I was working through Nate Silver’s book The Signal and the Noise and got to his chapter about hypothesis testing. It is interesting reading and I thought I would expand on that by posing a couple of problems.
Problem one: suppose you knew that someone attempted some basketball free throws.
If they made 1 of 4 shots, what would the probability be that they were really, say, a 75 percent free throw shooter?
What if they made 2 of 8 shots instead?
Or, what if they made 5 of 20 shots?
Problem two: Suppose a woman aged 40-49 got a digital mammagram and got a “positive” reading. What is the probability that she indeed has breast cancer, given that the test catches 80 percent of the breast cancers (note: 20 percent is one estimate of the “false negative” rate; and yes, the false positive rate is 7.8 percent. The actual answer, derived from data, might surprise you: it is : 16.3 percent.
I’ll talk about problem two first, as this will limber the mind for problem one.
So, you are a woman between 40-49 years of age and go into the doctor and get a mammogram. The result: positive.
So, what is the probability that you, in fact, have cancer?
Think of it this way: out of 10,000 women in that age bracket, about 143 have breast cancer and 9857 do not.
So, the number of false positives is 9857*.078 = 768.846; we’ll keep the decimal for the sake of calculation;
The number of true positives is: 143*.8 = 114.4.
The total number of positives is therefore 883.246.
The proportion of true positives is  So the false positive rate is 83.72 percent.
So the false positive rate is 83.72 percent.
It turns out that, data has shown the 80-90 percent of positives in women in this age bracket are “false positives”, and our calculation is in line with that.
I want to point out that this example is designed to warm the reader up to Bayesian thinking; the “real life” science/medicine issues are a bit more complicated than this. That is why the recommendations for screening include criteria as to age, symptoms vs. asymptomatic, family histories, etc. All of these factors affect the calculations.
For example: using digital mammograms with this population of 10,000 women in this age bracket adds 2 more “true” detections and adds 170 more false positives. So now our calculation would be  , so while the true detections go up, the false positives also goes up!
, so while the true detections go up, the false positives also goes up!
Our calculation, while specific to this case, generalizes. The formula comes from Bayes Theorem which states:
 . Here:
. Here:  is the probability of event A occurring given that B occurs and P(A) is the probability of event A occurring. So in our case, we were answering the question: given a positive mammogram, what is the probability of actually having breast cancer? This is denoted by P(A|B) . We knew: P(B|A) which is the probability of having a positive reading given that one has breast cancer and P(B|not(A)) is the probability of getting a positive reading given that one does NOT have cancer. So for us:
is the probability of event A occurring given that B occurs and P(A) is the probability of event A occurring. So in our case, we were answering the question: given a positive mammogram, what is the probability of actually having breast cancer? This is denoted by P(A|B) . We knew: P(B|A) which is the probability of having a positive reading given that one has breast cancer and P(B|not(A)) is the probability of getting a positive reading given that one does NOT have cancer. So for us: and
and  .
.
The bottom line: If you are testing for a condition that is known to be rare, even a reasonably accurate test will deliver a LOT of false positives.
Here is a warm up (hypothetical) example. Suppose a drug test is 99 percent accurate in that it will detect that a certain drug is there 99 percent of the time (if it is really there) and only yield a false positive 1 percent of the time (gives a positive result even if the person being tested is free of this drug). Suppose the drug use in this population is “known” to be, say 5 percent.
Given a positive test, what is the probability that the person is actually a user of this drug?
Answer:  . So, in this population, about 16.1 percent of the positives will be “false positives”, even though the test is 99 percent accurate!
. So, in this population, about 16.1 percent of the positives will be “false positives”, even though the test is 99 percent accurate!
Now that you are warmed up, let’s proceed to the basketball question:
Question: suppose someone (that you don’t actually see) shoots free throws.
Case a) the player makes 1 of 4 shots.
Case b) the player makes 2 of 8 shots.
Case c) the player makes 5 of 20 shots.
Now you’d like to know: what is the probability that the player in question is really a 75 percent free throw shooter? (I picked 75 percent as the NBA average for last season is 75.3 percent).
Now suppose you knew NOTHING else about this situation; you know only that someone attempted free throws and you got the following data.
How this is traditionally handled
The traditional “hypothesis test” uses the “frequentist” model: you would say: if the hypothesis that the person really is a 75 percent free throw shooter is true, what is the probability that we’d see this data?
So one would use the formula for the binomial distribution and use n = 4 for case A, n = 8 for case B and n = 20 for case C and use p = .75 for all cases.
In case A, we’d calculate the probability that the number of “successes” (made free throws) is less than or equal to 1; 2 for case B and 5 for case C.
For you experts: the null hypothesis would be, say for the various cases would be  respectively, where the probability mass function is adjusted for the different values of n .
respectively, where the probability mass function is adjusted for the different values of n .
We could do the calculations by hand, or rely on this handy calculator.
The answers are:
Case A: .0508
Case B: .0042
Case C: .0000 ( )
)
By traditional standards: Case A: we would be on the verge of “rejecting the null hypothesis that p = .75 and we’d easily reject the null hypothesis in cases B and C. The usual standard (for life science and political science) is p = .05).
(for a refresher, go here)
So that is that, right?
Well, what if I told you more of the story?
Suppose now, that in each case, the shooter was me? I am not a good athlete and I played one season in junior high, and rarely, some pickup basketball. I am a terrible player. Most anyone would happily reject the null hypothesis without a second thought.
But now: suppose I tell you that I took these performances from NBA box scores? (the first one was taken from one of the Spurs-Heat finals games; the other two are made up for demonstration).
Now, you might not be so quick to reject the null hypothesis. You might reason: “well, he is an NBA player and were he always as bad as the cases show, he wouldn’t be an NBA player. This is probably just a bad game.” In other words, you’d be more open to the possibility that this is a false positive.
Now you don’t know this for sure; this could be an exceptionally bad free throw shooter (Ben Wallace shot 41.5 percent, Shaquille O’Neal shot 52.7 percent) but unless you knew that, you’d be at least reasonably sure that this person, being an NBA player, is probably a 70-75 shooter, at worst.
So “how” sure might you be? You might look at NBA statistics and surmise that, say (I am just making this up), 68 percent of NBA players shoot between 72-78 percent from the line. So, you might say that, prior to this guy shooting at all, the probability of the hypothesis being true is about 70 percent (say). Yes, this is a prior judgement but it is a reasonable one. Now you’d use Bayes law:
Here: A represents the “75 percent shooter” being actually true, and B is the is the probability that we actually get the data. Note the difference in outlook: in the first case (the “frequentist” method), we wondered “if the hypothesis is true, how likely is it that we’d see data like this”. In this case, called the Bayesian method, we are wondering: “if we have this data, what is the probability that the null hypothesis is true”. It is a reverse statement, of sorts.
Of course, we have  and we’ve already calculated P(B|A) for the various cases. We need to make a SECOND assumption: what does event not(A) mean? Given what I’ve said, one might say not(A) is someone who shoots, say, 40 percent (to make him among the worst possible in the NBA). Then for the various cases, we calculate
and we’ve already calculated P(B|A) for the various cases. We need to make a SECOND assumption: what does event not(A) mean? Given what I’ve said, one might say not(A) is someone who shoots, say, 40 percent (to make him among the worst possible in the NBA). Then for the various cases, we calculate  respectively.
respectively.
So, we now calculate using the Bayesian method:
Case A, the shooter made 1 of 4: .1996. The frequentist p-value was .0508
Case B, the shooter made 2 of 8: .0301. The frequentist p-value was .0042
Case C, the shooter made 5 of 20: 7.08 x 10^-5 The frequentist p-value was 3.81 x 10^-6
We see the following:
1. The Bayesian method is less likely to produce a “false positive”.
2. As n, the number of data points, grows, the Bayesian conclusion and the frequentist conclusions tend toward “the truth”; that is, if the shooter shoots enough foul shots and continues to make 25 percent of them, then the shooter really becomes a 25 percent free throw shooter.
So to sum it up:
1. The frequentist approach relies on fewer prior assumptions and is computationally simpler. But it doesn’t include extra information that might make it easier to distinguish false positives from genuine positives.
2. The Bayesian approach takes in more available information. But it is a bit more prone to the user’s preconceived notions and is harder to calculate.
How does this apply to science?
Well, suppose you wanted to do an experiment that tried to find out which human gene alleles correspond so a certain human ailment. So a brute force experiment in which every human gene is examined and is statistically tested for correlation with the given ailment with null hypothesis of “no correlation” would be a LOT of statistical tests; tens of thousands, at least. And at a p-value threshold of .05 (we are willing to risk a false positive rate of 5 percent), we will get a LOT of false positives. On the other hand, if we applied bit of science prior to the experiment and were able to assign higher prior probabilities (called “posterior probability”) to the genes “more likely” to be influential and lower posterior probability to those unlikely to have much influence, our false positive rates will go down.
Of course, none of this eliminates the need for replication, but Bayesian techniques might cut down the number of experiments we need to replicate.
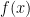

![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002)

![f(x)=\left\{\begin{array}{c} x+1,x \in [-1,0) \\ 1-x ,x\in [0,1] \\ 0 \text{ elsewhere} \end{array}\right.](https://s0.wp.com/latex.php?latex=f%28x%29%3D%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bc%7D+x%2B1%2Cx+%5Cin+%5B-1%2C0%29+%5C%5C+1-x+%2Cx%5Cin+%5B0%2C1%5D+%5C%5C+0+%5Ctext%7B+elsewhere%7D+%5Cend%7Barray%7D%5Cright.++&bg=ffffff&fg=000000&s=0&c=20201002)

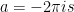





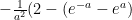


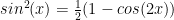





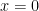

 . Needless to say, they are using a non-standard definition of “value of a series”.
. Needless to say, they are using a non-standard definition of “value of a series”. where
where  . That is a bit less offensive than calling it a “sum”. 🙂
. That is a bit less offensive than calling it a “sum”. 🙂
 . On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0.
. On the other hand, if you just declared EVERYONE to be “cancer free”, you’d be wrong only 1.4 percent of the time! So clearly that does not work; the “false negative” rate is 100 percent, though the “false positive” rate is 0. and the probability of a false positive be given by
and the probability of a false positive be given by 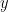 . Then the probability of a person actually having breast cancer, given a positive test is given by:
. Then the probability of a person actually having breast cancer, given a positive test is given by: ; this gives us something to optimize. The partial derivatives are:
; this gives us something to optimize. The partial derivatives are: . Note that
. Note that  is positive since
is positive since  is less than 1 (in fact, it is small). We also know that the critical point
is less than 1 (in fact, it is small). We also know that the critical point  is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if
is a bit of a “duh”: find a single test that gives no false positives and no false negatives. This also shows us that our predictions will be better if  for us, and
for us, and  . Note that
. Note that  and
and  . Hence an increase in the accuracy of the
. Hence an increase in the accuracy of the  leads to an improvement of about .00136 (substitute
leads to an improvement of about .00136 (substitute  into the expression for
into the expression for  and multiply by
and multiply by  . Similarly an improvement (decrease) of
. Similarly an improvement (decrease) of  leads to an improvement of .013609.
leads to an improvement of .013609. ) we get
) we get  . Now let’s change:
. Now let’s change:  leads to
leads to 
 we get
we get 

 and we say
and we say  where the overline decoration denotes complex conjugation.
where the overline decoration denotes complex conjugation.  is finite.
is finite. is Hermitian. To do that we’d have to show that:
is Hermitian. To do that we’d have to show that: . This doesn’t seem too hard to do at first, if we use integration by parts:
. This doesn’t seem too hard to do at first, if we use integration by parts:![\int^{\infty}_{-\infty} \overline{\frac{d^2}{dx^2}\phi} \psi dx = [\overline{\frac{d}{dx}\phi} \psi]^{\infty}_{-\infty} - \int^{\infty}_{-\infty}\overline{\frac{d}{dx}\phi} \frac{d}{dx}\psi dx](https://s0.wp.com/latex.php?latex=%5Cint%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D+%5Coverline%7B%5Cfrac%7Bd%5E2%7D%7Bdx%5E2%7D%5Cphi%7D+%5Cpsi+dx+%3D+%5B%5Coverline%7B%5Cfrac%7Bd%7D%7Bdx%7D%5Cphi%7D+%5Cpsi%5D%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D+-+%5Cint%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D%5Coverline%7B%5Cfrac%7Bd%7D%7Bdx%7D%5Cphi%7D+%5Cfrac%7Bd%7D%7Bdx%7D%5Cpsi+dx+&bg=ffffff&fg=000000&s=0&c=20201002) . Now because the functions are square integrable, the
. Now because the functions are square integrable, the ![[\overline{\frac{d}{dx}\phi} \psi]^{\infty}_{-\infty}](https://s0.wp.com/latex.php?latex=%5B%5Coverline%7B%5Cfrac%7Bd%7D%7Bdx%7D%5Cphi%7D+%5Cpsi%5D%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D+&bg=ffffff&fg=000000&s=0&c=20201002) term is zero (the functions must go to zero as
term is zero (the functions must go to zero as  . Now we use integration by parts again:
. Now we use integration by parts again:![- \int^{\infty}_{-\infty}\overline{\frac{d}{dx}\phi} \frac{d}{dx}\psi dx = -[\overline{\phi} \frac{d}{dx}\psi]^{\infty}_{-\infty} + \int^{\infty}_{-\infty} \overline{\phi}\frac{d^2}{dx^2} \psi dx](https://s0.wp.com/latex.php?latex=-+%5Cint%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D%5Coverline%7B%5Cfrac%7Bd%7D%7Bdx%7D%5Cphi%7D+%5Cfrac%7Bd%7D%7Bdx%7D%5Cpsi+dx+%3D+-%5B%5Coverline%7B%5Cphi%7D+%5Cfrac%7Bd%7D%7Bdx%7D%5Cpsi%5D%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D+%2B+%5Cint%5E%7B%5Cinfty%7D_%7B-%5Cinfty%7D+%5Coverline%7B%5Cphi%7D%5Cfrac%7Bd%5E2%7D%7Bdx%5E2%7D+%5Cpsi+dx&bg=ffffff&fg=000000&s=0&c=20201002) which is what we wanted to show.
which is what we wanted to show.  to be square integrable but to be unbounded!
to be square integrable but to be unbounded!  and base of width
and base of width  . Let
. Let  be a function whose graph is a constant function of height
be a function whose graph is a constant function of height ![x \in [k - \frac{1}{2^{3k+1}}, k + \frac{1}{2^{3k+1}}]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5Bk+-+%5Cfrac%7B1%7D%7B2%5E%7B3k%2B1%7D%7D%2C+k+%2B+%5Cfrac%7B1%7D%7B2%5E%7B3k%2B1%7D%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002) for all positive integers
for all positive integers  and zero elsewhere. Then
and zero elsewhere. Then  has height
has height  over all of those intervals which means that the area enclosed by each rectangle (tall, but thin rectangles) is
over all of those intervals which means that the area enclosed by each rectangle (tall, but thin rectangles) is  . Hence
. Hence  .
.  and add that to the “square integrable” assumption.
and add that to the “square integrable” assumption.  where
where  converges.
converges. 
 . Of course, there is an easy vector space isomorphism (Hilbert space isomorphism really) between the vector space of state vectors and kets given by
. Of course, there is an easy vector space isomorphism (Hilbert space isomorphism really) between the vector space of state vectors and kets given by  . The kets are denoted by
. The kets are denoted by  .
. and the vector space isomorphism is given by
and the vector space isomorphism is given by  . I chose this isomorphism because in the bra vector space,
. I chose this isomorphism because in the bra vector space,  . Then there is a vector space isomorphism between the bras and the kets given by
. Then there is a vector space isomorphism between the bras and the kets given by  .
. is the inner product; that is
is the inner product; that is 
 is a linear operator,
is a linear operator,  and
and  Now if
Now if  .
. and eigenvalues
and eigenvalues  . Let
. Let  and if
and if  is a random variable corresponding to the observed value of
is a random variable corresponding to the observed value of  and the expectation
and the expectation  .
.
{kind=link}