The short: I enjoyed the book and found it hard to put down. It challenged some of my thinking and changed the way that I look at things.
What I didn’t like: the book was very inefficient; he could have conveyed the same message in about 1/3 of the pages.
But: the fluff/padding was still interesting; the author has a sense of humor and writes in an entertaining style.
What is the gist of the book? Well, the lessons are basically these:
1. Some processes lend themselves to being mathematically modeled, others don’t. Unfortunately, some people use mathematical models in situations where it is inappropriate to do so (e. g., making long term forecasts about the economy). People who rely too much on mathematical modeling are caught unprepared (or just plain surprised) when some situation arises that wasn’t considered possible in the mathematical model (e. g., think of a boxer getting in a fight with someone who grabs, kicks and bites).
2. Some processes can be effectively modeled by the normal distribution, others can’t. Example: suppose you are machining bolts and are concerned about quality, as, say, measured by the width of the bolt. That sort of process lends itself to a normal distribution; after all, if the specification is, say, 1 cm, there is no way that an errant bolt will be, say, 10 cm wide. On the other hand, if you are talking about stock markets, it is possible that some catastrophic event (called a “black swan”) can occur that causes the market to, say, lose half or even 2/3’rd of its value. If one tried to model recent market price changes by some sort of normal-like distribution, such a large variation would be deemed as being all but impossible.
3. Sometimes these extremely rare events have catastrophic outcomes. But these events are often impossible to predict beforehand, even if people do “after the fact studies” that say “see, you should have predicted this.”
4. The future catastrophic event is, more often than not, one that hasn’t happened before. The ones that happened in the past, in many cases, won’t happen again (e. g., terrorists successfully coordinating at attack that slams airplanes into buildings). But the past catastrophic events are the ones that people prepare for! Bottom line: sometimes, preparing to react better is possible where being proactive is, in fact, counter productive.
5. Sometimes humans look for and find patterns that are really just coincidence, and then use faulty logic to make an inference. Example: suppose you interview 100 successful CEO’s and find that all of them pray to Jesus each day. So, obviously, praying to Jesus is a factor in becoming a CEO, right? Well, you need to look at everyone in business who prayed to Jesus and see how many of them became CEOs; often that part of the study is not done. Very rarely do we examine what the failures did.
I admit that I had to laugh at his repeated slamming of academics (I am an academic). In one place, he imagines a meeting between someone named “Fat Tony” and an academic. Taleb poses the problem: “suppose you are told that a coin is fair. Now you flip it 99 times and it comes up heads. On the 100’th flip, what the odds of another head?” Fat Tony says something like “about 99 percent” where the academic says “50 percent”.
Frankly, that hypothetical story is pure nonsense. In this case, the academic is really saying “if I am 100 percent sure that the coin is fair, there is a Black Swan even that has 100 heads in a row” though, in reality, the academic would reject the null hypothesis that the coin is fair as the probability of a fair coin coming up heads 99 times in a row is 2^{-99} which is way in the rejection region of a statistical test.
Taleb also discusses an interesting aspect of human nature that I didn’t believe at first..until I tried it out with friends. This is a demonstration: ask your friend “which is more likely:
1. A random person drives drunk and gets into an auto accident or
2. A random person gets into an auto accident.
Or you could ask: “which is more likely: a random person:
1. Is a smoker and gets lung cancer or
2. Gets lung cancer.
Of course, the correct answer in each case is “2”: the set of all auto accidents caused by drunk driving is a subset of all auto accidents and the set of all lung cancer cases due to smoking is a subset of all lung cancer cases.
But when I did this, my friend chose “1”!!!!!!
I had to shake my head, but that is a human tendency.
One other oddity of the book toward the end, Taleb discusses fitness. He mentions that he hit on the perfect fitness program by asking himself: “what did early humans do? Ans.: walk long distances to hunt, and engage in short burst of high intensity activity”. He then decided to walk long, slow distances and do sprints every so often.
Well, nature also had humans die early of various diseases; any vaccine or cure works against “mother nature”. So I hardly view nature as always being optimal. But I did note with amusement that Taleb walks 10-15 hours a week, which translates to 30-45 miles per week! (20 minutes per mile pace).
I’d say THAT is why he is fit. 🙂
(note: since I love to hike and walk long distances, this comment was interesting to me)

![[-1, 1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![x_0, x_1, x_2, ...x_k \in [-1,1]](https://s0.wp.com/latex.php?latex=x_0%2C+x_1%2C+x_2%2C+...x_k+%5Cin+%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)










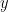





![[-1, 1] \times [-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C+1%5D+%5Ctimes+%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)



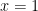






![[-\frac{1}{2^{n-1}}, \frac{1}{2^{n-1}}]](https://s0.wp.com/latex.php?latex=%5B-%5Cfrac%7B1%7D%7B2%5E%7Bn-1%7D%7D%2C+%5Cfrac%7B1%7D%7B2%5E%7Bn-1%7D%7D%5D&bg=ffffff&fg=000000&s=0&c=20201002)
![x \in [-1,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
 where
where  is some number in
is some number in ![[x_0 -h, x_0 + h]](https://s0.wp.com/latex.php?latex=%5Bx_0+-h%2C+x_0+%2B+h%5D+&bg=ffffff&fg=000000&s=0&c=20201002) ; of course we assume that the third derivative is continuous in this interval.
; of course we assume that the third derivative is continuous in this interval. and differentiate or one can use the degree 2 Taylor polynomial expanded about
and differentiate or one can use the degree 2 Taylor polynomial expanded about  and use
and use  and solve for
and solve for  ; of course one runs into some issues with the remainder term if one uses the Taylor method.
; of course one runs into some issues with the remainder term if one uses the Taylor method.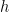 ?” In theory, we should get a better approximation if we make
?” In theory, we should get a better approximation if we make  but rather
but rather  where
where  where
where  is the round off error used in calculating the function at
is the round off error used in calculating the function at  and the magnitude of the actual error is bounded by
and the magnitude of the actual error is bounded by  where
where  on some small neighborhood of
on some small neighborhood of 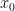 and
and  is a bound on the round-off error of representing
is a bound on the round-off error of representing  .
. .
.  and then do some experimentation to determine
and then do some experimentation to determine 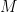 (a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for
(a bound for the 3’rd derivative) is easy to obtain, and then obtain an educated guess for  at
at  ; of course
; of course  and
and  is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of
is reasonable here (just a tiny bit off). I did the 3-point estimation calculation for various values of  and at
and at 

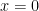 case, we see that the error starts to increase again at about
case, we see that the error starts to increase again at about  ; the same sort of thing appears to happen for
; the same sort of thing appears to happen for  ; it is roughly
; it is roughly  at
at  .
. instead; something interesting happens in the
instead; something interesting happens in the  scale by doing the following (approximating
scale by doing the following (approximating  for
for 
 . The graph looks like:
. The graph looks like:
 and run plot(N, LE):
and run plot(N, LE):
 , which is the same as EXCEL.
, which is the same as EXCEL. . On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0.
. On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0. , the probability of detection of a cancer be given by
, the probability of detection of a cancer be given by  and the probability of a false positive be given by
and the probability of a false positive be given by  ; this gives us something to optimize. The partial derivatives are:
; this gives us something to optimize. The partial derivatives are: . Note that
. Note that  is positive since
is positive since  is less than 1 (in fact, it is small). We also know that the critical point
is less than 1 (in fact, it is small). We also know that the critical point  is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if
is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if  for us, and
for us, and  . Note that
. Note that  and
and  . Hence an increase in the accuracy of the
. Hence an increase in the accuracy of the  leads to an improvement of about .00136 (substitute
leads to an improvement of about .00136 (substitute  into the expression for
into the expression for  and multiply by
and multiply by  . Similarly an improvement (decrease) of
. Similarly an improvement (decrease) of  leads to an improvement of .013609.
leads to an improvement of .013609. ) we get
) we get  . Now let’s change:
. Now let’s change:  leads to
leads to 
 we get
we get 
 . Of course, a proper definition of this concept requires at least limits or at least a rigorous definition of the log function and she was well aware that the vast majority of high school students aren’t ready for such things. Still, the instructor should be; as she said “we all wave our hands from time to time, but WE should know when we are waving our hands.”
. Of course, a proper definition of this concept requires at least limits or at least a rigorous definition of the log function and she was well aware that the vast majority of high school students aren’t ready for such things. Still, the instructor should be; as she said “we all wave our hands from time to time, but WE should know when we are waving our hands.” where
where  are points in the plane.
are points in the plane.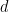 tend to zero? What is the smallest
tend to zero? What is the smallest  for which the ellipse is non-vanishing (
for which the ellipse is non-vanishing ( and two other roots in the unit circle; then one can study where the the roots of the derivative lie. For a certain class of these polynomials, there is a dead circle tangent to the unit circle at 1 which encloses no roots of the derivative.
and two other roots in the unit circle; then one can study where the the roots of the derivative lie. For a certain class of these polynomials, there is a dead circle tangent to the unit circle at 1 which encloses no roots of the derivative. 
 and some have trouble with the cost function
and some have trouble with the cost function 
 and the area function
and the area function  then one can show that the solution
then one can show that the solution  will always have the following property:
will always have the following property: 



 or that the “share” of the cost associated with the
or that the “share” of the cost associated with the 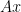 term depends on the fraction
term depends on the fraction  , which is the fraction of the total exponent of the function determining
, which is the fraction of the total exponent of the function determining  .
. .
. .
.