it sets the sum of the residuals and the sum of the weighted residuals equal to zero.
Yes, there is a linear algebra formulation of this.
Anyhow returning to our sum:


Now 

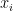
That was pretty easy, wasn’t it?
But the role that the basic least squares equations played in this derivation went right over my head!
