I left after the second large lecture and didn’t get a chance to blog about them before now.
But what I saw was very good.
The early lecture was by Lauren Ancel Meyers (Texas-Austin) on Mathematical Approaches to Infectious Disease and Control This is one of those talks where I wish I had access to the slides; they were very useful.
She started out by giving a brief review of the classical SIR model of the spread of a disease which uses the mass action principle (from science) that says that the rate of of change of those infected with a disease is proportional to the product of those who are susceptible to the disease and those who can transmit the disease:  . (this actually came from chemistry). Of course, those who are infected either recover or die; this action reduces the number infected. Of course, the number of susceptible also drop.
. (this actually came from chemistry). Of course, those who are infected either recover or die; this action reduces the number infected. Of course, the number of susceptible also drop.
This leads to a system of differential equations. The basic reproduction number is significant:
 where
where  is the recovery rate and
is the recovery rate and 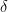 is the death rate. Note: if
is the death rate. Note: if  then the disease will die off; if it is greater than 1 we have a pandemic. We can reduce this by reducing
then the disease will die off; if it is greater than 1 we have a pandemic. We can reduce this by reducing 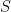 (vaccination or quarantine), increasing recovery or, yes, increasing the death rate (as we do with livestock; remember the massive poultry slaughters to stop the spread of flu).
(vaccination or quarantine), increasing recovery or, yes, increasing the death rate (as we do with livestock; remember the massive poultry slaughters to stop the spread of flu).
Of course, this model assumes that the infected organisms contact others at random and have equal probabilities of spreading, that the virus doesn’t evolve, etc.
So this model had to be improved on; methods from percolation theory were developed.
So many factors had to be taken into account such as: how much vaccine is there to spread? How far along is the outbreak? (at first children get it; then adults). How severe is the consequences? (we don’t want the virus to evolve to a more dangerous, more resistant form).
Note that the graph model of transmission is dynamic; it can actually change with time.
Of special interest: one can recover the rate of infections of the various strains (and the strains vary from season to season) by looking at the number of times flu related words were searched for on Google. The graph overlap (search rate versus reported cases) was stunning; the only exception is when a scare occurred; then the word search rate lead the actual cases, but that happened only once (2009). Note also that predictions of what will happen get better with a shorter time window (not a surprise).
There was much more in the talk; for example the role of the location of the providers of vaccines was discussed (what is the optimal way to spread out the availability of a given vaccine?)
Manjur Bhargava, Lecture III
First, he noted that in the case where 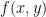 was cubic, that there is always a rational change of variable to put the curve into the following form:
was cubic, that there is always a rational change of variable to put the curve into the following form:  where
where 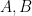 are integers that have the following property: if
are integers that have the following property: if 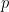 is any prime where
is any prime where  divides
divides  then
then  does NOT divide
does NOT divide  . So this curve can be denoted as
. So this curve can be denoted as  .
.
Also, there are two “generic” cases of curves depending on whether the cubic in  has only one real root or three real roots.
has only one real root or three real roots.

This is a catalog of elliptical algebraic curves of the form  taken from here. The everywhere smooth curves are considered; the ones with a disconnected graph are said to have “an egg”; those are the ones in which the cubic in has three real roots. In the connected case, the cubic has only one; remember that these are genus one curves; we are seeing a slice of a torus in 4-space (a space with two complex dimensions) in the plane.
taken from here. The everywhere smooth curves are considered; the ones with a disconnected graph are said to have “an egg”; those are the ones in which the cubic in has three real roots. In the connected case, the cubic has only one; remember that these are genus one curves; we are seeing a slice of a torus in 4-space (a space with two complex dimensions) in the plane.
Also recall that the rational points on the curve may be finite or infinite. It turns out that the rational points (both coordinates rational) have a group structure (this is called the “divisor class group” in algebraic geometry). This group has a structure that can be understood by a simple geometric construction in the plane, though checking that the operation is associative can be very tedious.
I’ll give a description of the group operation and provide an elementary example:
First, note that if  is a point on an elliptical curve, then so is
is a point on an elliptical curve, then so is  (note: the
(note: the  on the left hand side of the defining equation). That is important. Also note that we will restrict ourselves to smooth curves (that have a well defined tangent line).
on the left hand side of the defining equation). That is important. Also note that we will restrict ourselves to smooth curves (that have a well defined tangent line).
The elements of our group will be the rational points of the curve (if any?) along with the point at infinity. If  I will denote
I will denote  .
.
The operation: if  are rational points on the curve, construct the line
are rational points on the curve, construct the line  with equation
with equation  Substitute this into and note that we now have a cubic equation in that has two rational solutions; hence there must be a third rational solution
Substitute this into and note that we now have a cubic equation in that has two rational solutions; hence there must be a third rational solution  . Associated to that value is two
. Associated to that value is two 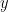 values (possibly double if the value is zero). Call that point on the curve
values (possibly double if the value is zero). Call that point on the curve 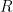 then define
then define  where
where  is the reflection of about the axis.
is the reflection of about the axis.
Note the following: that this operation commutes is immediate. If one adds a point to itself, one uses the tangent line as the line through two points; note that such a line might not hit the curve a third time. If such a line is vertical (parallel to the axis) the result is said to be “0” (the point at infinity); if the line is not vertical but still misses the rest of the curve, it is counted three times; that is:  . Here are the situations:
. Here are the situations:

Of course,  is the group identity. Associativity is difficult to check directly (elementary algebra but very tedious; perhaps 3-4 pages of it?).
is the group identity. Associativity is difficult to check directly (elementary algebra but very tedious; perhaps 3-4 pages of it?).
Since the group is Abelian, if the group is finite it must be isomorphic to  where the second part is the torsion part and the number of infinite cyclic factors is the rank. The rank turns out to be the geometric rank; that is, the minimum number of points required to obtain all of the rational points (infinite number) of the curve. Let
where the second part is the torsion part and the number of infinite cyclic factors is the rank. The rank turns out to be the geometric rank; that is, the minimum number of points required to obtain all of the rational points (infinite number) of the curve. Let 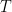 be the torsion subgroup; Mazur proved that
be the torsion subgroup; Mazur proved that  .
.
Let’s look at an example of a subgroup of such a curve: let the curve be given by  It is easy to see that
It is easy to see that  are all rational points. Let’s see how these work:
are all rational points. Let’s see how these work:  so this point has order 2. But there is also some interesting behavior: note that
so this point has order 2. But there is also some interesting behavior: note that  which implies that
which implies that  So the tangent line through
So the tangent line through  and
and  are both horizontal; that means that both of these points have order 3. Note also that
are both horizontal; that means that both of these points have order 3. Note also that  as the tangent line runs through the point . Similarly
as the tangent line runs through the point . Similarly  So, we can see that
So, we can see that  have order 6,
have order 6,  have order 3 and
have order 3 and  has order 2. So there is an isomorphism
has order 2. So there is an isomorphism 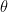 where
where  where the integers are mod 6.
where the integers are mod 6.
So, we’ve shown a finite Abelian subgroup of the group of rationals of this curve. It turns out that these are the only rational points; here all we get is the torsion group. This curve has rank zero (not obvious).
Note: the group of rationals for  is isomorphic to
is isomorphic to  though this isn’t obvious.
though this isn’t obvious.
The generator of the  term is
term is  and
and  generates the the torsion term.
generates the the torsion term.
History note Some of this was tackled by computers many years ago (Birch, Swinnerton-Dyer). Because computers were so limited in those days, the code had to be very efficient and therefore people had to do quite a bit of work prior to putting it into code; evidently this lead to progress. The speaker joked that such progress might not have been so quickly today due to better computers!
If one looks at  where is prime, we should have about points on the curve. So we’d expect that
where is prime, we should have about points on the curve. So we’d expect that  . If there are a lot of rational points on the curve, most of these points would correspond to
. If there are a lot of rational points on the curve, most of these points would correspond to  points. So there is a conjecture by Birch, Swinnerton-Dyer:
points. So there is a conjecture by Birch, Swinnerton-Dyer:
 where
where  is the rank.
is the rank.
Yes, this is hard; win one million US dollars if you prove it. 🙂
Back to the curves: there are ways of assigning “heights” to these curves; some include:
 or
or 
Given this ordering, what are average sizes of ranks?
Katz-Sarnak: half have rank 0, half have rank 1. It was known that average ranks are bounded; previous results had the bound at 2.3, 2, 1.79, assuming that the Generalized Riemann Hypothesis and the Birch, Swinnerton-Dyer conjecture were asssumed.
The speaker and his students got some results without making these large assumptions:
Result 1: when  is ordered by height, the average rank is less than 1.
is ordered by height, the average rank is less than 1.
Result 2: A positive portion (10 percent, at least) have rank 0.
Result 3: at least 80 percent have rank 0 or 1.
Corollary: the BSD is true for a positive proportion of elliptic curves;
The speaker (with his student) proved results 1, 2, and 3 and then worked backwards on the existing “BSD true implies X” results to show that BSD was true for a positive proportion of the elliptic curves.