I read yet another paper proclaiming that it is “now time to do away with p-values.” And yes, I can recommend reading the article.
From my point of view, one of the troubles with p-values is that there is a misunderstanding as to what they actually mean.
So here goes: the p-value is the probability that, given the null hypothesis is true, one obtains an observation as extreme (or greater) than the given observation. That is, if 


Example: suppose you assume that a coin is fair (the null hypothesis), and you toss it 100 times and observe 65 heads. It can be shown that 
That seems clear enough, statistically speaking.
But when one gets down to the science, one wants to determine whether there is evidence enough to believe one thing or another thing. So, is this coin biased or did this result happen “just by chance”? And strictly speaking, we don’t really know. For example, it could be that we did a precision scientific measurement on the coin and found it to be fair before doing the above experiment. Or it could be that this was just some coin we came across, or it could be that we were asked to examine this coin because of previous suspicious results. This information matters.
And think of it this way: suppose the above experiment was repeated, say, 100,000 times with a coin known to be fair. Then we’d expect to see the above result about 176 times and ALL of those “positives” would be “due to chance”.
Upshot: when it comes to scientific experiments, we still need replication.
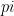 ,
,  , square roots, etc.
, square roots, etc. then it is reasonable to conclude that
then it is reasonable to conclude that  . It is as if we want students to think that functions take integers to integers.
. It is as if we want students to think that functions take integers to integers.  Now consider the following covering of the rational numbers:
Now consider the following covering of the rational numbers:  . The length of each open interval is
. The length of each open interval is  . Of course there will be overlapping intervals but that isn’t important. What is important is that if one sums the lengths one gets
. Of course there will be overlapping intervals but that isn’t important. What is important is that if one sums the lengths one gets  . So the rationals can be covered by a collection of open sets whose total length is less than or equal to 2.
. So the rationals can be covered by a collection of open sets whose total length is less than or equal to 2.  and the total length is now less than or equal to
and the total length is now less than or equal to  where
where  is any real number. Since there is no positive lower bound as to how small
is any real number. Since there is no positive lower bound as to how small  is a function between vector spaces such that
is a function between vector spaces such that  and
and  where the vector space operations of vector addition and scalar multiplication occur in their respective spaces.
where the vector space operations of vector addition and scalar multiplication occur in their respective spaces. endowed with the “vector addition”
endowed with the “vector addition”  where
where  represents ordinary real number multiplication and “scalar multiplication
represents ordinary real number multiplication and “scalar multiplication  where
where  and
and  is ordinary exponentiation. It is clear that
is ordinary exponentiation. It is clear that  is a vector space with
is a vector space with 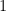 being the vector “additive” identity and
being the vector “additive” identity and 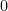 playing the role of the scalar zero and
playing the role of the scalar zero and  is a vector space isomophism between
is a vector space isomophism between  and
and 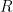 (the usual addition and scalar multiplication) and of course,
(the usual addition and scalar multiplication) and of course,  .
. , is it possible to come up with vector space operations (vector addition, scalar multiplication) so as to make a given, say, real valued, continuous one to one function into a linear transformation?
, is it possible to come up with vector space operations (vector addition, scalar multiplication) so as to make a given, say, real valued, continuous one to one function into a linear transformation? by
by  ,
,  any real number.
any real number. 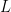 is a linear transformation.
is a linear transformation.  , let
, let  .
. .
. are of the form
are of the form  . These can be factored through:
. These can be factored through: .
. is the natural logarithm function). Now
is the natural logarithm function). Now  and
and  . This shows that
. This shows that  (the range has the usual vector space structure) is a linear transformation.
(the range has the usual vector space structure) is a linear transformation.  which shows that
which shows that  so
so  so
so  .
. denote the polynomials of degree
denote the polynomials of degree  or less; the coefficients will be real numbers. Clearly
or less; the coefficients will be real numbers. Clearly  dimensional and
dimensional and  constitutes a basis.
constitutes a basis.  . So, choose
. So, choose  . So, let’s construct an alternate basis as follows:
. So, let’s construct an alternate basis as follows: 

 and
and  if
if  .
.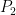 and we are interested in fixing
and we are interested in fixing  .
.
 . Then we note that
. Then we note that 
 are linearly independent. This is why:
are linearly independent. This is why:  as a vector. We can now solve for the
as a vector. We can now solve for the  Substitute
Substitute 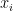 into the right hand side of the equation to get
into the right hand side of the equation to get  (note:
(note:  for
for  ). So
). So  are
are 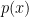 where
where  . We use our new basis to obtain:
. We use our new basis to obtain: . It is easy to check that
. It is easy to check that 
