The video, when ready, will be posted below.


The video, when ready, will be posted below.
I talked about the root and ratio test here and how the root test is the stronger of the two tests. What I should point out that the proof of the root test depends on the basic comparison test.
And so..a professor on Twitter asked:
Of course, one proves the limit comparison test by the direct comparison test. But in a calculus course, the limit comparison test might appear to be more readily useful..example:
Show 
So..what about the direct comparison test?
As someone pointed out: the direct comparison can work very well when you don’t know much about the matrix.
One example can be found when one shows that the matrix exponential 


For those unfamiliar: 

What enables convergence is the factorial in the denominators of the individual terms; the i-j’th element of each 
But how does one prove convergence?
The usual way is to dive into matrix norms; one that works well is 
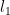
Then one can show 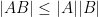

For any index 
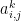
It then follows that ![| [ e^A ]_{i,j} | \leq \sum^{\infty}_{k=0} {|A^k |\over k!} \leq \sum^{\infty}_{k=0} {|A|^k \over k!} =e^{|A|}](https://s0.wp.com/latex.php?latex=%7C+%5B+e%5EA+%5D_%7Bi%2Cj%7D+%7C+%5Cleq+%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%5Ek+%7C%5Cover+k%21%7D+%5Cleq++%5Csum%5E%7B%5Cinfty%7D_%7Bk%3D0%7D+%7B%7CA%7C%5Ek+%5Cover+k%21%7D+%3De%5E%7B%7CA%7C%7D+&bg=ffffff&fg=000000&s=0&c=20201002)
Let’s look at an “easy” starting example: write
We know how that goes: multiply both sides by 




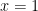

BUT…why CAN you do such a substitution since the original domain excludes 
Lets start with 
Now multiply both sides by 




Yes, no engineer will care about this. But THIS is the reason we can substitute the non-domain points.
As an aside: if you are trying to solve something like 

We are using Mathematical Statistics with Applications (7’th Ed.) by Wackerly, Mendenhall and Scheaffer for our calculus based probability and statistics course.
They present the following Theorem (5.5 in this edition)
Let 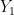









Ok, that is fine as it goes, but then they apply the above theorem to the joint density function: 
![(y_1,y_2) \in [0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%28y_1%2Cy_2%29+%5Cin+%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

It isn’t that hard to fix, I don’t think.
Now there is the density function 
![[0,1] \times [0,1]](https://s0.wp.com/latex.php?latex=%5B0%2C1%5D+%5Ctimes+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

But how does one KNOW that 
I played around a bit and came up with the following:
Statement: 
Proof of the statement: substitute 




Now substitute 

This is hardly profound but I admit that I’ve been negligent in pointing this out to classes.
We are discussing abstract vector spaces in linear algebra class. So, I decided to do an application.
Let 



Now there are many reasons why we might want to find a degree 

This is a blizzard of subscripts but the idea is pretty simple. Note that 


But let’s look at a simple example: suppose we want to form a new basis for 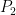

So

Now, we claim that the 
Suppose 

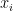




Example: suppose we want to have a degree two polynomial 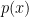



We had a fun mathematics seminar yesterday.

Andrew Shallue gave a talk about the Carmichael numbers and gave a glimpse into his research. Along the way he mentioned the work of another mathematician…one that I met during my ultramarathon/marathon walking adventures! Talk about a small world..
So, to kick start my brain cells, I’ll say a few words about these.
First of all, prime numbers are very important in encryption schemes and it is a great benefit to be able to find them. However, for very large numbers, it can be difficult to determine whether a number is prime or not.
So one can take short cuts in determining whether a number is *likely* prime or not: one can say “ok, prime numbers have property P and if this number doesn’t have property P, it is not a prime. But if it DOES have property P, we hare X percent sure that it really is a prime.
If this said property is relatively “easy” to implement (via a computer), we might be able to live with the small amount of errors that our test generates.
One such test is to see if this given number satisfies “Fermat’s Little Theorem” which is as follows:
Let 
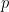


If you forgotten how this works, recall that 






So one way to check to see if a number 



Now this is NOT a perfect check; there are non-prime numbers for which
The talk was about much more than this, but this was interesting.
The mainstream media recently had some excellent articles on two mathematical giants:
John Conway and Terrance Tao. I’ve never met Terry Tao though I do read (or try to follow) his blog.
I did meet John Conway when he visited the University of Texas. He is a friend of my dissertation advisor and gave some talks on knot diagram colorings.
I had a private conversation with him at a party, and he gave me some ideas which resulted in three papers for me! Here is one of them.
Yes, I am avoiding studying a book on the theory of interest; I am teaching that course this fall and need to get ahead of the game.
Unfortunately, when I don’t teach, my use of time becomes undisciplined.
For those of you who are a bit rusty: a finite group is a group that has a finite number of elements. A simple group is one that has no proper non-trivial normal subgroups (that is, only the identity and the whole group are normal subgroups).
It is a theorem that if 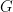
1. Cyclic (of prime order, of course)
2. Alternating (and not isomorphic to 
3. A member of a subclass of Lie Groups
4. One of 26 other groups that don’t fall into 1, 2 or 3.
Scientific American has a nice article about this theorem and the effort to get it written down and understood; the problem is that the proof of such a theorem is far from simple; it spans literally hundreds of research articles and would take thousands of pages to be complete. And, those who have an understanding of this result are aging and won’t be with us forever.
Here is a link to the preview of the article; if you don’t subscribe to SA it is probably in your library.
If you teach at an institution that has a competitive sports team, you’ll probably notice that the coaches spend time on recruiting. It is easy to see why: though athletes train hard to improve their performances, their inherent athletic ability provides an upper bound of how well they will do.
I played sports in high school, but wasn’t within an AU of being able to compete at the college level, any division. I remember summer wrestling; those recruited to wrestle for our team basically had their way with me on the mat.
In my current sports, I always do poorly in competition. For example, in my best running marathon, the winner beat me by 74 minutes! (winning time was 2:19).
It wasn’t that I didn’t try or didn’t train: it was that because I am a poor natural athlete, training only “moves the needle” just a bit, and not nearly enough for me to be competitive.
A coach could give me this workout or that workout…and get angry with me. But I have athletic limitations.
The same principle applies in mathematics.
Right now I am teaching the second semester of calculus for non-technical majors.
One question was: find the maximum and minimum of 
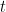

Now I asked the class some questions. And, well, let’s just say that they didn’t just recognize what the various terms and factors meant.
Now we took the derivative to find the local maximum and local minimum values and most of them got 
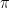
But now, when we had 

So, I reminded myself of what it must have been like for my sports coaches in high school…..what it was like for them to work with me.

For the prize: what is the significance of the two chains, and which one directly applies to the human subject of this doodle?
The human subject of the doodle is Emmy Noether.





