In an effort to make the subject a bit more accessible to undergraduate mathematics students who haven’t had much physics training, we’ve made some simplifications. We’ve dealt with the “one dimensional, non-relativistic situation” which is fine. But we’ve also limited ourselves to the case where:
1. state vectors are actual functions (like those we learn about in calculus)
2. eigenvalues are discretely distributed (e. g., the set of eigenvalues have no limit points in the usual topology of the real line)
3. each eigenvalue corresponds to a unique eigenvector.
In this post we will see what trouble simplifications 1 and 2 cause and why they cannot be lived with. Hey, quantum mechanics is hard!
Finding Eigenvectors for the Position Operator
Let 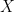 denote the “position” operator and let us seek out the eigenvectors for this operator.
denote the “position” operator and let us seek out the eigenvectors for this operator.
So  where
where 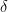 is the eigenvector and
is the eigenvector and 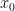 is the associated eigenvalue.
is the associated eigenvalue.
This means  which implies
which implies  .
.
This means that for  and can be anything for
and can be anything for  . This would appear to allow the eigenvector to be the “everywhere zero except for ” function. So let be such a function. But then if
. This would appear to allow the eigenvector to be the “everywhere zero except for ” function. So let be such a function. But then if  is any state vector,
is any state vector,  and
and  . Clearly this is unacceptable; we need (at least up to a constant multiple) for
. Clearly this is unacceptable; we need (at least up to a constant multiple) for 
The problem is that restricting our eigenvectors to the class of functions is just too restrictive to give us results; we have to broaden the class of eigenvectors. One way to do that is to allow for distributions to be eigenvectors; the distribution we need here is the dirac delta. In the reference I linked to, one can see how the dirac delta can be thought of as a sort of limit of valid probability density functions. Note:  .
.
So if we let  denote the dirac that is zero except for , we recall that
denote the dirac that is zero except for , we recall that  . This means that the probability density function associated with the position operator is
. This means that the probability density function associated with the position operator is 
This has an interesting consequence: if we measure the particle’s position at then the state vector becomes . So the new density function based on an immediate measurement of position would be  and
and  elsewhere. The particle behaves like a particle with a definite “point” position.
elsewhere. The particle behaves like a particle with a definite “point” position.
Momentum: a different sort of problem
At first the momentum operator  seems less problematic. Finding the eigenvectors and eigenfunctions is a breeze: if
seems less problematic. Finding the eigenvectors and eigenfunctions is a breeze: if  is the eigenvector with eigenvalue
is the eigenvector with eigenvalue  then:
then:
 has solution
has solution  .
.
Do you see the problem?
There are a couple of them: first, this provides no restriction on the eigenvalues; in fact the eigenvalues can be any real number. This violates simplification number 2. Secondly,  therefore
therefore  . Our function is far from square integrable and therefore not a valid “state vector” in its present form. This is where the famous “normalization” comes into play.
. Our function is far from square integrable and therefore not a valid “state vector” in its present form. This is where the famous “normalization” comes into play.
Mathematically, one way to do this is to restrict the domain (say, limit the non-zero part to  ) and multiply by an appropriate constant.
) and multiply by an appropriate constant.
Getting back to our state vector:  . So if we measure momentum, we have basically given a particle a wave characteristic with wavelength
. So if we measure momentum, we have basically given a particle a wave characteristic with wavelength  .
.
Now what about the duality? Suppose we start by measuring a particle’s position thereby putting the state vector in to  . Now what would be the expectation of momentum? We know that the formula is
. Now what would be the expectation of momentum? We know that the formula is  . But this quantity is undefined because
. But this quantity is undefined because  is undefined.
is undefined.
If we start in a momentum eigenvector and then wish to calculate the position density function (the expectation will be undefined), we see that which can be interpreted to mean that any position measurement is equally likely.
Clearly, momentum and position are not compatible operators. So let’s calculate 
 and
and  hence
hence  . Therefore
. Therefore  . Therefore our generalized uncertainty relation tells us
. Therefore our generalized uncertainty relation tells us 
(yes, one might object that  really shouldn’t be defined….) but this uncertainty relation does hold up. So if one uncertainty is zero, then the other must be infinite; exact position means no defined momentum and vice versa.
really shouldn’t be defined….) but this uncertainty relation does hold up. So if one uncertainty is zero, then the other must be infinite; exact position means no defined momentum and vice versa.
So: exact, pointlike position means no defined momentum is possible (hence no wave like behavior) but an exact momentum (pure wave) means no exact pointlike position is possible. Also, remember that measurement of position endows a point like state vector of which destroys the wave like property; measurement of momentum endows a wave like state vector and therefore destroys any point like behavior (any location is equally likely to be observed).




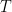
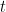

























 for
for  and
and  elsewhere.
elsewhere.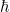 so I am going with
so I am going with 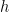 for now.
for now.  being one of the stationary states:
being one of the stationary states:

 are the eigenvalues for
are the eigenvalues for 

 where the first factor is a function of
where the first factor is a function of 
 and divide both sides by
and divide both sides by 

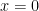 we have
we have  . Our particle is in our well and we can’t have values below 0; hence
. Our particle is in our well and we can’t have values below 0; hence  . Now
. Now 
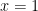 so
so  which means
which means  .
.

 . So our equation involving
. So our equation involving  so our differential equation becomes
so our differential equation becomes which has the solution
which has the solution 
 where
where  which, written in rectangular complex coordinates is
which, written in rectangular complex coordinates is 
 and plot for
and plot for  and
and  . The plot is of the real part of the stationary state vector.
. The plot is of the real part of the stationary state vector.

 where
where  converges.
converges. 
 . Of course, there is an easy vector space isomorphism (Hilbert space isomorphism really) between the vector space of state vectors and kets given by
. Of course, there is an easy vector space isomorphism (Hilbert space isomorphism really) between the vector space of state vectors and kets given by  . The kets are denoted by
. The kets are denoted by  .
. and the vector space isomorphism is given by
and the vector space isomorphism is given by  . I chose this isomorphism because in the bra vector space,
. I chose this isomorphism because in the bra vector space,  . Then there is a vector space isomorphism between the bras and the kets given by
. Then there is a vector space isomorphism between the bras and the kets given by  .
. is the inner product; that is
is the inner product; that is 
 is a linear operator,
is a linear operator,  and
and  Now if
Now if  .
. and eigenvalues
and eigenvalues  . Let
. Let  and if
and if  is a random variable corresponding to the observed value of
is a random variable corresponding to the observed value of  and the expectation
and the expectation  .
. and the momentum operator
and the momentum operator  .
. , we find that the expected value of position is
, we find that the expected value of position is 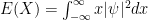 . Note: since
. Note: since  we can view
we can view  as a probability density function; hence if
as a probability density function; hence if  is any “reasonable” function of
is any “reasonable” function of  . Of course we can calculate the variance and other probability moments in a similar way; e. g.
. Of course we can calculate the variance and other probability moments in a similar way; e. g.  .
.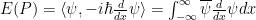 and
and 
 . But we saw that this can change with time so:
. But we saw that this can change with time so: 
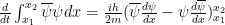



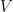 is real.
is real.  and the second by
and the second by 

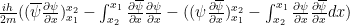
 by
by  (note the minus sign) and to say
(note the minus sign) and to say  (see the reason for the minus sign?)
(see the reason for the minus sign?)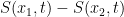 will tell you if the probability of finding the particle between position
will tell you if the probability of finding the particle between position  and
and  is going up (positive sign) or down, and by what rate. But it is important that these are position PROBABILITY current and not PARTICLE current; same for
is going up (positive sign) or down, and by what rate. But it is important that these are position PROBABILITY current and not PARTICLE current; same for  ; this is the position probability density function, not the particle density function.
; this is the position probability density function, not the particle density function.  and
and
 ; say
; say  . Note: in classical mechanics this follows from Hooke’s law:
. Note: in classical mechanics this follows from Hooke’s law:  . In classical mechanics this leads to the following differential equation:
. In classical mechanics this leads to the following differential equation:  which leads to
which leads to  which has general solution
which has general solution  where
where  The energy of the system is given by
The energy of the system is given by  where
where  ):
):

 Now we can use the chain rule to calculate:
Now we can use the chain rule to calculate:  . Substitution into our equation in
. Substitution into our equation in  yields:
yields:
 is just a real valued constant, we can choose
is just a real valued constant, we can choose  .
.

 gives us:
gives us:
 .
. where here
where here  is the
is the  Hermite polynomial. Here are a few of these:
Hermite polynomial. Here are a few of these:
 ) are here:
) are here:

 where
where  is energy and
is energy and  Note that we can then write
Note that we can then write  . Analogues exist in quantum mechanics and this is the subject of:
. Analogues exist in quantum mechanics and this is the subject of: and
and  respectively. If
respectively. If  .
.
 and
and 
 where
where  means “do
means “do  twice”. So
twice”. So  .
. exists but
exists but  might not exist. Here is a simple example: let
might not exist. Here is a simple example: let  . Then
. Then  but
but  fails to exist.
fails to exist. . If this statement is confusing, remember that
. If this statement is confusing, remember that  . Clearly, any well behaved real valued function of
. Clearly, any well behaved real valued function of  . So we must show that
. So we must show that  . Now we note that
. Now we note that  (
(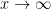 doesn’t exist but the integral still converges) and so by the integration by parts formula we get
doesn’t exist but the integral still converges) and so by the integration by parts formula we get  .
. is also Hermitian. That has some consequences:
is also Hermitian. That has some consequences: 

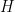 and obtain:
and obtain:

 . The second one is the time dependent one and applies to the state vector in general (not just the stationary states). It is called the fundamental time evolution equation for the state vector.
. The second one is the time dependent one and applies to the state vector in general (not just the stationary states). It is called the fundamental time evolution equation for the state vector.  which has a modulus of 1. So the new state vector describes the same state as the old one.
which has a modulus of 1. So the new state vector describes the same state as the old one. and eigenvalues
and eigenvalues  . If we take an observation (say, at time
. If we take an observation (say, at time  (we make the assumption that there is only one eigenvector per eigenvalue).
(we make the assumption that there is only one eigenvector per eigenvalue). completely determines the density function and because
completely determines the density function and because  it make sense to determine
it make sense to determine  . Note that the eigenvectors
. Note that the eigenvectors 
 We now substitute into the previous equation to obtain:
We now substitute into the previous equation to obtain:
 by
by  . Then we see that we have the infinite coupled differential equations:
. Then we see that we have the infinite coupled differential equations:  . That is, the rate of change of one of the
. That is, the rate of change of one of the  . Now rewrite:
. Now rewrite:  . Now differentiate with respect to
. Now differentiate with respect to 
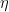 and then
and then Now use the fact that the
Now use the fact that the  are eigenvectors for
are eigenvectors for  where
where  where
where  is the initial state vector (before it had time to evolve).
is the initial state vector (before it had time to evolve). 

 . But since
. But since  . Then we have
. Then we have 
 for some
for some 

 . Then because the probability distribution is completely determined by the eigenvalues
. Then because the probability distribution is completely determined by the eigenvalues  and
and  , the distribution does NOT change with time. This motivates us to define the stationary states of a system:
, the distribution does NOT change with time. This motivates us to define the stationary states of a system:  .
.  . One can work this out by expanding
. One can work this out by expanding  if one wants to.
if one wants to.

 .
. once again; note that if
once again; note that if  commute then the expectation of the state vector (or the standard deviation for that matter) does not evolve with time. This is certainly true for
commute then the expectation of the state vector (or the standard deviation for that matter) does not evolve with time. This is certainly true for 
 where
where  This gives an estimate of how much time must elapse before the state changes enough to equal the uncertainty in the observable.
This gives an estimate of how much time must elapse before the state changes enough to equal the uncertainty in the observable. 
 is small (i. e., the state changes rapidly) then the uncertainty is large; hence energy is impossible to be well defined (as a numerical value). If the energy has low uncertainty then
is small (i. e., the state changes rapidly) then the uncertainty is large; hence energy is impossible to be well defined (as a numerical value). If the energy has low uncertainty then 