First of all, I’ll have to read this 2016 article.
But: it is no secret that higher education in the US is in turmoil, at least at the non-elite universities. Some colleges are closing and others are experiencing cut backs due to high operating losses.
This little not will not attempt to explain the problems of why education has gotten so expensive, though things like: reduction of government subsidies, increased costs for technology (computers, wifi, learning management systems), unfunded mandates (e. g. accommodations for an increasing percentage of students with learning disabilities) and staff to handle helicopter parents are all factors adding to increased costs.
And so, many universities are more tuition dependent than ever before, and while the sticker price is high, many (most in many universities) are given steep discounts.
And so, higher administration is trying to figure out what to offer: they need to bring in tuition dollars.
Now about math: our number of majors has dropped, and much, if not most, of the drop comes from math education: teaching is not a popular occupation right now, for many reasons.
Things like this do not help attract student to teacher education programs:
One thing that hurts enrollment in upper division math courses is that higher math has prerequisites. Of course, many (most?) pure math courses do not appear to have immediate application to other fields (though they often do). And, let’s face it: math is hard. The ideas are very dense.
So, it is my feeling that the math major..one that requires two semesters of abstract algebra and two semesters of analysis, is probably on the way out, at least at non-elite schools. I think it will survive at Ivy caliber schools, MIT, Stanford, and the flagship R-1 schools.
As far as the rest of us: it absolutely hurts my heart to say this, but I feel that for our major to survive at a place like mine, we’ll have to allow for at least some upper division credit to come from “theory of interest”, “math for data science”, etc. type courses…and perhaps allow for mathy electives from other disciplines. I see us as having to become a “mathematical sciences” type program…or not existing at all.
Now for the West Virginia situation (and they probably won’t be the last):
I went on their faculty page and noted that they had 31 Associate/Full professors; the remainder appeard to be “instructors” or “assistant professors of instruction” and the like. So while I do not have any special information, it appears that they are cutting the non-tenured..the ones who did a lot (most?) of the undergraduate teaching.
Now for the uninitiated: keeping current with research at the R-1 level is, in and of itself, is a full time job. Now I am NOT one of those who says that “researchers are bad teachers” (that is often untrue) but I can say that teaching full loads (10-12 hours of undergraduate classes) is a very different job than running a graduate seminar, advising graduate students, researching, and getting NSF grants (often a prerequisite for getting tenure to begin with.
So, a lot of professor’s lives are going to change, not only for those being let go, but also for those still left. I’d imagine that some of the research professors might leave and have their place taken by the teaching faculty who are due to be cut, but that is pure speculation on my part.
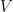 be a vector space with some scalars
be a vector space with some scalars 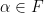 . I’ll assume you know what a spanning set is and what it means to be linearly independent.
. I’ll assume you know what a spanning set is and what it means to be linearly independent.  , say,
, say,  . The coefficients are real numbers and the set of scalars
. The coefficients are real numbers and the set of scalars 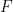 will be the real numbers. (note: the set of scalars are sometimes called a “field”). So one basis (there are many others) is
will be the real numbers. (note: the set of scalars are sometimes called a “field”). So one basis (there are many others) is 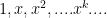 and since there is no limit to the degree of the polynomial, the basis must have an infinite number of vectors.
and since there is no limit to the degree of the polynomial, the basis must have an infinite number of vectors.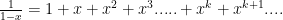 (
( ) this definition depends on infinite series, which in turn requires a limiting process, which then requires a notion of “being close” (the delta- epsilon stuff) In some vector spaces there IS a way to do that, but you need the notion of “inner product” to define size and closeness (remember the dot product from calculus?) and then you can introduce ideas like convergence of an infinite sum. For example, check out
) this definition depends on infinite series, which in turn requires a limiting process, which then requires a notion of “being close” (the delta- epsilon stuff) In some vector spaces there IS a way to do that, but you need the notion of “inner product” to define size and closeness (remember the dot product from calculus?) and then you can introduce ideas like convergence of an infinite sum. For example, check out  on
on ![[0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . The scalars will be the real numbers. Now this is a weird vector space. Remember that what is included are things like polynomials, rational functions without roots in
. The scalars will be the real numbers. Now this is a weird vector space. Remember that what is included are things like polynomials, rational functions without roots in 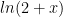 and even piecewise defined functions whose graphs meet up at all points. And that is only the beginning.
and even piecewise defined functions whose graphs meet up at all points. And that is only the beginning.  . Let
. Let  denote the span of this vector. Now if the span is not all of
denote the span of this vector. Now if the span is not all of 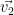 not in the span. Let the span of
not in the span. Let the span of  be denoted by
be denoted by  . If
. If  we have our basis, we are done. Otherwise, we continue on.
we have our basis, we are done. Otherwise, we continue on.  we obtain a chain of nested subsets
we obtain a chain of nested subsets 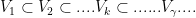 and this chain has an upper bound, namely
and this chain has an upper bound, namely 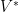 .
. 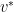 are linearly independent and span all of
are linearly independent and span all of  .
.
 and, by construction, are linearly dependent (order these vectors and remember how we got them: we added vectors by adding what was NOT in the span of the previous vectors.
and, by construction, are linearly dependent (order these vectors and remember how we got them: we added vectors by adding what was NOT in the span of the previous vectors. is NOT in the span. Then let
is NOT in the span. Then let 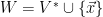 . This is then in the chain and contains
. This is then in the chain and contains 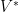 which violates the fact that
which violates the fact that  is maximal.
is maximal. 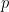 ) and then determines a confidence interval for said
) and then determines a confidence interval for said 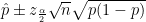
 with variance zero! Needless to say that trend is highly unlikely to continue.
with variance zero! Needless to say that trend is highly unlikely to continue. 
 where
where  for a make and
for a make and  for a miss.
for a miss. 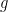 after updating with the data; we’ll call that
after updating with the data; we’ll call that  .
.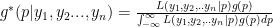
 are set to the observed values. In our case, all are 1 with
are set to the observed values. In our case, all are 1 with  .
.  and if one uses
and if one uses  , this works very well. Now because the mean will be
, this works very well. Now because the mean will be  and
and  given the required mean and variance, one can work out
given the required mean and variance, one can work out  algebraically.
algebraically.  , if we set
, if we set  we get
we get 
 which is just a beta distribution with new
which is just a beta distribution with new  .
. leads to
leads to 
 .
.

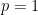 with a confidence interval of zero width.
with a confidence interval of zero width.
 . In fact, Bird’s lifetime free throw shooting percentage is .882, which is well within this 91.6 percent credible interval, based on sampling from this one freakish streak.
. In fact, Bird’s lifetime free throw shooting percentage is .882, which is well within this 91.6 percent credible interval, based on sampling from this one freakish streak.  centered at
centered at  which converges on the punctured disk
which converges on the punctured disk  . And yes, about half the class missed it.
. And yes, about half the class missed it. 
 and evaluate the latter integral as follows:
and evaluate the latter integral as follows: (this follows from restricting
(this follows from restricting  to the unit circle
to the unit circle  and setting
and setting  and then obtaining a rational function of
and then obtaining a rational function of  And then the integral is transformed to:
And then the integral is transformed to:
 which means
which means  but only the roots
but only the roots  lie inside the unit circle.
lie inside the unit circle.

 and
and 
 so by Cauchy’s theorem
so by Cauchy’s theorem 
 and divide by two but instead just went with:
and divide by two but instead just went with: where
where 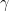 is the upper half of
is the upper half of  ? Well,
? Well,  has a primitive away from those poles so isn’t this just
has a primitive away from those poles so isn’t this just  , right?
, right?  because the integrand is an odd function?
because the integrand is an odd function?  taken in the standard direction and
taken in the standard direction and  if you do this property (hint: set
if you do this property (hint: set ![z(t) = e^{it}, dz = ie^{it}, t \in [0, \pi]](https://s0.wp.com/latex.php?latex=z%28t%29+%3D+e%5E%7Bit%7D%2C+dz+%3D+ie%5E%7Bit%7D%2C+t+%5Cin+%5B0%2C+%5Cpi%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . Now attempt to integrate from 1 to -1 along the real axis. What goes wrong? What goes wrong is exactly what I missed in the above example.
. Now attempt to integrate from 1 to -1 along the real axis. What goes wrong? What goes wrong is exactly what I missed in the above example.  though, of course, there is some choice in what
though, of course, there is some choice in what  is; any anti-derivative will do. Well, sort of.
is; any anti-derivative will do. Well, sort of. where
where  is the random variable that denotes the number of years longer a person aged
is the random variable that denotes the number of years longer a person aged  is a probability distribution function with density function
is a probability distribution function with density function  and if we assume that
and if we assume that 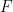 is smooth and
is smooth and  and, in principle this integral can be done by parts….but…if we use
and, in principle this integral can be done by parts….but…if we use  we have:
we have: which is a big problem on many levels. For one,
which is a big problem on many levels. For one,  and so the new integral does not converge..and the first term doesn’t either.
and so the new integral does not converge..and the first term doesn’t either.  we note that
we note that  is the survival function whose limit does go to zero, and there is usually the assumption that
is the survival function whose limit does go to zero, and there is usually the assumption that  as
as 
 which is one of the more important formulas.
which is one of the more important formulas.  with some initial value for both
with some initial value for both  . All of the techniques use some sort of “linearization of the function” technique to:
. All of the techniques use some sort of “linearization of the function” technique to:  for all values; here you have to infer
for all values; here you have to infer 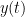 such as, say, the Taylor polynomial, and error terms which are based on things like the second derivative.
such as, say, the Taylor polynomial, and error terms which are based on things like the second derivative.  . You repeat this process a bunch of times thereby obtaining a sequence of approximations for
. You repeat this process a bunch of times thereby obtaining a sequence of approximations for 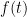 which might be close to
which might be close to  (a good approximation) or possibly far away from it (a bad approximation). And this
(a good approximation) or possibly far away from it (a bad approximation). And this  and then using THAT to refine your approximation can lead to a more stable system of
and then using THAT to refine your approximation can lead to a more stable system of 