Reposted from my personal blog and from my Daily Kos Diary:
Quick Review
Excellent book. There are a few tiny technical errors (e. g., “non-linear” functions include exponential functions, but not all non-linear phenomena are exponential (e. g. power, root, logarithmic, etc.).
Also, experts have some (justified) quibbles with the book; you can read some of these concerning his chapter on climate change here and some on his discussion of hypothesis testing here.
But, aside from these, it is right on. Anyone who follows the news closely will benefit from it; I especially recommend it to those who closely follow science and politics and even sports.
It is well written and is designed for adults; it makes some (but reasonable) demands on the reader. The scientist, mathematician or engineer can read this at the end of the day but the less technically inclined will probably have to be wide awake while reading this.
Details
Silver sets you up by showing examples of failed predictions; perhaps the worst of the lot was the economic collapse in the United States prior to the 2008 general elections. Much of this was due to the collapse of the real estate market and falling house/property values. Real estate was badly overvalued, and financial firms made packages of investments whose soundness was based on many mortgages NOT defaulting at the same time; it was determined that the risk of that happening was astronomically small. That was wrong of course; one reason is that the risk of such an event is NOT described by the “normal” (bell shaped) distribution but rather by one that allows for failure with a higher degree of probability.
There were more things going on, of course; and many of these things were difficult to model accurately just due to complexity. Too many factors makes a model unusable; too few means that the model is worthless.
Silver also talks about models providing probabilistic outcomes: example saying that the GDP will be X in year Y is unrealistic; what we really should say that the probability of the GDP being X plus/minus “E” is Z percent.
Next Silver takes on pundits. In general: they don’t predict well; they are more about entertainment than anything else. Example: look at the outcome of the 2012 election; the nerds were right; the pundits (be they NPR or Fox News pundits) were wrong. NPR called the election “razor tight” (it wasn’t); Fox called it for the wrong guy. The data was clear and the sports books new this, but that doesn’t sell well, does it?
Now Silver looks at baseball. Of course there are a ton of statistics here; I am a bit sorry he didn’t introduce Bayesian analysis in this chapter though he may have been setting you up for it.
Topics include: what does raw data tell you about a player’s prospects? What role does a talent scout’s input have toward making the prediction? How does a baseball players hitting vary with age, and why is this hard to measure from the data?
The next two chapters deal with predictions: earthquakes and weather. Bottom line: we have statistical data on weather and on earthquakes, but in terms of making “tomorrow’s prediction”, we are much, much, much further along in weather than we are on earthquakes. In terms of earthquakes, we can say stuff like “region Y has a X percent chance of an earthquake of magnitude Z within the next 35 years” but that is about it. On the other hand, we are much better about, say, making forecasts of the path of a hurricane, though these are probabilistic:

In terms of weather: we have many more measurements.
But there IS the following: weather is a chaotic system; a small change in initial conditions can mean to a large change in long term outcomes. Example: one can measure a temperature at time t, but only to a certain degree of precision. The same holds for pressure, wind vectors, etc. Small perturbations can lead to very different outcomes. Solutions aren’t stable with respect to initial conditions.
You can see this easily: try to balance a pen on its tip. Physics tells us there is a precise position at which the pen is at equilibrium, even on its tip. But that equilibrium is so unstable that a small vibration of the table or even small movement of air in the room is enough to upset it.
In fact, some gambling depends on this. For example, consider a coin toss. A coin toss is governed by Newton’s laws for classical mechanics, and in principle, if you could get precise initial conditions and environmental conditions, the outcome shouldn’t be random. But it is…for practical purposes. The same holds for rolling dice.
Now what about dispensing with models and just predicting based on data alone (not regarding physical laws and relationships)? One big problem: data is noisy and is prone to be “overfitted” by a curve (or surface) that exactly matches prior data but is of no predictive value. Think of it this way: if you have n data points in the plane, there is a polynomial of degree n-1 that will fit the data EXACTLY, but in most cases have a very “wiggly” graph that provides no predictive value.
Of course that is overfitting in the extreme. Hence, most use the science of the situation to posit the type of curve that “should” provide a rough fit and then use some mathematical procedure (e. g. “least squares”) to find the “best” curve that fits.
The book goes into many more examples: example: the flu epidemic. Here one finds the old tug between models that are too simplistic to be useful for forecasting and too complicated to be used.
There are interesting sections on poker and chess and the role of probability is discussed as well as the role of machines. The poker chapter is interesting; Silver describes his experience as a poker player. He made a lot of money when poker drew lots of rookies who had money to spend; he didn’t do as well when those “bad” players left and only the most dedicated ones remained. One saw that really bad players lost more money than the best players won (not that hard to understand). He also talked about how hard it was to tell if someone was really good or merely lucky; sometimes this wasn’t perfectly clear after a few months.
Later, Silver discusses climate change and why the vast majority of scientists see it as being real and caused (or made substantially worse) by human activity. He also talks about terrorism and enemy sneak attacks; sometimes there IS a signal out there but it isn’t detected because we don’t realize that there IS a signal to detect.
However the best part of the book (and it is all pretty good, IMHO), is his discussion of Bayes law and Bayesian versus frequentist statistics. I’ve talked about this.
I’ll demonstrate Bayesian reasoning in a couple of examples, and then talk about Bayesian versus frequentist statistical testing.
Example one: back in 1999, I went to the doctor with chest pains. The doctor, based on my symptoms and my current activity level (I still swam and ran long distances with no difficulty) said it was reflux and prescribed prescription antacids. He told me this about a possible stress test: “I could stress test you but the probability of any positive being a false positive is so high, we’d learn nothing from the test”.
Example two: suppose you are testing for a drug that is not widely used; say 5 percent of the population uses it. You have a test that is 95 percent accurate in the following sense: if the person is really using the drug, it will show positive 95 percent of the time, and if the person is NOT using the drug, it will show positive only 5 percent of the time (false positive).
So now you test 2000 people for the drug. If Bob tests positive, what is the probability that he is a drug user?
Answer: There are 100 actual drug users in this population, so you’d expect 100*.95 = 95 true positives. There are 1900 non-users and 1900*.05 = 95 false positives. So there are as many false positives as true positives! The odds that someone who tests positive is really a user is 50 percent.
Now how does this apply to “hypothesis testing”?
Consider basketball. You know that a given player took 10 free shots and made 4. You wonder: what is the probability that this player is a competent free throw shooter (given competence is defined to be, say, 70 percent).
If you just go by the numbers that you see (true: n = 10 is a pathetically small sample; in real life you’d never infer anything), well, the test would be: given the probability of making a free shot is 70 percent, what is the probability that you’d see 4 (or fewer) made free shots out of 10?
Using a calculator (binomial probability calculator), we’d say there is a 4.7 percent chance we’d see 4 or fewer free shots made if the person shooting the shots was a 70 percent shooter. That is the “frequentist” way.
But suppose you found out one of the following:
1. The shooter was me (I played one season in junior high and some pick up ball many years ago…infrequently) or
2. The shooter was an NBA player.
If 1 was true, you’d believe the result or POSSIBLY say “maybe he had a good day”.
If 2 was true, then you’d say “unless this player was chosen from one of the all time worst NBA free throw shooters, he probably just had a bad day”.
Bayesian hypothesis testing gives us a way to make and informed guess. We’d ask: what is the probability that the hypothesis is true given the data that we see (asking the reverse of what the frequentist asks). But to do this, we’d have to guess: if this person is an NBA player, what is the probability, PRIOR to this 4 for 10 shooting, that this person was 70 percent or better (NBA average is about 75 percent). For the sake of argument, assume that there is a 60 percent chance that this person came from the 70 percent or better category (one could do this by seeing the percentage of NBA players shooing 70 percent of better). Assign a “bad” percentage as 50 percent (based on the worst NBA free throw shooters): (the probability of 4 or fewer made free throws out of 10 given a 50 percent free throw shooter is .377)
Then we’d use Bayes law: (.0473*.6)/(.0473*.6 + .377*.4) = .158. So it IS possible that we are seeing a decent free throw shooter having a bad day.
This has profound implications in science. For example, if one is trying to study genes versus the propensity for a given disease, there are a LOT of genes. Say one tests 1000 genes of those who had a certain type of cancer and run a study. If we accept p = .05 (5 percent) chance of having a false positive, we are likely to have 50 false positives out of this study. So, given a positive correlation between a given allele and this disease, what is the probability that this is a false positive? That is, how many true positives are we likely to have?
This is a case in which we can use the science of the situation and perhaps limit our study to genes that have some reasonable expectation of actually causing this malady. Then if we can “preassign” a probability, we might get a better feel if a positive is a false one.
Of course, this technique might induce a “user bias” into the situation from the very start.
The good news is that, given enough data, the frequentist and the Bayesian techniques converge to “the truth”.
Summary Nate Silver’s book is well written, informative and fun to read. I can recommend it without reservation.

 . On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0.
. On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0. , the probability of detection of a cancer be given by
, the probability of detection of a cancer be given by  and the probability of a false positive be given by
and the probability of a false positive be given by 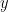 . Then the probability of a person actually having breast cancer, given a positive test is given by:
. Then the probability of a person actually having breast cancer, given a positive test is given by: ; this gives us something to optimize. The partial derivatives are:
; this gives us something to optimize. The partial derivatives are: . Note that
. Note that  is positive since
is positive since  is less than 1 (in fact, it is small). We also know that the critical point
is less than 1 (in fact, it is small). We also know that the critical point  is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if
is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if  for us, and
for us, and  . Note that
. Note that  and
and  . Hence an increase in the accuracy of the
. Hence an increase in the accuracy of the  leads to an improvement of about .00136 (substitute
leads to an improvement of about .00136 (substitute  into the expression for
into the expression for  and multiply by
and multiply by  . Similarly an improvement (decrease) of
. Similarly an improvement (decrease) of  leads to an improvement of .013609.
leads to an improvement of .013609. ) we get
) we get  . Now let’s change:
. Now let’s change:  leads to
leads to 
 we get
we get 
 So the false positive rate is 83.72 percent.
So the false positive rate is 83.72 percent. , so while the true detections go up, the false positives also goes up!
, so while the true detections go up, the false positives also goes up! . Here:
. Here:  is the probability of event A occurring given that B occurs and P(A) is the probability of event A occurring. So in our case, we were answering the question: given a positive mammogram, what is the probability of actually having breast cancer? This is denoted by P(A|B) . We knew: P(B|A) which is the probability of having a positive reading given that one has breast cancer and P(B|not(A)) is the probability of getting a positive reading given that one does NOT have cancer. So for us:
is the probability of event A occurring given that B occurs and P(A) is the probability of event A occurring. So in our case, we were answering the question: given a positive mammogram, what is the probability of actually having breast cancer? This is denoted by P(A|B) . We knew: P(B|A) which is the probability of having a positive reading given that one has breast cancer and P(B|not(A)) is the probability of getting a positive reading given that one does NOT have cancer. So for us: and
and  .
. . So, in this population, about 16.1 percent of the positives will be “false positives”, even though the test is 99 percent accurate!
. So, in this population, about 16.1 percent of the positives will be “false positives”, even though the test is 99 percent accurate! respectively, where the probability mass function is adjusted for the different values of n .
respectively, where the probability mass function is adjusted for the different values of n . )
) and we’ve already calculated P(B|A) for the various cases. We need to make a SECOND assumption: what does event not(A) mean? Given what I’ve said, one might say not(A) is someone who shoots, say, 40 percent (to make him among the worst possible in the NBA). Then for the various cases, we calculate
and we’ve already calculated P(B|A) for the various cases. We need to make a SECOND assumption: what does event not(A) mean? Given what I’ve said, one might say not(A) is someone who shoots, say, 40 percent (to make him among the worst possible in the NBA). Then for the various cases, we calculate  respectively.
respectively.
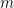 represent the mass of the object;
represent the mass of the object;  implies that
implies that  which isn’t that important; we’ll just use
which isn’t that important; we’ll just use  . By elementary integration, obtain
. By elementary integration, obtain  and integrate again to obtain
and integrate again to obtain  which has parametric equations
which has parametric equations  which has a “sideways parabola” as a graph.
which has a “sideways parabola” as a graph. 
 . The first term is thrust and is against the direction of acceleration. So we have:
. The first term is thrust and is against the direction of acceleration. So we have: which, upon integration, implies that
which, upon integration, implies that  and so we see that the rocket continues to speed up at a constant acceleration.
and so we see that the rocket continues to speed up at a constant acceleration. 