Think back to how you introduced the sine and cosine functions on the real line. Ok, you didn’t do it quite this way, but what you did, in effect, is to define  and
and  and then use “elementary trigonometry” to relate the “angle”
and then use “elementary trigonometry” to relate the “angle”  to the arc length subtended on the circle
to the arc length subtended on the circle  . One notes that the map
. One notes that the map  defined by
defined by  has period
has period 

Note: the direction “to the right” on the real line is taken to be “counterclockwise” on the circle (red arrows).
Skip if you haven’t had a topology class
The top line is known as the “universal covering space” for the circle. The reason for the terminology has to do with topology. Depending on how long ago you had your topology course, you might remember that the fundamental group of the real line is trivial and the associated group of deck transformations is infinite cyclic (generated by the map  ). One then shows that the fundamental group of the circle is the quotient of the group of deck transformations with the fundamental group of the real line; hence the fundamental group of the circle is infinite cylic.
). One then shows that the fundamental group of the circle is the quotient of the group of deck transformations with the fundamental group of the real line; hence the fundamental group of the circle is infinite cylic.
Resume if you haven’t had a topology class
Notice the following: if one, say, “takes a walk” along the line in the direction of the red arrow, the action of the “covering mapping” is to take the same walk in the counter clockwise direction of the circle. That is, the covering action does the following: a walk on the line in the direction of points  corresponds to a walk on the circle
corresponds to a walk on the circle  . That is, walking from
. That is, walking from  to
to  corresponds to a complete lap of the circle.
corresponds to a complete lap of the circle.

(that is, on the real line,  )
)
Now note the following: for BOTH the line and the circle, the direction is well defined. “To the right” on the real line” is “counter clockwise” on the circle.
However: on the real line, it makes perfect sense to say that is “before”  which is “before”
which is “before”  which is “before” and so on; this is merely:
which is “before” and so on; this is merely:
 . This is order is valid no matter where one starts on the line.
. This is order is valid no matter where one starts on the line.
However, this “universal ordering” makes no sense on the circle, UNLESS one specifies a start point. True, one moves from  to
to  to
to 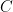 and back to again..but if one started at and started to walk, it would appear that came AFTER and not before.
and back to again..but if one started at and started to walk, it would appear that came AFTER and not before.
So what?
A friend posted this to her facebook wall:
This quirky animation from CraveFX starts off innocently enough, a janitorial worker mops up a leaky refrigerator and then picks up a coin on the ground. It’s not until you see what causes the refrigerator to leak and why the coin is on the ground that you realize that you’re watching an intricate moving puzzle piece before your eyes. The characters are stuck in an infinite loop caused by another character in their own infinite loop. It’s chaotic and great and hard to keep up with.
The video is below. Now the question: “what action occurred before what other action”? and the answer is “it depends on when you started watching”. The direction of time corresponds to the red arrows in the above diagrams; THAT is well defined. Why? The reason is the Second Law of Thermodynamics; spills do NOT reverse themselves, hence the direction is set in stone, so to speak. But as far as order, it depends ON WHEN THE VIEWER STARTED WATCHING.
Anyway, this video reminded me of covering spaces.












 is a random variable with a probability distribution as given by the null hypothesis, and
is a random variable with a probability distribution as given by the null hypothesis, and  is the observation,
is the observation,  .
. . So that is the p-value of that particular experiment. That is, IF the coin really were fair, you’d expect to 65 or more heads .1716 percent of the time.
. So that is the p-value of that particular experiment. That is, IF the coin really were fair, you’d expect to 65 or more heads .1716 percent of the time.

 described as follows:
described as follows:  Now the projection map to the
Now the projection map to the  plane is given by
plane is given by  and the image set is
and the image set is  which is a disk (in the yellow).
which is a disk (in the yellow).  plane is given by
plane is given by  and the image is
and the image is  which is a rectangle (in the blue).
which is a rectangle (in the blue). 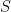 . In fact, both of these projections, taken together, do not determine the object. For example: the “hollow can” in the shape of our
. In fact, both of these projections, taken together, do not determine the object. For example: the “hollow can” in the shape of our  to be a manifold of either 2 or 3 dimensions, or some other criteria. But THAT would be adding more information to the mix and thereby, in a sense, providing yet another projection map.
to be a manifold of either 2 or 3 dimensions, or some other criteria. But THAT would be adding more information to the mix and thereby, in a sense, providing yet another projection map. values as well as the correlation coefficient and the regression coefficients.
values as well as the correlation coefficient and the regression coefficients. 



