This is “part 2” of a previous post about series. Once again, this is not designed for students seeing the material for the first time.
I’ll deal with general power series first, then later discuss Taylor Series (one method of obtaining a power series).
General Power Series Unless otherwise stated, we will be dealing with series such as 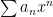

So, IF we have a function 
what do we mean by this and what can we say about it?
The first thing to consider, of course, is convergence. One main fact is that the open interval of convergence of a power series centered at 0 is either:
1. Non existent …series converges at 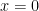
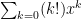
2. Converges absolutely on 
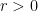

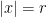
3. Converges absolutely on the whole real line.
Many texts state this result but do not prove it. I can understand as this result is really an artifact of calculus of a complex variable. But it won’t hurt to sketch out a proof at least for the “converge” case for
So, let’s assume that 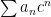

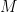

So write: 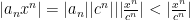
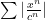


Though the relation between real and complex variables might not be apparent, it CAN be useful. Here is an example: suppose one wants to find the open interval of convergence of, say, the series representation for 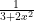
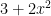


So, what about a function defined as a power series?
For one, a power series expansion of a function at a specific point (say, 
Say 

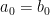


Yes, this should have property been phrased as a limit and I’ve yet to show that 
Now if you say “doesn’t that follow from uniform convergence which follows from the Weierstrass M test” you’d be correct…and you are probably wasting your time reading this.
Now if you remember hearing those words but could use a refresher, here goes:
We want 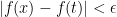






The rest follows:

Calculus On the open interval of absolute convergence, a power series can be integrated term by term and differentiated term by term. Neither result, IMHO, is “obvious.” In fact, sans extra criteria, for series of functions, in general, it is false. Quickly: if you remember Fourier Series, think about the Fourier series for a rectangular pulse wave; note that the derivative is zero everywhere except for the jump points (where it is undefined), then differentiate the constituent functions and get a colossal mess.

Differentiation: most texts avoid the direct proof (with good reason; it is a mess) but it can follow from analysis results IF one first shows that the absolute (and uniform) convergence of
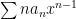
So, let’s start here: if 

Here is why: because we are on the open interval of absolute convergence, WLOG, assume 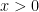


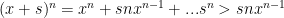

Of course, this doesn’t prove that the expected series IS the derivative; we have a bit more work to do.
Again, working on the open interval of absolute convergence, let’s look at:
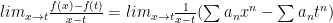
Now, we use the fact that 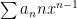
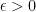




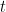
So let’s do that: pick 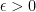

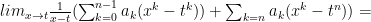


Now apply the Mean Value Theorem to each term in the second term:

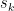



So, THAT is “term by term” differentiation…and notice that we’ve used our hypothesis …almost all of it.
Term by term integration
Theoretically, integration combines easier with infinite summation than differentiation does. But given we’ve done differentiation, we can then do anti-differentiation by showing that 
But let’s do this independently; it is good for us. And we’ll focus on the definite integral.

![[a,b] \subset (-r, r)](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+%5Csubset+%28-r%2C+r%29+&bg=ffffff&fg=000000&s=0&c=20201002)
Once again, choose

Then 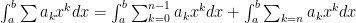

But
Taylor Series
Ok, now that we can say stuff about a function presented as a power series, what about finding a power series representation for a function, PROVIDED there is one? Note: we’ll need the function to have an infinite number of derivatives on an open interval about the point of expansion. We’ll also need another condition, which we will explain as we go along.
We will work with expanding about 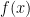
Start with 
But now, let’s use integration by parts on the integral with 

So now we have:

It looks like we might run into sign trouble on the next iteration, but we won’t as we will see: do integration by parts again:


This turns out to be 
An induction argument yields

For the series to exist (and be valid over an open interval) all of the derivatives have to exist and;

Note: to get the Lagrange remainder formula that you see in some texts, let 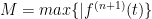
![t \in [0,x]](https://s0.wp.com/latex.php?latex=t+%5Cin+%5B0%2Cx%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

It is a bit trickier to get the equality 
About the remainder term going to zero: this is necessary. Consider the classic counterexample:
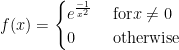
It is an exercise in the limit definition and L’Hopital’s Rule to show that 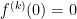


As you can see, the function appears to flatten out near x =0 $ but it really is NOT constant.
Note: of course, using the Taylor method isn’t always the best way. For example, if we were to try to get the Taylor expansion of 
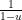
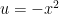
 converges.
converges.  where
where  is a
is a  matrix.
matrix.  where the powers make sense as
where the powers make sense as  is square and we merely add the corresponding matrix entries.
is square and we merely add the corresponding matrix entries.  can get only so large.
can get only so large. (just sum up the absolute value of the elements (the Taxi cab norm or
(just sum up the absolute value of the elements (the Taxi cab norm or 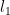 norm )
norm ) 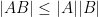 and
and  and together this implies the following:
and together this implies the following: where
where 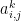 is the i-j’th element of
is the i-j’th element of 
![| [ e^A ]_{i,j} | \leq \sum^{\infty}_{k=0} {|A^k |\over k!} \leq \sum^{\infty}_{k=0} {|A|^k \over k!} =e^{|A|}](https://s0.wp.com/latex.php?latex=%7C+%5B+e%5EA+%5D_%7Bi%2Cj%7D+%7C+%5Cleq+%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%5Ek+%7C%5Cover+k%21%7D+%5Cleq++%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%7C%5Ek+%5Cover+k%21%7D+%3De%5E%7B%7CA%7C%7D+&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore every series that determines an entry of the matrix
. Therefore every series that determines an entry of the matrix  is a series and
is a series and  is some sequence consisting of 0’s and 1’s then a selective sum of the series is
is some sequence consisting of 0’s and 1’s then a selective sum of the series is  . The selective sum concept is discussed in the MAA book Real Infinite Series (MAA Textbooks) by Bonar and Khoury (2006) and I was introduced to the concept by Ferdinands’s article Selective Sums of an Infinite Series in the June 2015 edition of Mathematics Magazine (Vol. 88, 179-185).
. The selective sum concept is discussed in the MAA book Real Infinite Series (MAA Textbooks) by Bonar and Khoury (2006) and I was introduced to the concept by Ferdinands’s article Selective Sums of an Infinite Series in the June 2015 edition of Mathematics Magazine (Vol. 88, 179-185). and
and  for all
for all  . Clearly if
. Clearly if  we are done: our selective sum has
we are done: our selective sum has  and the rest of the
and the rest of the  .
. and note that because the series diverges, there is a largest
and note that because the series diverges, there is a largest  so that
so that  . Now if
. Now if  we are done, else let
we are done, else let  and note
and note  . Now because the
. Now because the  tend to zero, there is some first
tend to zero, there is some first  so that
so that  . If this is equality then the required sum is
. If this is equality then the required sum is  , else we can find the largest
, else we can find the largest  so that
so that 
 we see that
we see that  form an increasing, bounded sequence which converges to the least upper bound of its range, and it isn’t hard to see that the least upper bound is
form an increasing, bounded sequence which converges to the least upper bound of its range, and it isn’t hard to see that the least upper bound is 
 are zero).
are zero). 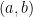 be any open interval in the real line and let
be any open interval in the real line and let  . Then one can find some
. Then one can find some 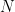 such that for all
such that for all  we have
we have  . Now consider our construction and choose
. Now consider our construction and choose 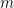 large enough such that
large enough such that  . Then the
. Then the  represents the finite selected sum that lies in the interval
represents the finite selected sum that lies in the interval  . We know that the set of finite selected sums forms a dense subset of the real line. But it turns out that the set of select sums is the rationals. I’ll give a slightly different proof than one finds in Bonar and Khoury.
. We know that the set of finite selected sums forms a dense subset of the real line. But it turns out that the set of select sums is the rationals. I’ll give a slightly different proof than one finds in Bonar and Khoury.![(0,1]](https://s0.wp.com/latex.php?latex=%280%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) is a finite select sum. Clearly 1 is a finite select sum. Otherwise: Given
is a finite select sum. Clearly 1 is a finite select sum. Otherwise: Given  we can find the minimum
we can find the minimum  . If
. If  we are done. Otherwise: the strict inequality shows that
we are done. Otherwise: the strict inequality shows that  which means
which means  . Then note
. Then note  and this fraction has a strictly smaller numerator than
and this fraction has a strictly smaller numerator than 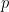 . So we can repeat our process with this new rational number. And this process must eventually terminate because the numerators generated from this process form a strictly decreasing sequence of positive integers. The process can only terminate when the new faction has a numerator of 1. Hence the original fraction is some sum of fractions with numerator 1.
. So we can repeat our process with this new rational number. And this process must eventually terminate because the numerators generated from this process form a strictly decreasing sequence of positive integers. The process can only terminate when the new faction has a numerator of 1. Hence the original fraction is some sum of fractions with numerator 1. in question is greater than one, one finds
in question is greater than one, one finds  so that
so that  but
but  . Then write
. Then write  and note that its magnitude is less than
and note that its magnitude is less than  . We then use the procedure for numbers in
. We then use the procedure for numbers in  noting that our starting point excludes the previously used terms of the harmonic series.
noting that our starting point excludes the previously used terms of the harmonic series.  at
at  is a winner. This gives an example of a
is a winner. This gives an example of a  function that is not analytic (on any open interval containing 0 ).
function that is not analytic (on any open interval containing 0 ). ,
,  .
. I’ll let it be understood that I mean the conditional function that I wrote above.
I’ll let it be understood that I mean the conditional function that I wrote above.  ; this is one time we can calculate a limit without using a function which one can merely “plug in”. It is easy to see that
; this is one time we can calculate a limit without using a function which one can merely “plug in”. It is easy to see that  .
. ; this is one case where we can’t merely “calculate”.
; this is one case where we can’t merely “calculate”. provides an example of a function that is differentiable at the origin but is not continuously differentiable there. It isn’t hard to see why; away from 0 the derivative is
provides an example of a function that is differentiable at the origin but is not continuously differentiable there. It isn’t hard to see why; away from 0 the derivative is  and the limit as
and the limit as  one can find a function that is
one can find a function that is 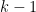 times differentiable at the origin but not
times differentiable at the origin but not  continuously differentiable.
continuously differentiable.  is differentiable at
is differentiable at  and
and  is differentiable at
is differentiable at  . Then we know that
. Then we know that 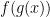 is differentiable at
is differentiable at 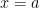 and the derivative is
and the derivative is  . The “natural” proof (say, for
. The “natural” proof (say, for 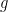 non-constant near
non-constant near  looks at the difference quotient:
looks at the difference quotient:  which works fine, so long as
which works fine, so long as  . So what could possibly go wrong; surely the set of values of
. So what could possibly go wrong; surely the set of values of  for a differentiable function is finite right? 🙂 That is where
for a differentiable function is finite right? 🙂 That is where  comes into play; this equals zero at an infinite number of points in any neighborhood of the origin.
comes into play; this equals zero at an infinite number of points in any neighborhood of the origin.  . Then it is easy to see that
. Then it is easy to see that  since the second factor of the last term is zero when
since the second factor of the last term is zero when  and the limit of
and the limit of 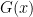 exists at
exists at 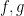 over some closed interval
over some closed interval ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and partitions
and partitions  look at upper and lower sums of
look at upper and lower sums of  and if the upper and lower sums converge as the width of the partions go to zero, you have the integral
and if the upper and lower sums converge as the width of the partions go to zero, you have the integral  . But this works only if
. But this works only if  for ALL partitions
for ALL partitions  is differentiable with a bounded derivative on
is differentiable with a bounded derivative on ![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D&bg=ffffff&fg=000000&s=0&c=20201002) then it isn’t hard to see that
then it isn’t hard to see that 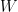 be a bound for
be a bound for  and then use the Mean Value Theorem to replace each
and then use the Mean Value Theorem to replace each  by
by  and the result follows easily.
and the result follows easily.  . 🙂 Now consider a partition of the following variety:
. 🙂 Now consider a partition of the following variety:  . Example: say
. Example: say  . Compute the variation:
. Compute the variation:  . This leads to trouble as this sum has no limit as we progress with more points in the sequence of partitions; we end up with a divergent series (the Harmonic Series) as one term as points are added to the partition.
. This leads to trouble as this sum has no limit as we progress with more points in the sequence of partitions; we end up with a divergent series (the Harmonic Series) as one term as points are added to the partition.  to be continuous on an interval. You know what it means for
to be continuous on an interval. You know what it means for 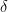 works for a given
works for a given  such that for
such that for  where
where  are pairwise disjoint intervals. An example of a function that is continuous on a closed interval but not absolutely continuous? Yes;
are pairwise disjoint intervals. An example of a function that is continuous on a closed interval but not absolutely continuous? Yes;  on any interval containing
on any interval containing 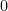 is an example; the work that we did in paragraph 5 works nicely; just make the intervals pairwise disjoint.
is an example; the work that we did in paragraph 5 works nicely; just make the intervals pairwise disjoint. ![[-\pi, \pi]](https://s0.wp.com/latex.php?latex=%5B-%5Cpi%2C+%5Cpi%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and let our “state vector”
and let our “state vector” 
 which has an eigenbasis
which has an eigenbasis  and
and  with eigenvalues
with eigenvalues  (note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).
(note: I know that this is a degenerate case in which some eigenvalues share two eigenfunctions).  as required for an orthonormal basis with this inner product.
as required for an orthonormal basis with this inner product. 




 .
.  with
with  We will use the usual notion of convergence; that is, the series converges if the sequence of partial sums converge. If that last statement puzzles you, there are other
We will use the usual notion of convergence; that is, the series converges if the sequence of partial sums converge. If that last statement puzzles you, there are other  . If
. If  the series diverges. If
the series diverges. If  the series converges. If
the series converges. If  the test is inconclusive.
the test is inconclusive. . If
. If  converges for all
converges for all  for all
for all 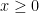 hence the series converges absolutely for all
hence the series converges absolutely for all  converges for all
converges for all  for all
for all  the root test, as stated, doesn't apply as
the root test, as stated, doesn't apply as  fails to exist, though it is clear that the
fails to exist, though it is clear that the  and the series is dominated by the convergent geometric series
and the series is dominated by the convergent geometric series  and therefore converges.
and therefore converges. with
with  and some index
and some index  such that for all
such that for all 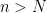 ,
,  . Hence for all
. Hence for all  ,
,  where
where  . Therefore the series converges by a direct comparison with the convergent geometric series
. Therefore the series converges by a direct comparison with the convergent geometric series  .
.  to exist is overkill; what is important that, for some index
to exist is overkill; what is important that, for some index  . This is enough for the comparison with the geometric series to work. In fact, in the language of analysis, we can replace the limit condition with
. This is enough for the comparison with the geometric series to work. In fact, in the language of analysis, we can replace the limit condition with  . If you are fuzzy about limit superior,
. If you are fuzzy about limit superior, ,
,  . This point may seem pedantic but we’ll use this in just a bit.
. This point may seem pedantic but we’ll use this in just a bit. then there is an index
then there is an index  such that for all
such that for all  ,
,  .
. and
and  and in general
and in general  . Hence the series
. Hence the series  is dominated by
is dominated by  which is a convergent geometric series.
which is a convergent geometric series. .
. hence the root test works. But the ratio test yields the following:
hence the root test works. But the ratio test yields the following: which tends to infinity as
which tends to infinity as  . Then we can take
. Then we can take  roots of both sides and note:
roots of both sides and note:  hence the weakened hypothesis of the root test is met.
hence the weakened hypothesis of the root test is met.  has positive terms:
has positive terms: we have
we have  then the series converges.
then the series converges. then the series converges.
then the series converges.