Our goal: perform non-parametric statistical tests for two samples, both paired and independent. We only assume that both samples come from similar distributions, possibly shifted.
I’ll show the steps with just a bit of discussion of what the tests are doing; the text I am using is Mathematical Statistics (with Applications) by Wackerly, Mendenhall and Scheaffer (7’th ed.) and Mathematical Statistics and Data Analysis by John Rice (3’rd ed.).
First the data: 56 students took a final exam. The professor gave some questions and a committee gave some questions. Student performance was graded and the student performance was graded as a “percent out of 100” on each set of questions (committee graded their own questions, professor graded his questions).
The null hypothesis: student performance was the same on both sets of questions. Yes, this data was close enough to being normal that a paired t-test would have been appropriate and one was done for the committee. But because I am teaching a section on non-parametric statistics, I decided to run a paired sign test and a Wilcoxon signed rank test (and then, for the heck of it, a Mann-Whitney test which assumes independent samples..which these were NOT (of course)). The latter was to demonstrate the technique for the students.
There were 56 exams and “pi” was the score on my questions, “pii” the score on committee questions. The screen shot shows a truncated view.

The sign test for matched pairs.
The idea behind this test: take each pair and score it +1 if sample 1 is larger and score it -1 if the second sample is larger. Throw out ties (use your head here; too many ties means we can’t reject the null hypothesis ..the idea is that ties should be rare).
Now set up a binomial experiment where 

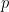



This is easy to do in a spreadsheet. Just use the difference in rows:

Now use the “sign” function to return a +1 if the entry from sample 1 is larger, -1 if the entry from sample 2 is larger, or 0 if they are the same.

I use “copy, paste, delete” to store the data from ties, which show up very easily.

Now we need to count the number of “+1”. That can be a tedious, error prone process. But the “countif” command in Excel handles this easily.

Now it is just a matter of either using a binomial calculator or just using the normal approximation (I don’t bother with the continuity correction)

Here we reject the null hypothesis that the scores are statistically the same.
Of course, this matched pairs sign test does not take magnitude of differences into account but rather only the number of times sample 1 is bigger than sample 2…that is, only “who wins” and not “by what score”. Clearly, the magnitude of the difference could well matter.
That brings us to the Wilcoxon signed rank test. Here we list the differences (as before) but then use the “absolute value” function to get the magnitudes of such differences.

Now we need to do an “average rank” of these differences (throwing out a few “zero differences” if need be). By “average rank” I mean the following: if there are “k” entries between ranks n, n+1, n+2, ..n+k-1, then each of these gets a rank

(use 
Needless to say, this can be very tedious. But the “rank.avg” function in Excel really helps.
Example: rank.avg(di, $d$2:$d$55, 1) does the following: it ranks the entry in cell di versus the cells in d2: d55 (the dollar signs make the cell addresses “absolute” references, so this doesn’t change as you move down the spreadsheet) and the “1” means you rank from lowest to highest.

Now the test works in the following manner: if the populations are roughly the same, the larger or smaller ranked differences will each come from the same population roughly half the time. So we denote 

One easy way to tease this out: 





One can use a T table (this is a different T than “student T”) or one can use the normal approximation (if n is greater than, say, 25) with


How these are obtained: the expectation is merely the one half the sum of all the ranks (what one would expect if the distributions were the same) and the variance comes from 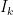


Here is a nice video describing the process by hand:
Mann-Whitney test
This test doesn’t apply here as the populations are, well, anything but independent, but we’ll pretend so we can crunch this data set.
Here the idea is very well expressed:
Do the following: label where the data comes from, and rank it all together. Then add the ranks of the population, of say, the first sample. If the samples are the same, the sums of the ranks should be the same for both populations.
Again, do a “rank average” and yes, Excel can do this over two different columns of data, while keeping the ranks themselves in separate columns.
And one can compare, using either column’s rank sum: the expectation would be 

Where this comes from: this is really a random sample of since 




So this is how it goes:


Note: I went ahead and ran the “matched pairs” t-test to contrast with the matched pairs sign test and Wilcoxon test, and the “two sample t-test with unequal variances” to contrast to the Mann-Whitney test..use the “unequal variances” assumption as the variance of sample pii is about double that of pi (I provided the F-test).



 . An ideal
. An ideal  is a subset of
is a subset of  that consists of 0 and all multiples of a given integer. The smallest positive integer
that consists of 0 and all multiples of a given integer. The smallest positive integer  in an ideal is the generator of that ideal; we denote that ideal by
in an ideal is the generator of that ideal; we denote that ideal by  .
. since every integer is a multiple of 1,
since every integer is a multiple of 1,  and
and  .
. 
 because neither has
because neither has 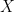 , the set of prime ideals of
, the set of prime ideals of  The elements (points) of
The elements (points) of  is a prime ideal because if
is a prime ideal because if  then
then  or
or  .
.  is not a prime ideal because
is not a prime ideal because  and a prime ideal cannot be all of
and a prime ideal cannot be all of  . We are indexing subsets of prime ideals by positive integers and zero. Now
. We are indexing subsets of prime ideals by positive integers and zero. Now  as every ideal contains zero.
as every ideal contains zero.  as no prime ideal contains
as no prime ideal contains 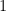 . Now if
. Now if  ,
,  has a prime factorization which contains prime factors
has a prime factorization which contains prime factors  , so
, so  so
so  . That is, the open basis elements are those collections of prime ideals that have a finite complement (those generated by the prime factorization of
. That is, the open basis elements are those collections of prime ideals that have a finite complement (those generated by the prime factorization of  .
.  is closed if there exists some ideal
is closed if there exists some ideal  . For example,
. For example,  is a closed set because
is a closed set because  is open. And note
is open. And note  . Note: traditionally, the Zariski topology is defined in terms of closed sets.
. Note: traditionally, the Zariski topology is defined in terms of closed sets.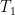 ( a topology is
( a topology is  in that, given two points, there is at least one open set that does not contain both of the points as
in that, given two points, there is at least one open set that does not contain both of the points as  for
for  but that is the subject of another post)
but that is the subject of another post) . Typically, we insist that the functions be, say,
. Typically, we insist that the functions be, say,  and note that it is a bit of a chore to show that the convolution of two
and note that it is a bit of a chore to show that the convolution of two  for
for ![x \in (0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%280%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and zero elsewhere)
and zero elsewhere)  be the function that is
be the function that is ![x \in [\frac{-1}{2}, \frac{1}{2}]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B%5Cfrac%7B-1%7D%7B2%7D%2C+%5Cfrac%7B1%7D%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and zero elsewhere. So, what is
and zero elsewhere. So, what is  ???
???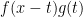 only assumes the value of
only assumes the value of 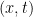 plane and is zero elsewhere; this is just like doing an iterated integral of a two variable function; at least the first step. This is why it fits well into calculus III.
plane and is zero elsewhere; this is just like doing an iterated integral of a two variable function; at least the first step. This is why it fits well into calculus III. for the following region:
for the following region: 
 .
. 
 has the following description:
has the following description:![f(x-t)f(t)=\left\{\begin{array}{c} 1,x \in [-1,0], -\frac{1}{2} t \le \frac{1}{2}+x \\ 1 ,x\in [0,1], -\frac{1}{2}+x \le t \le \frac{1}{2} \\ 0 \text{ elsewhere} \end{array}\right.](https://s0.wp.com/latex.php?latex=f%28x-t%29f%28t%29%3D%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bc%7D+1%2Cx+%5Cin+%5B-1%2C0%5D%2C+-%5Cfrac%7B1%7D%7B2%7D+t+%5Cle+%5Cfrac%7B1%7D%7B2%7D%2Bx+%5C%5C+1+%2Cx%5Cin+%5B0%2C1%5D%2C+-%5Cfrac%7B1%7D%7B2%7D%2Bx+%5Cle+t+%5Cle+%5Cfrac%7B1%7D%7B2%7D+%5C%5C+0+%5Ctext%7B+elsewhere%7D+%5Cend%7Barray%7D%5Cright.++&bg=ffffff&fg=000000&s=0&c=20201002)
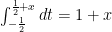 for
for  and
and  for
for ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) .
.
 describes the heat in a one dimensional circle of metal and the radius is one, one can do the analysis of the heat equation
describes the heat in a one dimensional circle of metal and the radius is one, one can do the analysis of the heat equation  with initial condition
with initial condition  and assuming that
and assuming that  has a Fourier expansion (complex coefficients) one can obtain:
has a Fourier expansion (complex coefficients) one can obtain:  which can be rewritten as
which can be rewritten as  . Note:
. Note:  to
to  and by
and by  we mean
we mean  and note that
and note that  are complex conjugates for all
are complex conjugates for all  . Now let
. Now let  then we could say that
then we could say that  which is a convolution product;
which is a convolution product;  is the heat kernel which is a nice form. But about that interchange: when can we do it?
is the heat kernel which is a nice form. But about that interchange: when can we do it?  we mean the limit of the sequence of partial sums:
we mean the limit of the sequence of partial sums:  and if
and if  then the interchange is valid. NOTE: I am following the custom of not using the “differential”
then the interchange is valid. NOTE: I am following the custom of not using the “differential”  and of letting it be understood that
and of letting it be understood that  means
means  .
.  are all measurable functions and
are all measurable functions and  (pointwise) and there exists an integrable function
(pointwise) and there exists an integrable function 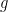 where
where  for all
for all  .
. .
.  , there are conditions that must be met to get that the the
, there are conditions that must be met to get that the the  which means that
which means that  exists. The mathematics of convergence of a Fourier series is rich; for this note we will assume that the Fourier series in question converges.
exists. The mathematics of convergence of a Fourier series is rich; for this note we will assume that the Fourier series in question converges. then
then  but we need to use the Lebesgue integral to guarantee this equality..in general. This is why:
but we need to use the Lebesgue integral to guarantee this equality..in general. This is why:  and define
and define  and then inductively define
and then inductively define  . Then
. Then  and for each
and for each  ,
,  but
but  , the limit function, is not Riemann integrable. It is Lebesgue integrable though, and the integral remains 1.
, the limit function, is not Riemann integrable. It is Lebesgue integrable though, and the integral remains 1. uniformly if for any
uniformly if for any  there exists
there exists 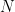 such that for all
such that for all  ,
,  for ALL
for ALL  in the interval of interest. Then, it a routine exercise in Riemann integration to see that if
in the interval of interest. Then, it a routine exercise in Riemann integration to see that if  . The down side is that we rarely have uniform convergence when we are talking about Fourier series terms. Here is why: it is known that if
. The down side is that we rarely have uniform convergence when we are talking about Fourier series terms. Here is why: it is known that if ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) then there is some
then there is some  such that
such that  . The proof is pretty easy: Let
. The proof is pretty easy: Let  then the Fundamental Theorem of Calculus says that
then the Fundamental Theorem of Calculus says that 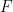 is continuous on
is continuous on 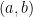 so the Mean Value Theorem applies: there is some
so the Mean Value Theorem applies: there is some  and the result follows.
and the result follows.  then the Mean Value Theorem says that there is a rectangle whose base is
then the Mean Value Theorem says that there is a rectangle whose base is  and whose height is
and whose height is  whose area is equal to the integral.
whose area is equal to the integral. 
 is positive and continuous (actually, integrable and positive is enough) on
is positive and continuous (actually, integrable and positive is enough) on  .
.  is the maximum;
is the maximum;  is the minimum. So we have for all
is the minimum. So we have for all ![x \in [a,b], f(x_m)g(x) \le f(x)g(x) \le f(x_M)g(x)](https://s0.wp.com/latex.php?latex=x+%5Cin+%5Ba%2Cb%5D%2C+f%28x_m%29g%28x%29+%5Cle+f%28x%29g%28x%29+%5Cle+f%28x_M%29g%28x%29+&bg=ffffff&fg=000000&s=0&c=20201002) Now integrate:
Now integrate:  Now divide through by
Now divide through by  and note that the integral is positive. So
and note that the integral is positive. So  . Now because
. Now because  is attained by
is attained by  such that
such that  and the result follows.
and the result follows.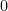 as desired.
as desired.  . Now compute by using integration by parts:
. Now compute by using integration by parts:  (if the assignment of
(if the assignment of  seems strange, remember we can use ANY anti-derivative of
seems strange, remember we can use ANY anti-derivative of  .)
.) so by substitution we obtain
so by substitution we obtain 
 and so we obtain (for the integral)
and so we obtain (for the integral)  Now substitute this for the integral in the order 1 expression, and remember the negative sign: we obtain
Now substitute this for the integral in the order 1 expression, and remember the negative sign: we obtain 

 is odd and positive when
is odd and positive when  by
by  and so the remainder formula becomes:
and so the remainder formula becomes:  .
.![[0,x]](https://s0.wp.com/latex.php?latex=%5B0%2Cx%5D+&bg=ffffff&fg=000000&s=0&c=20201002) the First Mean Value Theorem for Integrals says that there exists a
the First Mean Value Theorem for Integrals says that there exists a  where
where  is the remainder; that is the Cauchy form.
is the remainder; that is the Cauchy form.  where
where 
 and they could whip out a table.
and they could whip out a table. in two different ways: use the Fundamental Theorem of calculus on one side (to obtain
in two different ways: use the Fundamental Theorem of calculus on one side (to obtain  and use integration by parts on the other side:
and use integration by parts on the other side:  (yes, we are being choosy about which anti derivative of
(yes, we are being choosy about which anti derivative of  so
so  and one proceeds from there.
and one proceeds from there. one seeks to find an integrating factor (which is
one seeks to find an integrating factor (which is  so as to get:
so as to get:  which can be written as
which can be written as  . That is, the left hand side is just the product rule for derivatives, which, as you know (if you are a calculus teacher), is really all integration by parts is!
. That is, the left hand side is just the product rule for derivatives, which, as you know (if you are a calculus teacher), is really all integration by parts is! where
where  are arbitrary constants. But, my main point is that integration by parts should be UNDERSTOOD; short cuts to do tedious calculations are relatively unimportant, IMHO.
are arbitrary constants. But, my main point is that integration by parts should be UNDERSTOOD; short cuts to do tedious calculations are relatively unimportant, IMHO.
 ? That is, you learned that the derivative of
? That is, you learned that the derivative of  is a scalar multiple of itself? (emphasis on SELF). So you already know that the function
is a scalar multiple of itself? (emphasis on SELF). So you already know that the function  with eigenvalue
with eigenvalue  because that is the scalar multiple.
because that is the scalar multiple. is an eigenfunction of the operator
is an eigenfunction of the operator  with eigenvalue
with eigenvalue  because
because  . That is, the function
. That is, the function  and
and  which is a scalar multiple of the original function.
which is a scalar multiple of the original function.  , etc. We could also use things like real numbers for scalars, and say, three dimensional vectors such as
, etc. We could also use things like real numbers for scalars, and say, three dimensional vectors such as ![[a, b, c]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%2C+c%5D+&bg=ffffff&fg=000000&s=0&c=20201002) More formally, we start with a
More formally, we start with a 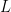 that obeys the following laws:
that obeys the following laws:  and
and  . Note that I am using
. Note that I am using 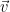 to denote the vectors and the undecorated variable to denote the scalars. Also note that this linear transformation
to denote the vectors and the undecorated variable to denote the scalars. Also note that this linear transformation ![L([x,y]^T) = \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} ax+ by \\ cx+dy \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+a+%26+b+%5C%5C+c+%26+d+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+ax%2B+by+%5C%5C+cx%2Bdy+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002) (note:
(note: ![[x,y]^T](https://s0.wp.com/latex.php?latex=%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002) is the transpose of the row vector; we need to use a column vector for the usual rules of matrix multiplication to apply).
is the transpose of the row vector; we need to use a column vector for the usual rules of matrix multiplication to apply).![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} x+ 2y \\ 3y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x%2B+2y+%5C%5C+3y+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002)
![L([x,y]^T) = \lambda [x,y]^T](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Clambda+%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002) for some real number
for some real number 
![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]= \lambda \left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . So doing some algebra (subtracting the vector on the right hand side from both sides) we obtain
. So doing some algebra (subtracting the vector on the right hand side from both sides) we obtain ![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) from the left side. But, while the expression makes sense prior to factoring, it wouldn’t AFTER factoring as we’d be subtracting a scalar number from a 2 by 2 matrix! But there is a way out of this: one can then insert the 2 x 2 identity matrix to the left of the second term of the left hand side:
from the left side. But, while the expression makes sense prior to factoring, it wouldn’t AFTER factoring as we’d be subtracting a scalar number from a 2 by 2 matrix! But there is a way out of this: one can then insert the 2 x 2 identity matrix to the left of the second term of the left hand side:![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![(\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] )\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D++-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%29%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![(\left[ \begin{array}{cc} 1-\lambda & 2 \\ 0 & 3-\lambda \end{array} \right] ) \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1-%5Clambda+%26+2+%5C%5C+0+%26+3-%5Clambda+%5Cend%7Barray%7D+%5Cright%5D+%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 which means that
which means that  are the respective eigenvalues. Note: when we do this procedure with any 2 by 2 matrix, we always end up with a quadratic with
are the respective eigenvalues. Note: when we do this procedure with any 2 by 2 matrix, we always end up with a quadratic with  we get
we get![(\left[ \begin{array}{cc} 0 & 2 \\ 0 & 2 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+2+%5C%5C+0+%26+2+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) which has solution
which has solution ![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . So that is the eigenvector associated with eigenvalue 1.
. So that is the eigenvector associated with eigenvalue 1. we get
we get![(\left[ \begin{array}{cc} -2 & 2 \\ 0 & 0 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+-2+%26+2+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) which has solution
which has solution ![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . So that is the eigenvector associated with the eigenvalue 3.
. So that is the eigenvector associated with the eigenvalue 3.  for the linear transformation.
for the linear transformation. which is the same as matrix
which is the same as matrix  is a polynomial in variable
is a polynomial in variable  . These will be the eigenvalues.
. These will be the eigenvalues. Substitute this into the matrix-vector equation
Substitute this into the matrix-vector equation  and solve for
and solve for  . That will be the eigenvector associated with the first eigenvalue. Do this for each eigenvalue, one at a time. Note: you can get up to
. That will be the eigenvector associated with the first eigenvalue. Do this for each eigenvalue, one at a time. Note: you can get up to  , that is, the process that takes the n’th derivative of a function. You learned that the sum of the derivatives is the derivative of the sums and that you can pull out a constant when you differentiate. Hence
, that is, the process that takes the n’th derivative of a function. You learned that the sum of the derivatives is the derivative of the sums and that you can pull out a constant when you differentiate. Hence  is a linear operator (transformation); we use the term “operator” when we talk about the vector space of functions, but it is really just a type of linear transformation.
is a linear operator (transformation); we use the term “operator” when we talk about the vector space of functions, but it is really just a type of linear transformation. We see that such “linear combinations” of linear operators is a linear operator.
We see that such “linear combinations” of linear operators is a linear operator. . An eigenvector is a twice differentiable function
. An eigenvector is a twice differentiable function 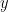 (ok, we said “infinitely differentiable”) such that
(ok, we said “infinitely differentiable”) such that  or
or  which means
which means  . You might recognize this from your differential equations class; the only “tweak” is that we don’t know what
. You might recognize this from your differential equations class; the only “tweak” is that we don’t know what  which has solutions:
which has solutions:  and the solution takes the form
and the solution takes the form  if the roots are real and distinct,
if the roots are real and distinct,  if the roots are complex conjugates
if the roots are complex conjugates  and
and  if there is a real, repeated root. In any event, those functions are the eigenfunctions and these very much depend on the eigenvalues.
if there is a real, repeated root. In any event, those functions are the eigenfunctions and these very much depend on the eigenvalues.  for all positive integers
for all positive integers  ).
). so the statement is true for
so the statement is true for  .
. as well.
as well.
 (factor out a k+1 term)
(factor out a k+1 term)
 be a candidate to be the least element. Then
be a candidate to be the least element. Then  is greater than zero but is less than
is greater than zero but is less than  is also even and is bigger than
is also even and is bigger than  We start by labeling our statements:
We start by labeling our statements:  is statement P(1),
is statement P(1), is statement P(2), …
is statement P(2), … is statement P(5) and so on.
is statement P(5) and so on.
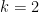 or some larger integer, and these integers can always be written in the form
or some larger integer, and these integers can always be written in the form  .
. since
since  . This contradicts that statement P(
. This contradicts that statement P(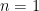 through
through  ).
). prior to proceeding.
prior to proceeding. if
if 
 Differentiate both sides:
Differentiate both sides:  which yields:
which yields:
 This leads to
This leads to 
 which yields
which yields  which yields the easy solution:
which yields the easy solution:


 whose solution IS uniquely determined on an open rectangle so long as
whose solution IS uniquely determined on an open rectangle so long as  and
and  are continuous also.
are continuous also. and
and  indeed have unique solutions that have the same slope at a common point, but with just this there is no reason that the solutions coincide over a whole interval (at least without some other condition).
indeed have unique solutions that have the same slope at a common point, but with just this there is no reason that the solutions coincide over a whole interval (at least without some other condition).