Let me start by saying that this is NOT: this is not an introduction for calculus students (too steep) nor is this intended for experienced calculus teachers. Nor is this a “you should teach it THIS way” or “introduce the concepts in THIS order or emphasize THESE topics”; that is for the individual teacher to decide.
Rather, this is a quick overview to help the new teacher (or for the teacher who has not taught it in a long time) decide for themselves how to go about it.
And yes, I’ll be giving a lot of opinions; disagree if you like.
What series will be used for.
Of course, infinite series have applications in probability theory (discrete density functions, expectation and higher moment values of discrete random variables), financial mathematics (perpetuities), etc. and these are great reasons to learn about them. But in calculus, these tend to be background material for power series.
Power series: 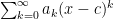
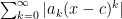
We teach that these intervals are *always* symmetric about 


Therefore, if time is limited, I tend to focus on material more relevant for series that are absolutely convergent though there are some interesting (and fun) things one can do for a series which is conditionally convergent (convergent, but not absolutely convergent; e. g. 
Important principles: I think it is a good idea to first deal with geometric series and then series with positive terms…make that “non-negative” terms.
Geometric series: 

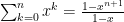

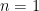
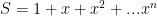
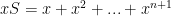

Now to show the geometric series converges, (convergence being the standard kind: 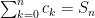


Now that we’ve established that for the geometric series, 

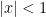
Why geometric series: two of the most common series tests (root and ratio tests) involve a comparison to a geometric series. Also, the geometric series concept is used both in the theory of improper integrals and in measure theory (e. g., showing that the rational numbers have measure zero).
Series of non-negative terms. For now, we’ll assume that 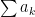

Main principle: though most texts talk about the various tests, I believe that most of the tests involved really involve three key principles, two of which the geometric series and the following result from sequences of positive numbers:
Key sequence result: every monotone bounded sequence of positive numbers converges to its least upper bound.
True: many calculus texts don’t do that much with the least upper bound concept but I feel it is intuitive enough to at least mention. If the least upper bound is, say, 
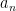
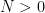

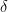


The third key principle is “common sense” : if 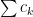



Secondary results I think that the next results are “second order” results: the main results depend on these, and these depend on the key 3 that we just discussed.
The first of these secondary results is the direct comparison test for series of non-negative terms:
Direct comparison test
If 


The proof is basically the “bounded monotone sequence” principle applied to the partial sums. I like to call it “if you are taller than an NBA center then you are tall” principle.
Evidently, some see this result as a “just get to something else” result, but it is extremely useful; one can apply this to show that the exponential of a square matrix is defined; it is the principle behind the Weierstrass M-test, etc. Do not underestimate this test!
Absolute convergence: this is the most important kind of convergence for power series as this is the type of convergence we will have on an open interval. A series is absolutely convergent if 
Note 


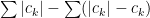
Integral test This is an important test for convergence at a point. This test assumes that 



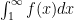
Proof: 


Yes, these are crude whiteboards but they get the job done.
Note: we need the hypothesis that 

Going the other way, defining ![f(x) = \begin{cases} 2^n , & \text{ if } x \in [n, n+2^{-2n}] \\0, & \text{ otherwise} \end{cases}](https://s0.wp.com/latex.php?latex=f%28x%29+%3D+%5Cbegin%7Bcases%7D++2%5En+%2C+%26+%5Ctext%7B+if+%7D++x+%5Cin+%5Bn%2C+n%2B2%5E%7B-2n%7D%5D+%5C%5C0%2C+%26+%5Ctext%7B+otherwise%7D+%5Cend%7Bcases%7D+&bg=ffffff&fg=000000&s=0&c=20201002)



Note: the above shows the integral and sum starting at 0; same principle though.
Now wait a minute: we haven’t really gone over how students will do most of their homework and exam problems. We’ve covered none of these: p-test, limit comparison test, ratio test, root test. Ok, logically, we have but not practically.
Let’s remedy that. First, start with the “point convergence” tests.
p-test. This says that 

Limit comparison test Given two series of positive terms: 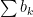

Suppose 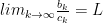
If 
If 
I’ll show the “converge” part of the proof: choose 
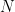


But note what is going on: it really isn’t necessary for 
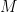

We will see this again.
Why limit comparison is used: Something like 
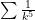
Ratio test this test is most commonly used when the series has powers and/or factorials in it. Basically: given 
If 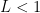
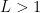
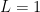
Note: if it turns out that there is exists some 

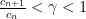
Why this works: suppose there exists some
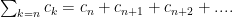
now factor out a 
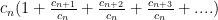
Now multiply the terms by 1 in a clever way:
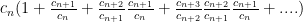
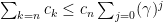
See: there is geometric series and the direct comparison test, again.
Root Test No, this is NOT the same as the ratio test. In fact, it is a bit “stronger” than the ratio test in that the root test will work for anything the ratio test works for, but there are some series that the root test works for that the ratio test comes up empty.
I’ll state the “lim sup” version of the ratio test: if there exists some 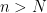
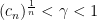
As before: if the condition is met, 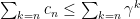
Now as far as my previous remark about the ratio test: Consider the series:

Yes, this series is bounded by the convergent geometric series with 
But the ratio test is a disaster as 

What about non-absolute convergence (aka “conditional convergence”)
Series like 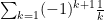
So, let’s chat about these a bit.
We say
One elementary tool for dealing with these is the alternating series test:
for this, let 
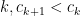
Then 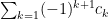
That the sequence of terms goes to zero is necessary. That it is sufficient in this alternating case: first note that the terms of the sequence of partial sums are bounded above by 

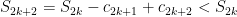
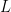


Of course, there are conditionally convergent series that are NOT alternating. And conditionally convergent series have some interesting properties.
One of the most interesting properties is that such series can be “rearranged” (“derangment” in Knopp’s book) to either converge to any number of choice or to diverge to infinity or to have no limit at all.
Here is an outline of the arguments:
To rearrange a series to converge to 
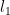

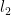
Note that at every stage, every partial sum after the first one past 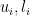

To rearrange a series to diverge to infinity: Add the positive terms to exceed 1. Add a negative term. Then add the terms to exceed 2. Add a negative term. Repeat this for each positive integer 
Have fun with this; you can have the partial sums end up all over the place.
That’s it for now; I might do power series later.
 converges.
converges.  where
where  is a
is a  matrix.
matrix.  where the powers make sense as
where the powers make sense as  is square and we merely add the corresponding matrix entries.
is square and we merely add the corresponding matrix entries.  can get only so large.
can get only so large. (just sum up the absolute value of the elements (the Taxi cab norm or
(just sum up the absolute value of the elements (the Taxi cab norm or 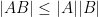 and
and  and together this implies the following:
and together this implies the following: where
where 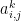 is the i-j’th element of
is the i-j’th element of 
![| [ e^A ]_{i,j} | \leq \sum^{\infty}_{k=0} {|A^k |\over k!} \leq \sum^{\infty}_{k=0} {|A|^k \over k!} =e^{|A|}](https://s0.wp.com/latex.php?latex=%7C+%5B+e%5EA+%5D_%7Bi%2Cj%7D+%7C+%5Cleq+%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%5Ek+%7C%5Cover+k%21%7D+%5Cleq++%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%7C%5Ek+%5Cover+k%21%7D+%3De%5E%7B%7CA%7C%7D+&bg=ffffff&fg=000000&s=0&c=20201002) . Therefore every series that determines an entry of the matrix
. Therefore every series that determines an entry of the matrix  is a series and
is a series and  is some sequence consisting of 0’s and 1’s then a selective sum of the series is
is some sequence consisting of 0’s and 1’s then a selective sum of the series is  . The selective sum concept is discussed in the MAA book Real Infinite Series (MAA Textbooks) by Bonar and Khoury (2006) and I was introduced to the concept by Ferdinands’s article Selective Sums of an Infinite Series in the June 2015 edition of Mathematics Magazine (Vol. 88, 179-185).
. The selective sum concept is discussed in the MAA book Real Infinite Series (MAA Textbooks) by Bonar and Khoury (2006) and I was introduced to the concept by Ferdinands’s article Selective Sums of an Infinite Series in the June 2015 edition of Mathematics Magazine (Vol. 88, 179-185). and
and  for all
for all 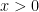 is a selective sum of such a series. The proof of this isn’t that bad. Since
is a selective sum of such a series. The proof of this isn’t that bad. Since  . Clearly if
. Clearly if  we are done: our selective sum has
we are done: our selective sum has  and the rest of the
and the rest of the  .
. and note that because the series diverges, there is a largest
and note that because the series diverges, there is a largest  so that
so that  . Now if
. Now if  we are done, else let
we are done, else let  and note
and note  . Now because the
. Now because the  tend to zero, there is some first
tend to zero, there is some first  so that
so that  . If this is equality then the required sum is
. If this is equality then the required sum is  , else we can find the largest
, else we can find the largest  so that
so that 
 we see that
we see that  form an increasing, bounded sequence which converges to the least upper bound of its range, and it isn’t hard to see that the least upper bound is
form an increasing, bounded sequence which converges to the least upper bound of its range, and it isn’t hard to see that the least upper bound is  because
because 
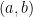 be any open interval in the real line and let
be any open interval in the real line and let  . Then one can find some
. Then one can find some  . Now consider our construction and choose
. Now consider our construction and choose 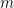 large enough such that
large enough such that  . Then the
. Then the  represents the finite selected sum that lies in the interval
represents the finite selected sum that lies in the interval  . We know that the set of finite selected sums forms a dense subset of the real line. But it turns out that the set of select sums is the rationals. I’ll give a slightly different proof than one finds in Bonar and Khoury.
. We know that the set of finite selected sums forms a dense subset of the real line. But it turns out that the set of select sums is the rationals. I’ll give a slightly different proof than one finds in Bonar and Khoury.![(0,1]](https://s0.wp.com/latex.php?latex=%280%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) is a finite select sum. Clearly 1 is a finite select sum. Otherwise: Given
is a finite select sum. Clearly 1 is a finite select sum. Otherwise: Given  we can find the minimum
we can find the minimum  . If
. If  we are done. Otherwise: the strict inequality shows that
we are done. Otherwise: the strict inequality shows that  which means
which means  . Then note
. Then note  and this fraction has a strictly smaller numerator than
and this fraction has a strictly smaller numerator than 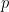 . So we can repeat our process with this new rational number. And this process must eventually terminate because the numerators generated from this process form a strictly decreasing sequence of positive integers. The process can only terminate when the new faction has a numerator of 1. Hence the original fraction is some sum of fractions with numerator 1.
. So we can repeat our process with this new rational number. And this process must eventually terminate because the numerators generated from this process form a strictly decreasing sequence of positive integers. The process can only terminate when the new faction has a numerator of 1. Hence the original fraction is some sum of fractions with numerator 1. in question is greater than one, one finds
in question is greater than one, one finds  so that
so that  but
but  . Then write
. Then write  and note that its magnitude is less than
and note that its magnitude is less than  . We then use the procedure for numbers in
. We then use the procedure for numbers in  noting that our starting point excludes the previously used terms of the harmonic series.
noting that our starting point excludes the previously used terms of the harmonic series.  and
and  then
then  is said to be convergent with sum
is said to be convergent with sum  .
. . Now this is complete nonsense by our usual modern definition. But we might note that
. Now this is complete nonsense by our usual modern definition. But we might note that  for
for 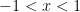 and note that
and note that  IS in the domain of the left hand side.
IS in the domain of the left hand side.  . Clearly,
. Clearly,  and so this geometric series diverges. But notice that the arithmetic average of the partial sums, computed as
and so this geometric series diverges. But notice that the arithmetic average of the partial sums, computed as  does tend to
does tend to  as
as  whereas
whereas  and both of these quantities tend to
and both of these quantities tend to  be a sequence that converges to zero. Then for any
be a sequence that converges to zero. Then for any 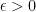 we can find
we can find  implies that
implies that  . So for
. So for  we have
we have  Because
Because  in absolute value. But
in absolute value. But  and let
and let  Now subtract note
Now subtract note  and the
and the  forms a null sequence. Then so do the
forms a null sequence. Then so do the  .
. , then this series is NOT Cesàro summable. It is relatively easy to see why: given such an
, then this series is NOT Cesàro summable. It is relatively easy to see why: given such an  then consider
then consider  which is greater than
which is greater than  for large
for large  into a convergent series by this method. Now there is a way of making an alternating, divergent series into a convergent one via doing something like a “double Cesàro sum” (take arithmetic averages of the arithmetic averages) but that is a topic for another post.
into a convergent series by this method. Now there is a way of making an alternating, divergent series into a convergent one via doing something like a “double Cesàro sum” (take arithmetic averages of the arithmetic averages) but that is a topic for another post. and on
and on  and on
and on  . In the first two cases, the series converges slowly enough so that Cesàro summation speeds up convergence. Cesàro slows down the convergence in the geometric series though. It is interesting to ponder why.
. In the first two cases, the series converges slowly enough so that Cesàro summation speeds up convergence. Cesàro slows down the convergence in the geometric series though. It is interesting to ponder why. 
 . Now how does one select a subset of series terms to delete so as to obtain a convergent series? The Kundson article shows that one can do this with the harmonic series by, say, deleting all numbers that contain a specific digit (say, 9). I’ll talk about the proof here. But I’d like to start more basic and to bring in language used in the Ferdinands article.
. Now how does one select a subset of series terms to delete so as to obtain a convergent series? The Kundson article shows that one can do this with the harmonic series by, say, deleting all numbers that contain a specific digit (say, 9). I’ll talk about the proof here. But I’d like to start more basic and to bring in language used in the Ferdinands article. for all
for all  . Now let
. Now let  for all
for all  is called a selective sum of
is called a selective sum of  one can find a maximal index
one can find a maximal index  so that
so that  . Now select
. Now select  if
if  and
and  otherwise. Then
otherwise. Then  and therefore the selected series converges by comparison with a convergent geometric series.
and therefore the selected series converges by comparison with a convergent geometric series.  where
where 
 and the convergent geometric series
and the convergent geometric series  Of course
Of course  so
so  but then for
but then for  we have
we have  . So
. So  . But
. But  because
because  . The next non-zero selection coefficient is
. The next non-zero selection coefficient is  as
as  .
. for
for  but not for
but not for  . So
. So  and
and  . So the first few
. So the first few  are
are  . Of course the gap between the
. Of course the gap between the  where
where  and
and  that lack a 9 as a digit. Then do a comparison test with a convergent geometric series, noting that every term
that lack a 9 as a digit. Then do a comparison test with a convergent geometric series, noting that every term  is less than or equal to
is less than or equal to  .
. numbers with no 9 as a digit (hint: consider 10-19, 20-29…80-89) so this means that we have
numbers with no 9 as a digit (hint: consider 10-19, 20-29…80-89) so this means that we have  numbers between 0 and 99 with no 9 as a digit.
numbers between 0 and 99 with no 9 as a digit.  numbers between 0 and
numbers between 0 and  with no 9 as a digit and
with no 9 as a digit and  between
between  and
and  with no 9 as a digit.
with no 9 as a digit.
 . Then to find the number of numbers without a 9 between
. Then to find the number of numbers without a 9 between  and
and  we get
we get  which then means we have
which then means we have  numbers between 0 and
numbers between 0 and  with no 9 as a digit. So our conjecture is proved by induction.
with no 9 as a digit. So our conjecture is proved by induction.



 and hence our selected sum is convergent.
and hence our selected sum is convergent.  we allowed
we allowed  terms to survive.
terms to survive.  terms between
terms between  to survive (
to survive ( fixed and positive) then we will have a convergent series. I’d be interested in seeing if there is an generalization of this.
fixed and positive) then we will have a convergent series. I’d be interested in seeing if there is an generalization of this.  and give it the discrete topology. The reason for choosing 0 and 2 to represent the elements will become clear later. Of course,
and give it the discrete topology. The reason for choosing 0 and 2 to represent the elements will become clear later. Of course,  is a compact metric space (with the discrete metric:
is a compact metric space (with the discrete metric:  if
if  .
. where each
where each  is homeomorphic to
is homeomorphic to  . It follows from the Tychonoff Theorem that
. It follows from the Tychonoff Theorem that 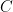 is compact, though we can prove this directly: Let
is compact, though we can prove this directly: Let  be any open cover for
be any open cover for  from this open cover; because we are using the product topology
from this open cover; because we are using the product topology  where each
where each  is a one or two point set. This means that the cardinality of
is a one or two point set. This means that the cardinality of  is at most
is at most  which requires at most
which requires at most  ) and uncountable.
) and uncountable.  by the sequence
by the sequence  where
where  . Then any open set containing
. Then any open set containing  is
is  and contains ALL points
and contains ALL points  where
where  for
for  . So all points of
. So all points of  there exists disjoint open sets
there exists disjoint open sets  . Proof of claim: if
. Proof of claim: if  (that is, a first
(that is, a first  ). Then
). Then ,
,
 . Note that is metric is well defined. Suppose
. Note that is metric is well defined. Suppose  . Then note
. Then note 
 is homeomorphic to
is homeomorphic to  . It follows that
. It follows that  is a continuous bijection with
is a continuous bijection with 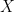 compact and
compact and  Hausdorff then
Hausdorff then 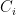 is a copy of
is a copy of  is homeomorphic to
is homeomorphic to  and
and  . A bijection is suggested by this diagram:
. A bijection is suggested by this diagram:
 :
: for
for  for
for  for
for 
 for
for 
 and
and  and denote the elements of
and denote the elements of  where
where  .
.  by
by

 is continuous, we will have shown that
is continuous, we will have shown that  be open;
be open;  . Then there is some
. Then there is some  for which
for which  . Then if
. Then if  denotes the
denotes the  component of
component of  (these are entries on or below the diagonal containing
(these are entries on or below the diagonal containing  depending on whether
depending on whether  is of the form
is of the form  where each
where each  is open in
is open in  . This is an open set in the product topology of
. This is an open set in the product topology of  .
.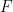 and describe it as follows:
and describe it as follows: (for those interested in the topology of manifolds this poses no restrictions since any manifold embeds in
(for those interested in the topology of manifolds this poses no restrictions since any manifold embeds in  for sufficiently high
for sufficiently high 
 be a strictly decreasing sequence of positive real numbers such that
be a strictly decreasing sequence of positive real numbers such that  .
. be some closed n-ball in
be some closed n-ball in  is a subset homeomorphic to a closed n-ball; we will use that convention throughout)
is a subset homeomorphic to a closed n-ball; we will use that convention throughout) be two disjoint closed n-balls in the interior of
be two disjoint closed n-balls in the interior of 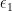 .
.
 be disjoint closed n-balls in the interior
be disjoint closed n-balls in the interior  and
and  be disjoint closed n-balls in the interior of
be disjoint closed n-balls in the interior of  , each of which (all 4 balls) have diameter less that
, each of which (all 4 balls) have diameter less that  . Let
. Let 

 for all
for all  and
and  will represent an infinite sequence of such
will represent an infinite sequence of such  .
. has been defined, we let
has been defined, we let  and
and  be disjoint closed n-balls of diameter less than
be disjoint closed n-balls of diameter less than  which lie in the interior of
which lie in the interior of  . Note that
. Note that  consists of
consists of  disjoint closed n-balls.
disjoint closed n-balls.  . Since these are compact sets with the finite intersection property (
. Since these are compact sets with the finite intersection property ( for all
for all  is nonempty by the finite intersection property. On the other hand, if
is nonempty by the finite intersection property. On the other hand, if  then
then  so choose
so choose  such that
such that  . Then
. Then  lie in different components of
lie in different components of  since the diameters of these components are less than
since the diameters of these components are less than  uniquely define the points of
uniquely define the points of 
 are open sets, as well as being closed.
are open sets, as well as being closed. be defined by
be defined by  . This is a bijection. To show continuity: consider the open set
. This is a bijection. To show continuity: consider the open set  . Under
. Under  hence
hence  , which can be thought of as the “compactification” of
, which can be thought of as the “compactification” of  ; basically one starts with
; basically one starts with  and declares that the neighborhoods of this new point will be generated by sets of the following form:
and declares that the neighborhoods of this new point will be generated by sets of the following form:  The reason we do this: we often study the complement of the embedded circle, and it is desirable to have a compact set as the complement.
The reason we do this: we often study the complement of the embedded circle, and it is desirable to have a compact set as the complement. ,
,  compact subsets can be thought of as selected finite unions and arbitrary intersections of closed intervals. In the higher dimensions, think of the finite union and arbitrary intersections of things like closed balls.
compact subsets can be thought of as selected finite unions and arbitrary intersections of closed intervals. In the higher dimensions, think of the finite union and arbitrary intersections of things like closed balls. is continuous, then if
is continuous, then if  is compact (either as a space, or in the subspace topology, if
is compact (either as a space, or in the subspace topology, if  is continuous over a compact subset
is continuous over a compact subset  then
then ![D =[a,b]](https://s0.wp.com/latex.php?latex=D+%3D%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) , a closed interval.
, a closed interval. is said to be an open cover of a space
is said to be an open cover of a space  and if
and if  a collection of open sets is said to be an open cover of
a collection of open sets is said to be an open cover of  A finite subcover is a finite subcollection of the open sets such that
A finite subcover is a finite subcollection of the open sets such that  .
. ![(\frac{3}{4}, 1] \cup^{\infty}_{n=1} [0, \frac{n}{n+1})](https://s0.wp.com/latex.php?latex=%28%5Cfrac%7B3%7D%7B4%7D%2C+1%5D+%5Ccup%5E%7B%5Cinfty%7D_%7Bn%3D1%7D+%5B0%2C+%5Cfrac%7Bn%7D%7Bn%2B1%7D%29+&bg=ffffff&fg=000000&s=0&c=20201002) is an open cover of
is an open cover of ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) in the subspace topology. A finite subcover (from this collection) would be
in the subspace topology. A finite subcover (from this collection) would be ![[0, \frac{4}{5}) \cup (\frac{3}{4}, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+%5Cfrac%7B4%7D%7B5%7D%29+%5Ccup+%28%5Cfrac%7B3%7D%7B4%7D%2C+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 we say that
we say that  is an open cover, then we can view this open cover as an open cover of the basis elements whose union is each open
is an open cover, then we can view this open cover as an open cover of the basis elements whose union is each open  . This open cover of basis elements has a finite subcover of basis elements..say
. This open cover of basis elements has a finite subcover of basis elements..say  . Then for each basis element, choose a single
. Then for each basis element, choose a single  for which
for which  . That is the required open subcover.
. That is the required open subcover.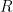 have the usual topology. Then the integers
have the usual topology. Then the integers  is not a compact subset; choose the open cover
is not a compact subset; choose the open cover  is an infinite cover with no finite subcover. In fact, ANY unbounded subset
is an infinite cover with no finite subcover. In fact, ANY unbounded subset  in the usual metric topology fails to be compact: for
in the usual metric topology fails to be compact: for  with
with  choose
choose  ; clearly this open cover can have no finite subcover.
; clearly this open cover can have no finite subcover.  and for every
and for every  choose
choose  open where
open where  . Now
. Now  is an open set which contains
is an open set which contains  Note that each
Note that each  is an open set which contains
is an open set which contains  which is disjoint from
which is disjoint from  ,
,  is open which means that
is open which means that  ) we need only show that a closed subset of a compact Hausdorff space is compact. That is easy enough to do: let
) we need only show that a closed subset of a compact Hausdorff space is compact. That is easy enough to do: let  is an open cover for
is an open cover for  where each
where each  does not cover
does not cover  does.
does.  . Since
. Since  is a finite set of points, only a finite number of them can be in
is a finite set of points, only a finite number of them can be in  . Then for each of these, select one open set in the open cover that contains the point; that is the finite subcover.
. Then for each of these, select one open set in the open cover that contains the point; that is the finite subcover. cover
cover  covers
covers  . Therefore
. Therefore  covers
covers ![[0, 1]](https://s0.wp.com/latex.php?latex=%5B0%2C+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) (and therefore any closed interval) is compact. This is (part) of the famous
(and therefore any closed interval) is compact. This is (part) of the famous  because at least one element of
because at least one element of 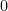 and therefore contains
and therefore contains  for some
for some  . Assume that
. Assume that  . Now suppose
. Now suppose  , that is
, that is  for some
for some  which means that
which means that  , which means that
, which means that  ; then because
; then because  where
where  . But since
. But since  then
then  and so
and so  . So if
. So if  then
then  is a finite subcover of
is a finite subcover of  which means that
which means that 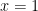 which means that the unit interval is compact.
which means that the unit interval is compact. . Note that the lower limit topology is strictly finer than the usual topology. Now in this topology:
. Note that the lower limit topology is strictly finer than the usual topology. Now in this topology: ![(0,1), [0,1), (0, 1]](https://s0.wp.com/latex.php?latex=%280%2C1%29%2C+%5B0%2C1%29%2C+%280%2C+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) are compact in the coarser usual topology, so there is no need to consider these). To see this, cover
are compact in the coarser usual topology, so there is no need to consider these). To see this, cover  and it is easy to see that this open cover has no finite subcover. In fact, with a bit of work, one can show that every compact subset is at most countable and nowhere dense; in fact, if
and it is easy to see that this open cover has no finite subcover. In fact, with a bit of work, one can show that every compact subset is at most countable and nowhere dense; in fact, if  where
where  .
. , is a set that consists of all subsets of
, is a set that consists of all subsets of  , then
, then  . Now is is no surprise that if the set
. Now is is no surprise that if the set  elements.
elements.  then the power set of
then the power set of 
 . Of course, listing the power sets would be, at least, cumbersome if not impossible! But there the binary notation really shows its value. Remember that the binary notation is a sequence of 0’s and 1’s where a 0 in the i’th slot means that element isn’t an element in a subset and a 1 means that it is.
. Of course, listing the power sets would be, at least, cumbersome if not impossible! But there the binary notation really shows its value. Remember that the binary notation is a sequence of 0’s and 1’s where a 0 in the i’th slot means that element isn’t an element in a subset and a 1 means that it is.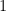 or
or  . This coincides with the “power set” concept as set membership is determined by being either “in” or “not in”. So, the set in the exponent can be thought of either as the indexing set and the base as the value each indexed value can take on (sequences, in the case that the exponent set is either finite or countably finite), OR this can be thought of as the set of all functions where the exponent set is the domain and the base set is the range.
. This coincides with the “power set” concept as set membership is determined by being either “in” or “not in”. So, the set in the exponent can be thought of either as the indexing set and the base as the value each indexed value can take on (sequences, in the case that the exponent set is either finite or countably finite), OR this can be thought of as the set of all functions where the exponent set is the domain and the base set is the range.  can be thought of as either set set of all possible sequences of positive integers, or, equivalently, the set of all functions of
can be thought of as either set set of all possible sequences of positive integers, or, equivalently, the set of all functions of  to
to  is the set of all real number sequences (i. e. the types of sequences we study in calculus), or, equivalently, the set of all real valued functions of the positive integers.
is the set of all real number sequences (i. e. the types of sequences we study in calculus), or, equivalently, the set of all real valued functions of the positive integers. it is best to think of this as the set of all functions
it is best to think of this as the set of all functions  , or equivalently, the set of all strings which are indexed by the real numbers and have real values.
, or equivalently, the set of all strings which are indexed by the real numbers and have real values.  where
where  . We use the form
. We use the form  (I am too lazy to use the traditional “p-hat” notation). First, note that the denominator works out to
(I am too lazy to use the traditional “p-hat” notation). First, note that the denominator works out to 
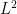 terms cancel and as far as the rest:
terms cancel and as far as the rest:





 and
and  :
:

 . In the limit, the first term decreases to
. In the limit, the first term decreases to  and the second goes to infinity.
and the second goes to infinity.  .
. . If we have
. If we have  (
( is positive, of course) we say that the convergence is LINEAR if
is positive, of course) we say that the convergence is LINEAR if  and
and  the inequality must be strict. If
the inequality must be strict. If  then we say that convergence is quadratic (regardless of
then we say that convergence is quadratic (regardless of  so one can think: “get new approximation by multiplying the old approximation by some constant less than one”. For example:
so one can think: “get new approximation by multiplying the old approximation by some constant less than one”. For example:  exhibits linear convergence to 0; that is a decent way to think about it.
exhibits linear convergence to 0; that is a decent way to think about it.  where
where  are constants strictly between 0 and 1. Of course, as
are constants strictly between 0 and 1. Of course, as  . To see how this formula is obtained,
. To see how this formula is obtained,  and if, say,
and if, say,  is much larger than
is much larger than  , then
, then  will be closer to
will be closer to  than
than  is to
is to  , hence more of this error will be subtracted away.
, hence more of this error will be subtracted away.  and showed how the Aitken process works there. Note: the spreadsheet round off errors start occurring at the
and showed how the Aitken process works there. Note: the spreadsheet round off errors start occurring at the  range; you can see that here.
range; you can see that here. 
 where
where  ,
, 