One question on my last exam: find the Laurent series for 


I am truly evil.
One question on my last exam: find the Laurent series for
I am truly evil.
This is nothing new; it is an example for undergraduates.
Consider the set 






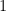
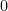
Now consider the function 





What is even better: 

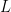
And, given 
So, 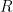

Upshot: when one asks “is F a linear transformation or not”, one needs information about not only the domain set but also the vector space operations.
Calculus III: we are talking about polar curves. I give the usual lesson about how to graph 




Question: “does that mean it is impossible to have a graph with 6 petals then”? 🙂
Yes, one can have intersecting petals and one try: 

Yes, I was glad when we hired people with applied mathematics expertise; though I am enjoying teaching numerical analysis, it is killing me. My training is in pure mathematics (in particular, topology) and so class preparation is very intense for me.
But I so love being able to show the students the very real benefits that come from the theory.
Here is but one example: right now, I am talking about numerical solutions to “stiff” differential equations; basically, a differential equation is “stiff” if the magnitude of the differential equation is several orders of magnitude larger than the magnitude of the solution.
A typical example is the differential equation 

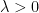


One uses such an equation to test a method to see if it works well for stiff differential equations. One such method is the Euler method: 





So for 

![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
I gave the following demonstration in class today:
Now, of course, even a C student in calculus II would be able to solve this exactly using 
But what about the “just bully” numerical methods we’ve learned?
Romberg integration fails miserably, at least at first:

(for those who don’t know about Romberg integration: the first column gives trapezoid rule approximations, the second gives Simpson’s rule approximations and the third gives Boole’s rule; the value of 
I said “at first” as if one goes to, say, 20 rows, one can start to get near the correct answer.
Adaptive quadrature: is even a bigger fail:

The problem here is that this routine quits when the refined Simpson’s rule approximation agrees with the less refined approximation (to within a certain tolerance), and here, the approximations are both zero, hence there is perfect agreement, very early in the process.
So, what to do?
One should note, of course, that the integrand is positive except for a finite number of points where it is zero. Hence one knows right away that the results are bogus.
One quick way to get closer: just tweak the limits of integration by a tiny amount and calculate, say, 

The point: the integration routines cannot replace thinking.
This is making the rounds on social media:

Now a good explanation as to what is going on can be found here; it is written by an experienced high school math teacher.
I’ll give my take on this; I am NOT writing this for other math professors; they would likely be bored by what I am about to say.
My take
First of all, I am NOT defending the mathematics standards of Common Core. For one: I haven’t read them. Another: I have no experience teaching below the college level. What works in my classroom would probably not work in most high school and grade school classrooms.
But I think that I can give some insight as to what is going on with this example (in the photo).
When one teaches mathematics, one often teaches BOTH how to calculate and the concepts behind the calculation techniques. Of course, one has to learn the calculation technique; no one (that I know) disputes that.
What is going on in the photo
The second “calculation” is an exercise designed to help students learn the concept of subtraction and NOT “this is how you do the calculation”.
Suppose one wants to show the students that subtracting two numbers yields “the distance on the number line between those numbers”. So, “how far away from 12 is 32? Well, one moves 3 units to get to 15, then 5 to get to 20. Now that we are at 20 (a multiple of 10), it is easy to move one unit of 10 to get to 30, then 2 more units to get to 32. So we’ve moved 20 units total.
Think of it this way: in the days prior to google maps and gps systems, imagine you are taking a trip from, say, Morton, IL to Chicago and you wanted to take interstate highways all of the way. You wanted to figure the mileage.
You notice (I am making these numbers up) that the “distance between big cities” map lists 45 miles from Peoria to Bloomington and 150 miles from Bloomington to Chicago. Then you look at the little numbers on the map to see that Morton is between Peoria and Bloomington: 10 miles away from Peoria.
So, to find the distance, you calculate (45-10) + 150 = 185 miles; you used the “known mileages” as guide posts and used the little map numbers as a guide to get from the small town (Morton) to the nearest city for which the “table mileage” was calculated.
That is what is going on in the photo.
Why the concept is important
There are many reasons. The “distance between nodes” concept is heavily used in graph theory and in operations research. But I’ll give a demonstration in numerical methods:
Suppose one needs a numerical approximation of 
But one notices that the integrand is periodic; there is no need to integrate along the entire range.
Note that there are 7 complete periods of 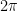

In fact, why not approximate 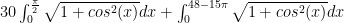
The concept of calculating distance in terms of set segment lengths comes in handy.
Or, one can think of it this way
When we teach derivatives, we certainly teach how to calculate using the standard differentiation rules. BUT we also teach the limit definition as well, though one wouldn’t use that definition in the middle of, say, “find the maximum and minimum of 
![[\frac{1}{4}, 3]](https://s0.wp.com/latex.php?latex=%5B%5Cfrac%7B1%7D%7B4%7D%2C+3%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
But if you saw some kid’s homework and saw 
I’ll go ahead and work with the common 3 point derivative formulas:
This is the three-point endpoint formula: (assuming that 

The three point midpoint formula is:

The derivation of these formulas: can be obtained from either using the Taylor series centered at 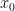
That isn’t the point of this note though.
The point: how can one demonstrate, by an example, the role the error term plays.
I suggest trying the following: let 

1. 
2. 
Note one: the three point estimates for the derivatives will be exactly the same for both 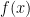

Note two: the “errors” will be very, very different. It is easy to see why: look at the third derivative term: for
The graphs shows the story.

Clearly, the 3 point derivative estimates cannot distinguish these two functions for these “sample values” of 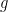

In numerical analysis we are covering “approximate differentiation”. One of the formulas we are using: 

![[x_0 -h, x_0 + h]](https://s0.wp.com/latex.php?latex=%5Bx_0+-h%2C+x_0+%2B+h%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
The derivation can be done in a couple of ways: one can either use the degree 2 Lagrange polynomial through 



But that isn’t the issue that I want to talk about here.
The issue: “what should we use for 



So, it is an easy algebraic exercise to show that:





It is an easy calculus exercise (“take the derivative and set equal to zero and check concavity” easy) to see that this error bound is a minimum when 
Now, of course, it is helpful to get a “ball park” estimate for what 
That is: obtain an estimate of 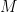
Here are a couple of examples: one uses Excel and one uses MATLAB. I used 


Here is the Excel output for 
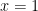

In the 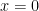

So, in the first case, 


Note: one can also approach 
Now we turn to MATLAB and here we do something slightly different: we graph the error for different values of 

 . By design,
. By design, 

Now, the small error scale makes things hard to read, so we turn to using the log scale, this time on the 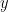

 and sure enough, you can see where the peak is: about
and sure enough, you can see where the peak is: about 
During the linear regression section of our statistics course, we do examples with spreadsheets. Many spreadsheets have data processing packages that will do linear regression and provide output which includes things such as confidence intervals for the regression coefficients, the 
The purpose of this note is NOT to provide an introduction to the type of ANOVA that is used in linear regression (one can find a brief introduction here or, of course, in most statistics textbooks) but to show a simple example using the “random number generation” features in the Excel (with the data analysis pack loaded into it).
I’ll provide some screen shots to show what I did.
If you are familiar with Excel (or spread sheets in general), this note will be too slow-paced for you.
Brief Background (informal)
I’ll start the “ANOVA for regression” example with a brief discussion of what we are looking for: suppose we have some data which can be thought of as a set of 
It turns out that the “sum of squares” 


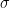

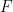


For example: if the regression line fit the data perfectly, the SSE terms would be zero and the SSR term would equal the SS term as the predicted y values would be the y values. Hence the ratio of (SSR/constant) over (SSE/constant) would be infinite.
That is, the ratio that we use roughly measures the percentage of variation of the y values that comes from the regression line verses the percentage that comes from the error from the regression line. Note that it is customary to denote SSE/(n-2) by MSE and SSR/1 by MSR. (Mean Square Error, Mean Square Regression).
The smaller the numerator relative to the denominator the less that the regression explains.
The following examples using Excel spread sheets are designed to demonstrate these concepts.
The examples are as follows:
Example one: a perfect regression line with “perfect” normally distributed residuals (remember that the usual hypothesis test on the regression coefficients depend on the residuals being normally distributed).
Example two: a regression line in which the y-values have a uniform distribution (and are not really related to the x-values at all).
Examples three and four: show what happens when the regression line is “perfect” and the residuals are normally distributed, but have greater standard deviations than they do in Example One.
First, I created some x values and then came up with the line 

This is the result after copying:

Now we need to add some residuals to give us a non-zero SSE. This is where the “random number generation” feature comes in handy. One goes to the data tag and then to “data analysis”

and clicks on “random number generation”:

This gives you a dialogue box. I selected “normal distribution”; then I selected “0” of the mean and “1” for the standard deviation. Note: the assumption underlying the confidence interval calculation for the regression parameter confidence intervals is that the residuals are normally distributed and have an expected value of zero.

I selected a column for output (as many rows as x-values) which yields a column:

Now we add the random numbers to the column “fake” to get a simulated set of y values:

That yields the column Y as shown in this next screenshot. Also, I used the random number generator to generate random numbers in another column; this time I used the uniform distribution on [0,54]; I wanted the “random set of potential y values” to have roughly the same range as the “fake data” y-values.

Y holds the “non-random” fake data and YR holds the data for the “Y’s really are randomly distributed” example.

I then decided to generate two more “linear” sets of data; in these cases I used the random number generator to generate normal residuals of larger standard deviation and then create Y data to use as a data set; the columns or residuals are labeled “mres” and “lres” and the columns of new data are labeled YN and YVN.
Note: in the “linear trend data” I added the random numbers to the exact linear model y’s labeled “fake” to get the y’s to represent data; in the “random-no-linear-trend” data column I used the random number generator to generate the y values themselves.
Now it is time to run the regression package itself. In Excel, simple linear regression is easy. Just go to the data analysis tab and click, then click “regression”:

This gives a dialogue box. Be sure to tell the routine that you have “headers” to your columns of numbers (non-numeric descriptions of the columns) and note that you can select confidence intervals for your regression parameters. There are other things you can do as well.

You can select where the output goes. I selected a new data sheet.

Note the output: the 


This is what a plot of the calculated regression line with the “fake data” looks like:

Yes, this is unrealistic, but this is designed to demonstrate a concept. Now let’s look at the regression output for the “uniform y values” (y values generated at random from a uniform distribution of roughly the same range as the “regression” y-values):

Note: 

A plot looks like:

The next two examples show what happens when one “cooks” up a regression line with residuals that are normally distributed, have mean equal to zero, but have larger standard deviations. Watch how the





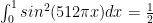




Moving from “young Turk” to “old f***”
Today, one of our hot “young” (meaning: new here) mathematicians came to me and wanted to inquire about a course switch. He noted that his two course load included two different courses (two preparations) and that I was teaching different sections of the same two courses…was I interested in doing a course swap so that he had only one preparation (he is teaching 8 hours) and I’d only have two?
I said: “when I was your age, I minimized the number of preparations. But at my age, teaching two sections of the same low level course makes me want to bash my head against the wall”. That is, by my second lesson of the same course in the same day; I just want to be just about anywhere else on campus; I have no interest, no enthusiasm, etc.
I specifically REQUESTED 3 preparations to keep myself from getting bored; that is what 24 years of teaching this stuff does to you.
COMMENTARY
Every so often, someone has the grand idea to REFORM the teaching of (whatever) and the “reformers” usually get at least a few departments to go along with it.
The common thing said is that it gets professors to reexamine their teaching of (whatever).
But I wonder if many try these things….just out of pure boredom. Seriously, read the buzzwords of the “reform paper” I linked to; there is really nothing new there.