The purpose of this note is to give a bit of direction to the perplexed student.
I am not going to go into all the possible uses of eigenvalues, eigenvectors, eigenfuntions and the like; I will say that these are essential concepts in areas such as partial differential equations, advanced geometry and quantum mechanics:
Quantum mechanics, in particular, is a specific yet very versatile implementation of this scheme. (And quantum field theory is just a particular example of quantum mechanics, not an entirely new way of thinking.) The states are “wave functions,” and the collection of every possible wave function for some given system is “Hilbert space.” The nice thing about Hilbert space is that it’s a very restrictive set of possibilities (because it’s a vector space, for you experts); once you tell me how big it is (how many dimensions), you’ve specified your Hilbert space completely. This is in stark contrast with classical mechanics, where the space of states can get extraordinarily complicated. And then there is a little machine — “the Hamiltonian” — that tells you how to evolve from one state to another as time passes. Again, there aren’t really that many kinds of Hamiltonians you can have; once you write down a certain list of numbers (the energy eigenvalues, for you pesky experts) you are completely done.
(emphasis mine).
So it is worth understanding the eigenvector/eigenfunction and eigenvalue concept.
First note: “eigen” is German for “self”; one should keep that in mind. That is part of the concept as we will see.
The next note: “eigenfunctions” really are a type of “eigenvector” so if you understand the latter concept at an abstract level, you’ll understand the former one.
The third note: if you are reading this, you are probably already familiar with some famous eigenfunctions! We’ll talk about some examples prior to giving the formal definition. This remark might sound cryptic at first (but hang in there), but remember when you learned 



The basic concept of eigenvectors (eigenfunctions) and eigenvalues is really no more complicated than that. Let’s do another one from calculus:
the function 



Answer: 
So hopefully you are seeing the basic idea: we have a collection of objects called vectors (can be traditional vectors or abstract ones such as differentiable functions) and an operator (linear transformation) that acts on these objects to yield a new object. In our example, the vectors were differentiable functions, and the operators were the derivative operators (the thing that “takes the derivative of” the function). An eigenvector (eigenfunction)-eigenvalue pair for that operator is a vector (function) that is transformed to a scalar multiple of itself by the operator; e. g., the derivative operator takes 
Formal Definition
We will give the abstract, formal definition. Then we will follow it with some examples and hints on how to calculate.
First we need the setting. We start with a set of objects called “vectors” and “scalars”; the usual rules of arithmetic (addition, multiplication, subtraction, division, distributive property) hold for the scalars and there is a type of addition for the vectors and scalars and the vectors “work together” in the intuitive way. Example: in the set of, say, differentiable functions, the scalars will be real numbers and we have rules such as 
![[a, b, c]](https://s0.wp.com/latex.php?latex=%5Ba%2C+b%2C+c%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now, we need a linear transformation, which is sometimes called a linear operator. A linear transformation (or operator) is a function 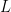


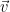
Common linear transformations (and there are many others!) and their eigenvectors and eigenvalues.
Consider the vector space of two-dimensional vectors with real numbers as scalars. We can create a linear transformation by matrix multiplication:
![L([x,y]^T) = \left[ \begin{array}{cc} a & b \\ c & d \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} ax+ by \\ cx+dy \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+a+%26+b+%5C%5C+c+%26+d+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+ax%2B+by+%5C%5C+cx%2Bdy+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002)
![[x,y]^T](https://s0.wp.com/latex.php?latex=%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002)
It is easy to check that the operation of matrix multiplying a vector on the left by an appropriate matrix is yields a linear transformation.
Here is a concrete example:
![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]=\left[ \begin{array}{c} x+ 2y \\ 3y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x%2B+2y+%5C%5C+3y+%5Cend%7Barray%7D+%5Cright%5D++&bg=ffffff&fg=000000&s=0&c=20201002)
So, does this linear transformation HAVE non-zero eigenvectors and eigenvalues? (not every one does).
Let’s see if we can find the eigenvectors and eigenvalues, provided they exist at all.
For ![L([x,y]^T) = \lambda [x,y]^T](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Clambda+%5Bx%2Cy%5D%5ET+&bg=ffffff&fg=000000&s=0&c=20201002)
So, using the matrix we get: ![L([x,y]^T) = \left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right]= \lambda \left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=L%28%5Bx%2Cy%5D%5ET%29+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D%3D+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
At this point it is tempting to try to use a distributive law to factor out ![\left[ \begin{array}{c} x \\ y \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Notice that by doing this, we haven’t changed anything except now we can factor out that vector; this would leave:
![(\left[ \begin{array}{cc} 1 & 2 \\ 0 & 3 \end{array} \right] - \lambda\left[ \begin{array}{cc} 1 & 0 \\ 0 & 1 \end{array} \right] )\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+2+%5C%5C+0+%26+3+%5Cend%7Barray%7D+%5Cright%5D++-+%5Clambda%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1+%26+0+%5C%5C+0+%26+1+%5Cend%7Barray%7D+%5Cright%5D+%29%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Which leads to:
![(\left[ \begin{array}{cc} 1-\lambda & 2 \\ 0 & 3-\lambda \end{array} \right] ) \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+1-%5Clambda+%26+2+%5C%5C+0+%26+3-%5Clambda+%5Cend%7Barray%7D+%5Cright%5D+%29+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
Now we use a fact from linear algebra: if 


Now to find the associated eigenvectors: if we start with 
![(\left[ \begin{array}{cc} 0 & 2 \\ 0 & 2 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+0+%26+2+%5C%5C+0+%26+2+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
If we next try 
![(\left[ \begin{array}{cc} -2 & 2 \\ 0 & 0 \end{array} \right] \left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 0 \\ 0 \end{array} \right]](https://s0.wp.com/latex.php?latex=%28%5Cleft%5B+%5Cbegin%7Barray%7D%7Bcc%7D+-2+%26+2+%5C%5C+0+%26+0+%5Cend%7Barray%7D+%5Cright%5D++%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+0+%5C%5C+0+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
![\left[ \begin{array}{c} x \\ y \end{array} \right] = \left[ \begin{array}{c} 1 \\ 1 \end{array} \right]](https://s0.wp.com/latex.php?latex=%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+x+%5C%5C+y+%5Cend%7Barray%7D+%5Cright%5D+%3D+%5Cleft%5B+%5Cbegin%7Barray%7D%7Bc%7D+1+%5C%5C+1+%5Cend%7Barray%7D+%5Cright%5D+&bg=ffffff&fg=000000&s=0&c=20201002)
In the general “k-dimensional vector space” case, the recipe for finding the eigenvectors and eigenvalues is the same.
1. Find the matrix 
2. Form the matrix 
3. Note that 

4. Start with 



Practical note
Yes, this should work “in theory” but practically speaking, there are many challenges. For one: for equations of degree 5 or higher, it is known that there is no formula that will find the roots for every equation of that degree (Galios proved this; this is a good reason to take an abstract algebra course!). Hence one must use a numerical method of some sort. Also, calculation of the determinant involves many round-off error-inducing calculations; hence sometimes one must use sophisticated numerical techniques to get the eigenvalues (a good reason to take a numerical analysis course!)
Consider a calculus/differential equation related case of eigenvectors (eigenfunctions) and eigenvalues.
Our vectors will be, say, infinitely differentiable functions and our scalars will be real numbers. We will define the operator (linear transformation) 

We can also use these operators to form new operators; that is 
So, what does it mean to find eigenvectors and eigenvalues of such beasts?
Suppose we with to find the eigenvectors and eigenvalues of 









Of course, reading this little note won’t make you an expert, but it should get you started on studying.
I’ll close with a link on how these eigenfunctions and eigenvalues are calculated (in the context of solving a partial differential equation).
 . What about the number of outcomes of the three dice of the same color? There are three possibilities:
. What about the number of outcomes of the three dice of the same color? There are three possibilities:
 , with the probability of a given throw being a triple of any sort being
, with the probability of a given throw being a triple of any sort being  .
. So the probability of getting a given pair of numbers (with the third being any number other than the “doubled” number) would be
So the probability of getting a given pair of numbers (with the third being any number other than the “doubled” number) would be  hence the probability of getting an arbitrary pair would be
hence the probability of getting an arbitrary pair would be  .
. . So there are
. So there are  different ways that this can happen so the probability of obtaining all different numbers is
different ways that this can happen so the probability of obtaining all different numbers is  .
. .
. and getting either triple 1’s or triple 6’s would be
and getting either triple 1’s or triple 6’s would be  and using
and using  , we obtain
, we obtain  which implies that
which implies that  throws per two seasons, or 34992 throws per season. There were 8 teams in the league and each played 84 games which means 336 games in a season. This means about 104 throws of the dice per game, or about 11.6 throws per inning or 5.8 throws per half of an inning; perhaps that is about 1 per batter.
throws per two seasons, or 34992 throws per season. There were 8 teams in the league and each played 84 games which means 336 games in a season. This means about 104 throws of the dice per game, or about 11.6 throws per inning or 5.8 throws per half of an inning; perhaps that is about 1 per batter. be continuous but non-analytic in some disk
be continuous but non-analytic in some disk  in the complex plane, and let
in the complex plane, and let  be analytic in
be analytic in  which, for the purposes of this informal note, we will take to contain an open disk. If
which, for the purposes of this informal note, we will take to contain an open disk. If  being analytic is easy and uninteresting.
being analytic is easy and uninteresting. and
and  where
where  are real valued functions of two variables which have continuous partial derivatives. Assume that
are real valued functions of two variables which have continuous partial derivatives. Assume that  and
and  (the standard Cauchy-Riemann equations) in the domain of interest and that either
(the standard Cauchy-Riemann equations) in the domain of interest and that either  or
or  in our domain of interest.
in our domain of interest.


 we can substitute:
we can substitute:




 which is zero when BOTH
which is zero when BOTH  and
and  are zero, which means that the Cauchy-Riemann equations for
are zero, which means that the Cauchy-Riemann equations for  which implies (by C-R for
which implies (by C-R for  which implies that
which implies that  and asked the students to explain why such a function was continuous everywhere but not analytic anywhere.
and asked the students to explain why such a function was continuous everywhere but not analytic anywhere.  and NON CONSTANT, is
and NON CONSTANT, is  ever analytic? Before you laugh, remember that in calculus class,
ever analytic? Before you laugh, remember that in calculus class,  is differentiable wherever
is differentiable wherever  .
. and then compose
and then compose  and substitute into the series. Now if this composition is analytic, pull out the Cauchy-Riemann equations for the composed function
and substitute into the series. Now if this composition is analytic, pull out the Cauchy-Riemann equations for the composed function  and it is now very easy to see that
and it is now very easy to see that  on some open disk which then implies by the Cauchy-Riemann equations that
on some open disk which then implies by the Cauchy-Riemann equations that  as well which means that the function is constant.
as well which means that the function is constant.  and we use
and we use  to denote the partials of these functions with respect to the first and second variables respectively. Now
to denote the partials of these functions with respect to the first and second variables respectively. Now  . Now turn to the Cauchy-Riemann equations and calculate:
. Now turn to the Cauchy-Riemann equations and calculate:



 we obtain after a little bit of algebra:
we obtain after a little bit of algebra:
 which implies either that
which implies either that  is zero which leads to the rest of the partials being zero (by C-R), or this means that
is zero which leads to the rest of the partials being zero (by C-R), or this means that  which is absurd.
which is absurd.