In a previous post, I discussed the Legendre polynomials. We now know that if  is the n’th Legendre polynomial then:
is the n’th Legendre polynomial then:
1. If  .
.
2. If  has degree
has degree 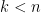 then
then 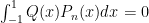 .
.
3. 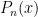 has n simple roots in
has n simple roots in  which are symmetric about 0.
which are symmetric about 0.
4. is an odd function if  is odd and an even function if is even.
is odd and an even function if is even.
5.  form an orthogonal basis for the vector pace of polynomials of degree or less.
form an orthogonal basis for the vector pace of polynomials of degree or less.
To make these notes complete, I’d like to review the Lagrange Interpolating polynomial:
Given a set of points  where the
where the 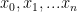 are all distinct, the Lagrange polynomial through these points (called “nodes”) is defined to be:
are all distinct, the Lagrange polynomial through these points (called “nodes”) is defined to be:
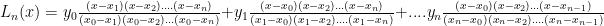
It is easy to see that  because the associated coefficient for the
because the associated coefficient for the  term is 1 and the other coefficients are zero. We call the coefficient polynomials
term is 1 and the other coefficients are zero. We call the coefficient polynomials 
It can be shown by differentiation that if  is a function that has
is a function that has  continuous derivatives on some open interval containing
continuous derivatives on some open interval containing 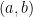 and if
and if  is the Lagrange polynomial running through the nodes
is the Lagrange polynomial running through the nodes 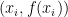 where all of the
where all of the ![x_i \in [a,b]](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) then the maximum of
then the maximum of 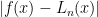 is bounded by
is bounded by 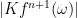 where
where ![\omega \in [a,b]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . So if the n+1’st derivative of is zero, then the interpolation is exact.
. So if the n+1’st derivative of is zero, then the interpolation is exact.
So, we introduce some notation: let 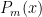 be the
be the 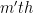 Legendre polynomial, let
Legendre polynomial, let  be the roots, and
be the roots, and 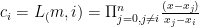 , the j’th coefficient polynomial for the Lagrange polynomial through the nodes
, the j’th coefficient polynomial for the Lagrange polynomial through the nodes  .
.
Now let  be any polynomial of degree less than
be any polynomial of degree less than  . First: the Lagrange polynomial
. First: the Lagrange polynomial  through the nodes
through the nodes  represents exactly as the error term is a multiple of the
represents exactly as the error term is a multiple of the  derivative of which is zero.
derivative of which is zero.
Therefore 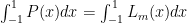


Now here is the key: 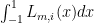 only depends on the Legendre polynomial being used and NOT on .
only depends on the Legendre polynomial being used and NOT on .
Hence we have a quadrature formula that is exact for all polynomials of degree less than 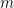 .
.
But, thanks to the division algorithm, we can do even better. We show that this quadrature scheme is exact for all polynomials  whose degree are less than
whose degree are less than 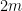 . This is where the orthogonality of the Legendre polynomials will be used.
. This is where the orthogonality of the Legendre polynomials will be used.
Let be a polynomial of degree less than . Then by the division algorithm, 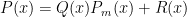 where BOTH and
where BOTH and  have degree less than .
have degree less than .
Now note the following:  ; that is where the fact that the
; that is where the fact that the  are the roots of the Legendre polynomials matters.
are the roots of the Legendre polynomials matters.
Then if we integrate:  . Now because of property 2 above,
. Now because of property 2 above,  .
.
Now because the degree of 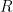 is less than ,
is less than , 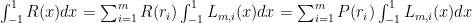
This means: this quadrature scheme using the Legendre polynomials of degree m is EXACT for all polynomials of degree less than 2m.
Of course, one must know the roots and the corresponding but these have been tabulated.
Why this is exciting:
Let’s try this technique on:  with, say, n = 5. We know that the exact answer is
with, say, n = 5. We know that the exact answer is 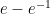 . But using the quadrature method with a spreadsheet:
. But using the quadrature method with a spreadsheet:

The roots are in column A, rows 5-9. The weights (coefficients; the ) are in column B, rows 5-9. In column F we apply the function 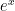 to the roots in column A; the products of the weights with
to the roots in column A; the products of the weights with  are in column G, and then we do a simple sum to get a very accurate approximation to the integral.
are in column G, and then we do a simple sum to get a very accurate approximation to the integral.
The accuracy: this is due to the quadrature method being EXACT on the first 9 terms of the series for  . The inexactness comes from the higher order Taylor terms.
. The inexactness comes from the higher order Taylor terms.
Note: to convert  , one uses the change of variable:
, one uses the change of variable:  to convert this to
to convert this to 






