Of course computers store numbers in binary; that is numbers are represented by  where each
where each  (of course the first coefficient is 1).
(of course the first coefficient is 1).
We should probably “warm up” by showing some binary expansions. First: someone might ask “how do I know that a number even HAS a binary expansion? The reason: the dyatic rationals are dense in the number line. So just consider a set of nested partitions of the number line, where each partition in the family has width  and it isn’t hard to see a sequence that converges to a given number. That sequence leads to the binary expansion.
and it isn’t hard to see a sequence that converges to a given number. That sequence leads to the binary expansion.
Example: What is the binary expansion for 10.25?
Answer: Break 10.25 down into 10 + 0.25.
 so the “integer part” of the binary expansion is
so the “integer part” of the binary expansion is  .
.
Now for the “faction part”:  in binary.
in binary.
Hence  in base 10
in base 10  in binary.
in binary.
So what about something harder? Integers are easy, so lets look at  where each
where each  .
.
Clearly  since
since  is greater than
is greater than  . Now
. Now  so multiply both sides of by 4 to obtain
so multiply both sides of by 4 to obtain 
Now subtract 1 from both sides and get  Here
Here  so multiply both sides by 2 and subtract 1 and get
so multiply both sides by 2 and subtract 1 and get 
Note that we are back where we started. The implication is that  and so the base 2 decimal expansion for is
and so the base 2 decimal expansion for is 
Of course there is nothing special about ; a moment’s thought reveals that if one starts with  where
where 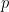 is less than
is less than  , the process stops (we arrive at zero on the left hand side) or we return to some other
, the process stops (we arrive at zero on the left hand side) or we return to some other  where
where 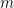 is less than ; since there are only a finite number of we have to arrive at a previous fraction eventually (pigeonhole principle). So every rational number has a terminating or repeating binary decimal expansion.
is less than ; since there are only a finite number of we have to arrive at a previous fraction eventually (pigeonhole principle). So every rational number has a terminating or repeating binary decimal expansion.
Now it might be fun to check that we did the expansion correctly; the geometric series formula will help:

Now about how the computer stores a number: a typical storage scheme is what I call the 1-11-52 scheme. There are 64 bits used for the number. The first is for positive or negative. The next 11 bits are for the exponent. Now  so technically the exponent could be as large as
so technically the exponent could be as large as  . But we want to be able to store small numbers as well, so
. But we want to be able to store small numbers as well, so  is subtracted from this number so we could get exponents that range from
is subtracted from this number so we could get exponents that range from  to
to  . Also remember these are exponents for base 2.
. Also remember these are exponents for base 2.
This leaves 52 digits for the mantissa; that is all the computer can store. This is the place where one can look at round off error.
Let’s see two examples:
10.25 is equal to  . The first bit is a 0 because the number is positive. The exponent is 3 and so is represented by
. The first bit is a 0 because the number is positive. The exponent is 3 and so is represented by  which is
which is  . Now the mantissa is assumed to start with 1 every time; hence we get 0100100000000000000000000000000000000000000000000000.
. Now the mantissa is assumed to start with 1 every time; hence we get 0100100000000000000000000000000000000000000000000000.
So, let’s look at the example. The first digit is 0 since the number is positive. We write the binary expansion as:  . The exponent is
. The exponent is  which is stored as
which is stored as  . Now the fun starts: we need an infinite number of bits for an exact representation but we have 52.
. Now the fun starts: we need an infinite number of bits for an exact representation but we have 52.  is what is repeated so we can repeat this 51 times plus the next 0. So the number that serves as a proxy for is really
is what is repeated so we can repeat this 51 times plus the next 0. So the number that serves as a proxy for is really 
Ok, about spreadsheets:
Of course, it is difficult to use base 2 directly to demonstrate round off error, so many texts use regular decimals and instruct the students to perform calculations using “n-digit rounding” and “n-digit chopping” to show how errors can build up with iterated operations.
One common example: use the quadratic formula to find the roots of a quadratic equation. Of course the standard formula for the roots of  is
is  and there is an alternate formula
and there is an alternate formula  that leads to less round off error in the case when the “alternative formula” denominator has large magnitude.
that leads to less round off error in the case when the “alternative formula” denominator has large magnitude.
Now the computations, when done by hand, can be tedious and more of an exercise in repeated calculator button punching than anything else.
But a spreadsheet can help, provided one can find a way to use the “ROUND(N, M)” command and the “TRUNC(N, M)” commands to good use. In each case, N is the number to be rounded or truncated and M is the decimal place.
A brief review of these commands: the ROUND command takes a decimal and rounds to the nearest  place; the TRUNC truncates the decimal to the nearest place.
place; the TRUNC truncates the decimal to the nearest place.
The key: M can be any integer; positive, negative or zero .
Examples: TRUNC(1234.5678, 2) = 1234.56, TRUNC(1234.5678, -1) = 1230, ROUND(1234.5678, 3) = 1234.569, ROUND(1234.5678, -2) = 1200.
Formally: if one lets  for all
for all  and if
and if  then TRUNC(x, M) =
then TRUNC(x, M) = 
So if M is negative, this process stops at a positive power of 10.
That observation is the key to getting the spread sheet to round or truncate to a desired number of significant digits.
Recall that the base 10 log picks of the highest power of 10 that appears in a number; for example  So let’s exploit that: we can modify our commands as follows:
So let’s exploit that: we can modify our commands as follows:
for TRUNC we can use TRUNC(N, M -1 – INT(log10(abs(N)))) and for ROUND we can use ROUND(N, M -1 – INT(log10(abs(N)))). Subtracting the 1 and the integer part of the base 10 log moves the “start point” of the truncation or the rounding to the left of the decimal and M moves the truncation point back to the right to the proper place.
Of course, this can be cumbersome to type over and over again, so I recommend putting the properly typed formula in some “out of the way” cell and using “cut and paste” to paste the formula in the proper location for the formula.
Here is an example:
This spread sheet shows the “4 digit rounding” calculation for the roots of the quadratics  and
and  respectively.
respectively.

(click for a larger view).
Note that one has to make a cell for EVERY calculation because we have to use 4 digit arithmetic at EACH step. Note also the formula pasted as test in the upper right hand cell.
One can cut an paste as a cell formula as shown below:

Here one uses cell references as input values.
Here is another example:

Note the reference to the previous cells.
 be defined as follows:
be defined as follows:
 if
if  is irrational or zero, and
is irrational or zero, and 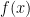 is
is  if
if  where
where  .
. 
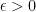 be given and choose a positive integer
be given and choose a positive integer 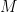 so that
so that  . Let
. Let  . Now if
. Now if  and
and  .
. and
and  .
. 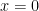 and is equal to zero. But zero is the only place where this function is even continuous because for any open interval
and is equal to zero. But zero is the only place where this function is even continuous because for any open interval  ,
,  .
.

 ALWAYS fails to exist if both limits exist and
ALWAYS fails to exist if both limits exist and  and
and  .)
.) where
where  . We use the form
. We use the form  (I am too lazy to use the traditional “p-hat” notation). First, note that the denominator works out to
(I am too lazy to use the traditional “p-hat” notation). First, note that the denominator works out to 
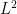 terms cancel and as far as the rest:
terms cancel and as far as the rest:
 and one that doesn’t. Here is the term involving
and one that doesn’t. Here is the term involving 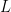 :
: 




 goes to infinity, the error goes to zero very quickly. It might be instructive to look at the ratio of the errors for
goes to infinity, the error goes to zero very quickly. It might be instructive to look at the ratio of the errors for  and
and  :
:

 . In the limit, the first term decreases to
. In the limit, the first term decreases to  and the second goes to infinity.
and the second goes to infinity.  .
. . If we have
. If we have  (
( is positive, of course) we say that the convergence is LINEAR if
is positive, of course) we say that the convergence is LINEAR if  and
and  the inequality must be strict. If
the inequality must be strict. If  then we say that convergence is quadratic (regardless of
then we say that convergence is quadratic (regardless of  so one can think: “get new approximation by multiplying the old approximation by some constant less than one”. For example:
so one can think: “get new approximation by multiplying the old approximation by some constant less than one”. For example:  exhibits linear convergence to 0; that is a decent way to think about it.
exhibits linear convergence to 0; that is a decent way to think about it.  where
where  are constants strictly between 0 and 1. Of course, as
are constants strictly between 0 and 1. Of course, as  . To see how this formula is obtained,
. To see how this formula is obtained,  and if, say,
and if, say,  is much larger than
is much larger than  , then
, then  will be closer to
will be closer to  than
than  is to
is to  , hence more of this error will be subtracted away.
, hence more of this error will be subtracted away.  and showed how the Aitken process works there. Note: the spreadsheet round off errors start occurring at the
and showed how the Aitken process works there. Note: the spreadsheet round off errors start occurring at the  range; you can see that here.
range; you can see that here. 
 where
where  ,
, 


