During the linear regression section of our statistics course, we do examples with spreadsheets. Many spreadsheets have data processing packages that will do linear regression and provide output which includes things such as confidence intervals for the regression coefficients, the 
The purpose of this note is NOT to provide an introduction to the type of ANOVA that is used in linear regression (one can find a brief introduction here or, of course, in most statistics textbooks) but to show a simple example using the “random number generation” features in the Excel (with the data analysis pack loaded into it).
I’ll provide some screen shots to show what I did.
If you are familiar with Excel (or spread sheets in general), this note will be too slow-paced for you.
Brief Background (informal)
I’ll start the “ANOVA for regression” example with a brief discussion of what we are looking for: suppose we have some data which can be thought of as a set of 

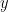

It turns out that the “sum of squares” 


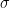

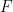


For example: if the regression line fit the data perfectly, the SSE terms would be zero and the SSR term would equal the SS term as the predicted y values would be the y values. Hence the ratio of (SSR/constant) over (SSE/constant) would be infinite.
That is, the ratio that we use roughly measures the percentage of variation of the y values that comes from the regression line verses the percentage that comes from the error from the regression line. Note that it is customary to denote SSE/(n-2) by MSE and SSR/1 by MSR. (Mean Square Error, Mean Square Regression).
The smaller the numerator relative to the denominator the less that the regression explains.
The following examples using Excel spread sheets are designed to demonstrate these concepts.
The examples are as follows:
Example one: a perfect regression line with “perfect” normally distributed residuals (remember that the usual hypothesis test on the regression coefficients depend on the residuals being normally distributed).
Example two: a regression line in which the y-values have a uniform distribution (and are not really related to the x-values at all).
Examples three and four: show what happens when the regression line is “perfect” and the residuals are normally distributed, but have greater standard deviations than they do in Example One.
First, I created some x values and then came up with the line 

This is the result after copying:

Now we need to add some residuals to give us a non-zero SSE. This is where the “random number generation” feature comes in handy. One goes to the data tag and then to “data analysis”

and clicks on “random number generation”:

This gives you a dialogue box. I selected “normal distribution”; then I selected “0” of the mean and “1” for the standard deviation. Note: the assumption underlying the confidence interval calculation for the regression parameter confidence intervals is that the residuals are normally distributed and have an expected value of zero.

I selected a column for output (as many rows as x-values) which yields a column:

Now we add the random numbers to the column “fake” to get a simulated set of y values:

That yields the column Y as shown in this next screenshot. Also, I used the random number generator to generate random numbers in another column; this time I used the uniform distribution on [0,54]; I wanted the “random set of potential y values” to have roughly the same range as the “fake data” y-values.

Y holds the “non-random” fake data and YR holds the data for the “Y’s really are randomly distributed” example.

I then decided to generate two more “linear” sets of data; in these cases I used the random number generator to generate normal residuals of larger standard deviation and then create Y data to use as a data set; the columns or residuals are labeled “mres” and “lres” and the columns of new data are labeled YN and YVN.
Note: in the “linear trend data” I added the random numbers to the exact linear model y’s labeled “fake” to get the y’s to represent data; in the “random-no-linear-trend” data column I used the random number generator to generate the y values themselves.
Now it is time to run the regression package itself. In Excel, simple linear regression is easy. Just go to the data analysis tab and click, then click “regression”:

This gives a dialogue box. Be sure to tell the routine that you have “headers” to your columns of numbers (non-numeric descriptions of the columns) and note that you can select confidence intervals for your regression parameters. There are other things you can do as well.

You can select where the output goes. I selected a new data sheet.

Note the output: the 


This is what a plot of the calculated regression line with the “fake data” looks like:

Yes, this is unrealistic, but this is designed to demonstrate a concept. Now let’s look at the regression output for the “uniform y values” (y values generated at random from a uniform distribution of roughly the same range as the “regression” y-values):

Note: 

A plot looks like:

The next two examples show what happens when one “cooks” up a regression line with residuals that are normally distributed, have mean equal to zero, but have larger standard deviations. Watch how the




