I am planning on writing up a series of notes from the out of print book A Quantum Mechanics Primer by Daniel Gillespie.
My background: mathematics instructor (Ph.D. research area: geometric topology) whose last physics course (at the Naval Nuclear Power School) was almost 30 years ago; sophomore physics was 33 years ago.
Therefore, corrections (or illuminations) from readers would be warmly received.
Your background: you teach undergraduate mathematics for a living and haven’t had a course in quantum mechanics; those who have the time to study a book such as Quantum Mechanics and the Particles of Nature by Anthony Sudbery would be better off studying that. Those who have had a course in quantum mechanics would be bored stiff.
Topics the reader should know: probability density functions, square integrability, linear algebra, (abstract inner products (Hermitian), eigenbasis, orthonormal basis), basic analysis (convergence of a series of functions) differential equations, dirac delta distribution.
My purpose: present some opportunities to present applications to undergraduate students e. g., “the dirac delta “function” (distribution really) can be thought of as an eigenvector for this linear transformation”, or “here is an application of non-standard inner products and an abstract vector space”, or “here is a non-data application to the idea of the expected value and variance of a probability density function”, etc.
Basic mathematical objects
Our vector space will consist of functions  (complex valued functions of a real variable) for which
(complex valued functions of a real variable) for which  is finite. Note: the square root of a probability density function is a vector of this vector space. Scalars are complex numbers and the operation is the usual function addition.
is finite. Note: the square root of a probability density function is a vector of this vector space. Scalars are complex numbers and the operation is the usual function addition.
Our inner product  has the following type of symmetry:
has the following type of symmetry:  and
and  .
.
Note: Our vector space will have a metric that is compatible with the inner product; such spaces are called Hilbert spaces. This means that we will allow for infinite sums of functions with some convergence; one might think of “convergence in the mean” which uses our inner product in the usual way to define the mean.
Of interest to us will be the Hermitian linear transformations 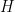 where
where  It is an easy exercise to see that such a linear transformation can only have real eigenvalues. We will also be interested in the subset (NOT a vector subspace) of vectors
It is an easy exercise to see that such a linear transformation can only have real eigenvalues. We will also be interested in the subset (NOT a vector subspace) of vectors  for which
for which  .
.
Eigenvalues and eigenvectors will be defined in the usual way: if  then we say that is an eigenvector for with associated eigenvalue
then we say that is an eigenvector for with associated eigenvalue 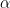 . If there is a countable number of orthornormal eigenvectors whose “span” (allowing for infinite sums) includes every element of the vector space, then we say that has a complete orthonormal eigenbasis.
. If there is a countable number of orthornormal eigenvectors whose “span” (allowing for infinite sums) includes every element of the vector space, then we say that has a complete orthonormal eigenbasis.
It is a good warm up exercise to show that if has a complete orthonormal eigenbasis then is Hermitian.
Hint: start with  and expand and
and expand and  in terms of the eigenbasis; of course the linear operator has to commute with the infinite sum so there are convergence issues to be concerned about.
in terms of the eigenbasis; of course the linear operator has to commute with the infinite sum so there are convergence issues to be concerned about.
The outline goes something like this: suppose  is the complete set of eigenvectors for with eigenvalues
is the complete set of eigenvectors for with eigenvalues  and
and  and
and 

Now do the same operation on the left side of the inner product and use the fact that the basis vectors are mutually orthogonal. Note: there are convergence issues here; those that relate the switching of the infinite sum notation outside of the inner product can be handled with a dominated convergence theorem for integrals. But the intuition taken from finite vector spaces works here.
The other thing to note is that not every Hermitian operator is “closed”; that is it is possible for to be square integrable but for operator  to not be square integrable.
to not be square integrable.
Probability Density Functions
Let be a linear operator with a complete orthonormal eigenbasis and corresponding real eigenvalues . Let be an element of the Hilbert space with unit norm and let  .
.
Claim: the function  is a probability density function. (note:
is a probability density function. (note:  ).
).
The fact that  follows easily from the Cauchy-Schwartz inequality. Also note that
follows easily from the Cauchy-Schwartz inequality. Also note that 
Yes, I skipped some steps that are easy to fill in. But the bottom line is that this density function now has a (sometimes) finite expected value and a (sometimes) finite variance.
With the mathematical preliminaries (mostly) out of the way, we are ready to see how this applies to physics.











![t \in [0, \frac{\pi}{2}]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2C+%5Cfrac%7B%5Cpi%7D%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002)














 though, of course, there is some choice in what
though, of course, there is some choice in what  is; any anti-derivative will do. Well, sort of.
is; any anti-derivative will do. Well, sort of. where
where  is the random variable that denotes the number of years longer a person aged
is the random variable that denotes the number of years longer a person aged  will live. Of course,
will live. Of course,  is a probability distribution function with density function
is a probability distribution function with density function  and if we assume that
and if we assume that 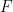 is smooth and
is smooth and  and, in principle this integral can be done by parts….but…if we use
and, in principle this integral can be done by parts….but…if we use  we have:
we have: which is a big problem on many levels. For one,
which is a big problem on many levels. For one,  and so the new integral does not converge..and the first term doesn’t either.
and so the new integral does not converge..and the first term doesn’t either.  we note that
we note that  is the survival function whose limit does go to zero, and there is usually the assumption that
is the survival function whose limit does go to zero, and there is usually the assumption that  as
as 
 which is one of the more important formulas.
which is one of the more important formulas.  and obtain measurement
and obtain measurement  regardless of what
regardless of what  as a measurement. Recall: remember all of those “orbitals” from chemistry class? Those were the energy levels of the electrons and the orbital level was a permissible energy state that we could obtain by a measurement.
as a measurement. Recall: remember all of those “orbitals” from chemistry class? Those were the energy levels of the electrons and the orbital level was a permissible energy state that we could obtain by a measurement.  .
.![[-\pi, \pi]](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C+%5Cpi%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and let our “state vector”
and let our “state vector” 
 so our new state vector is
so our new state vector is  . These polynomials obey the orthogonality relation
. These polynomials obey the orthogonality relation  hence
hence  .
.
 and multiply each polynomial
and multiply each polynomial  by the factor
by the factor  to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule.
to obtain an orthonormal eigenbasis. Of course, one has to adjust the operator by the chain rule. denote the adjusted Legendre polynomial with eigenvalue
denote the adjusted Legendre polynomial with eigenvalue  .
. is observed as an observable with the Lengendre operator; this corresponds to eigenvector
is observed as an observable with the Lengendre operator; this corresponds to eigenvector  which is now the new state vector.
which is now the new state vector.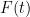 to a constant mass
to a constant mass  at time
at time  then one can define the impulse
then one can define the impulse  of
of 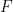 over an interval
over an interval ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002) by
by  where
where  is the velocity. So we can do a translation to set
is the velocity. So we can do a translation to set 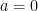 and then consider a unit impulse and vary
and then consider a unit impulse and vary  is; that is, define
is; that is, define
 is the force function that produces unit impulse for a given
is the force function that produces unit impulse for a given 
 (this is a great reason to introduce the concept of the limit of functions in a later course) and then argue that for all functions that are continuous over an interval containing 0,
(this is a great reason to introduce the concept of the limit of functions in a later course) and then argue that for all functions that are continuous over an interval containing 0, .
.
 and
and  such that
such that  Therefore as
Therefore as 
 by continuity. Therefore we can define the Laplace transform
by continuity. Therefore we can define the Laplace transform  ”
” (I can remember what
(I can remember what  and
and 


 with
with  .
.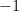 or,
or, and to do so instantly.
and to do so instantly.  for all
for all  by design, note that
by design, note that  fails to be continuous at
fails to be continuous at  . Clearly for all
. Clearly for all and
and  .
. ,
,  and
and  respectively.
respectively. 


![\frac{1}{\sigma \sqrt{2\pi }}\int_{0}^{\infty }\exp (-\frac{1}{2\sigma ^{2}}(t+\sigma ^{2}s)^{2})\exp (\frac{s^{2}\sigma^{2}}{2})dt=\exp (\frac{s^{2}\sigma ^{2}}{2})[\frac{1}{\sigma \sqrt{2\pi }}\int_{0}^{\infty }\exp (-\frac{1}{2\sigma ^{2}}(t+\sigma^{2}s)^{2})dt]](https://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B%5Csigma+%5Csqrt%7B2%5Cpi+%7D%7D%5Cint_%7B0%7D%5E%7B%5Cinfty+%7D%5Cexp+%28-%5Cfrac%7B1%7D%7B2%5Csigma+%5E%7B2%7D%7D%28t%2B%5Csigma+%5E%7B2%7Ds%29%5E%7B2%7D%29%5Cexp+%28%5Cfrac%7Bs%5E%7B2%7D%5Csigma%5E%7B2%7D%7D%7B2%7D%29dt%3D%5Cexp+%28%5Cfrac%7Bs%5E%7B2%7D%5Csigma+%5E%7B2%7D%7D%7B2%7D%29%5B%5Cfrac%7B1%7D%7B%5Csigma+%5Csqrt%7B2%5Cpi+%7D%7D%5Cint_%7B0%7D%5E%7B%5Cinfty+%7D%5Cexp+%28-%5Cfrac%7B1%7D%7B2%5Csigma+%5E%7B2%7D%7D%28t%2B%5Csigma%5E%7B2%7Ds%29%5E%7B2%7D%29dt%5D&bg=ffffff&fg=000000&s=0&c=20201002)

 for all
for all  . Note: assume
. Note: assume  and that
and that  is shorthand for the usual probability distribution function.
is shorthand for the usual probability distribution function.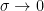 we get
we get 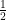 on the right hand side.
on the right hand side.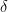 is as
is as  . This means that while
. This means that while is off by a factor of 2,
is off by a factor of 2, as desired.
as desired.  which is zero at
which is zero at 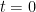 for all
for all  But the behavior of the derivative is interesting: the derivative is at its minimum at
But the behavior of the derivative is interesting: the derivative is at its minimum at  and at its maximum at
and at its maximum at  (as we tell our probability students: the standard deviation is the distance from the origin to the inflection points) and as
(as we tell our probability students: the standard deviation is the distance from the origin to the inflection points) and as  the inflection points get closer together and the second derivative at the
the inflection points get closer together and the second derivative at the which can be thought of as an instant drop from a positive velocity at
which can be thought of as an instant drop from a positive velocity at 
