I am always looking for interesting calculus problems to demonstrate various concepts and perhaps generate some interest in pure mathematics.
And yes, I like to “blow off some steam” by spending some time having some non-technical mathematical fun with elementary mathematics.
This post uses only:
1. Integration by parts and basic reduction formulas.
2. Trig substitution.
3. Calculation of volumes (and hyper volumes) by the method of cross sections.
4. Induction
5. Elementary arithmetic involving factorials.
The quest: find a formula that finds the (hyper)volume of the region 
We will assume that the usual tools of calculus work as advertised.
Start. If we done the (hyper)volume of the k-ball by 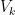 we will start with the assumption that
we will start with the assumption that  ; that is, the distance between the endpoints of
; that is, the distance between the endpoints of ![[-R,R]](https://s0.wp.com/latex.php?latex=%5B-R%2CR%5D+&bg=ffffff&fg=000000&s=0&c=20201002) is
is  .
.
Step 1: we show, via induction, that 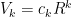 where
where  is a constant and
is a constant and 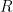 is the radius.
is the radius.
Our proof will be inefficient for instructional purposes.
We know that 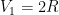 hence the induction hypothesis holds for the first case and
hence the induction hypothesis holds for the first case and 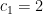 . We now go to show the second case because, for the beginner, the technique will be easier to follow further along if we do the
. We now go to show the second case because, for the beginner, the technique will be easier to follow further along if we do the 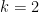 case.
case.
Yes, I know that you know that  and you’ve seen many demonstrations of this fact. Here is another: let’s calculate this using the method of “area by cross sections”. Here is
and you’ve seen many demonstrations of this fact. Here is another: let’s calculate this using the method of “area by cross sections”. Here is  with some
with some  cross sections drawn in.
cross sections drawn in.
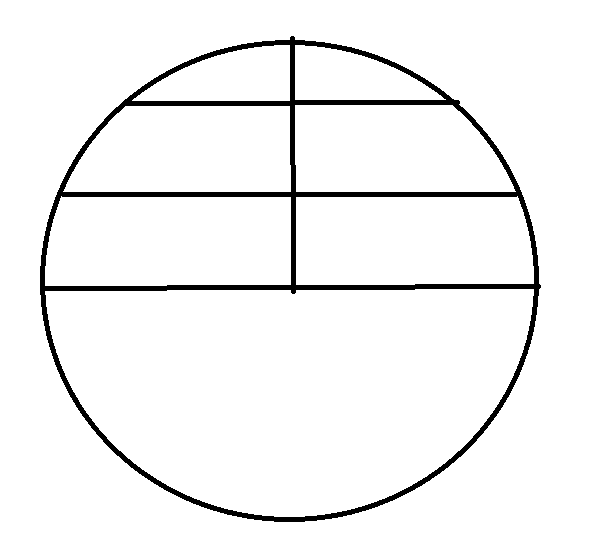
Now do the calculation by integrals: we will use symmetry and only do the upper half and multiply our result by 2. At each  level, call the radius from the center line to the circle
level, call the radius from the center line to the circle  so the total length of the “y is constant” level is
so the total length of the “y is constant” level is  and we “multiply by thickness “dy” to obtain
and we “multiply by thickness “dy” to obtain  .
.
But remember that the curve in question is and so if we set  we have
we have  and so our integral is
and so our integral is 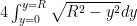
Now this integral is no big deal. But HOW we solve it will help us down the road. So here, we use the change of variable (aka “trigonometric substitution”):  to change the integral to:
to change the integral to:
 therefore
therefore
 where:
where:

Yes, I know that this is an easy integral to solve, but I first presented the result this way in order to make a point.
Of course, 
Therefore,  as expected.
as expected.
Exercise for those seeing this for the first time: compute  and
and  by using the above methods.
by using the above methods.
Inductive step: Assume  Now calculate using the method of cross sections above (and here we move away from x-y coordinates to more general labeling):
Now calculate using the method of cross sections above (and here we move away from x-y coordinates to more general labeling):

Now we do the substitutions: first of all, we note that 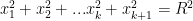 and so
and so
 . Now for the key observation:
. Now for the key observation:  and so
and so 
Now use the induction hypothesis to note:

Now do the substitution  and the integral is now:
and the integral is now:
 which is what we needed to show.
which is what we needed to show.
In fact, we have shown a bit more. We’ve shown that  and, in general,
and, in general,

Finishing the formula
We now need to calculate these easy calculus integrals: in this case the reduction formula:
 is useful (it is merely integration by parts). Now use the limits and elementary calculation to obtain:
is useful (it is merely integration by parts). Now use the limits and elementary calculation to obtain:
 to obtain:
to obtain:
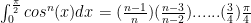 if
if  is even and:
is even and:
 if is odd.
if is odd.
Now to come up with something resembling a closed formula let’s experiment and do some calculation:
Note that 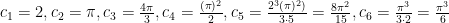 .
.
So we can make the inductive conjecture that  and see how it holds up:
and see how it holds up: 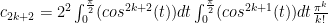

Now notice the telescoping effect of the fractions from the 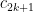 factor. All factors cancel except for the
factor. All factors cancel except for the  in the first denominator and the 2 in the first numerator, as well as the
in the first denominator and the 2 in the first numerator, as well as the  factor. This leads to:
factor. This leads to:
 as required.
as required.
Now we need to calculate 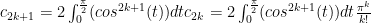

To simplify this further: split up the factors of the  in the denominator and put one between each denominator factor:
in the denominator and put one between each denominator factor:
 Now multiply the denominator by
Now multiply the denominator by 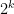 and put one factor with each
and put one factor with each  factor in the denominator; also multiply by in the numerator to obtain:
factor in the denominator; also multiply by in the numerator to obtain:
 Now gather each factor of 2 in the numerator product of the 2k, 2k-2…
Now gather each factor of 2 in the numerator product of the 2k, 2k-2…
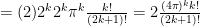 which is the required formula.
which is the required formula.
So to summarize:
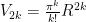
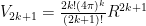
Note the following:  . If this seems strange at first, think of it this way: imagine the n-ball being “inscribed” in an n-cube which has hyper volume
. If this seems strange at first, think of it this way: imagine the n-ball being “inscribed” in an n-cube which has hyper volume 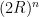 . Then consider the ratio
. Then consider the ratio  ; that is, the n-ball holds a smaller and smaller percentage of the hyper volume of the n-cube that it is inscribed in; note the
; that is, the n-ball holds a smaller and smaller percentage of the hyper volume of the n-cube that it is inscribed in; note the  corresponds to the number of corners in the n-cube. One might see that the rounding gets more severe as the number of dimensions increases.
corresponds to the number of corners in the n-cube. One might see that the rounding gets more severe as the number of dimensions increases.
One also notes that for fixed radius R,  as well.
as well.
There are other interesting aspects to this limit: for what dimension does the maximum hypervolume occur? As you might expect: this depends on the radius involved; a quick glance at the hyper volume formulas will show why. For more on this topic, including an interesting discussion on this limit itself, see Dave Richardson’s blog Division by Zero. Note: his approach to finding the hyper volume formula is also elementary but uses polar coordinate integration as opposed to the method of cross sections.

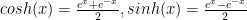 and then it is immediate that the standard “half/double angle formulas hold; we do remember that
and then it is immediate that the standard “half/double angle formulas hold; we do remember that  .
. 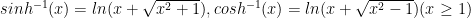 .
.  then
then  so multiply both sides by
so multiply both sides by  to obtain
to obtain  now use the quadratic formula to solve for
now use the quadratic formula to solve for 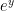 and keep in mind that
and keep in mind that  is positive.
is positive. branch of
branch of  and that
and that 
 (just set up
(just set up  . ) and
. ) and  (similar derivation).
(similar derivation).
 and obtain
and obtain  . Now use
. Now use  and we obtain:
and we obtain: . The back substitution isn’t that hard if we recognize
. The back substitution isn’t that hard if we recognize 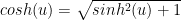 so we have
so we have  . Back substitution is now easy:
. Back substitution is now easy: . No integration by parts is required and the dreaded
. No integration by parts is required and the dreaded  integral is avoided. Ok, I was a bit loose about the domains here; we can make this valid for negative values of
integral is avoided. Ok, I was a bit loose about the domains here; we can make this valid for negative values of  by using an absolute value with the
by using an absolute value with the  term.
term.  but that is the subject of another post)
but that is the subject of another post) . Typically, we insist that the functions be, say,
. Typically, we insist that the functions be, say,  and note that it is a bit of a chore to show that the convolution of two
and note that it is a bit of a chore to show that the convolution of two  for
for ![x \in (0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%280%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and zero elsewhere)
and zero elsewhere)  be the function that is
be the function that is 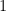 for
for ![x \in [\frac{-1}{2}, \frac{1}{2}]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B%5Cfrac%7B-1%7D%7B2%7D%2C+%5Cfrac%7B1%7D%7B2%7D%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and zero elsewhere. So, what is
and zero elsewhere. So, what is  ???
???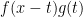 only assumes the value of
only assumes the value of 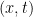 plane and is zero elsewhere; this is just like doing an iterated integral of a two variable function; at least the first step. This is why it fits well into calculus III.
plane and is zero elsewhere; this is just like doing an iterated integral of a two variable function; at least the first step. This is why it fits well into calculus III. for the following region:
for the following region: 
 .
. 
 has the following description:
has the following description:![f(x-t)f(t)=\left\{\begin{array}{c} 1,x \in [-1,0], -\frac{1}{2} t \le \frac{1}{2}+x \\ 1 ,x\in [0,1], -\frac{1}{2}+x \le t \le \frac{1}{2} \\ 0 \text{ elsewhere} \end{array}\right.](https://s0.wp.com/latex.php?latex=f%28x-t%29f%28t%29%3D%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bc%7D+1%2Cx+%5Cin+%5B-1%2C0%5D%2C+-%5Cfrac%7B1%7D%7B2%7D+t+%5Cle+%5Cfrac%7B1%7D%7B2%7D%2Bx+%5C%5C+1+%2Cx%5Cin+%5B0%2C1%5D%2C+-%5Cfrac%7B1%7D%7B2%7D%2Bx+%5Cle+t+%5Cle+%5Cfrac%7B1%7D%7B2%7D+%5C%5C+0+%5Ctext%7B+elsewhere%7D+%5Cend%7Barray%7D%5Cright.++&bg=ffffff&fg=000000&s=0&c=20201002)
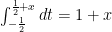 for
for  and
and  for
for ![x \in [0,1]](https://s0.wp.com/latex.php?latex=x+%5Cin+%5B0%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) .
.
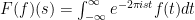 provided the integral converges.
provided the integral converges.  ; one can check that
; one can check that  . One way is to use the fact that
. One way is to use the fact that  and do the substitution
and do the substitution  ; of course one should be able to
; of course one should be able to  ; that is, this modified Gaussian function is “its own Fourier transform”.
; that is, this modified Gaussian function is “its own Fourier transform”.
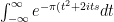 . Now complete the square to get:
. Now complete the square to get: 
 alone and write as a square:
alone and write as a square: 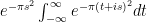
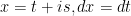 to obtain:
to obtain:
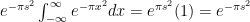
 along the retangular path
along the retangular path 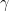 :
: 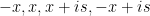 and let
and let 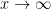

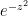 is analytic.
is analytic.  and the magnitude goes to zero as
and the magnitude goes to zero as 
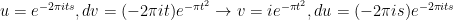 and the integral becomes:
and the integral becomes: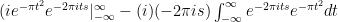
 . The second term is merely:
. The second term is merely: .
.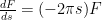 which is a differential equation in
which is a differential equation in 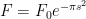 (a simple separation of variables calculation will verify this). Now to solve for the constant
(a simple separation of variables calculation will verify this). Now to solve for the constant 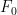 note that
note that 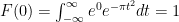 .
. 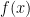 represent the tent map: the support of
represent the tent map: the support of  is
is ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and it has the following graph:
and it has the following graph:![f(x)=\left\{\begin{array}{c} x+1,x \in [-1,0) \\ 1-x ,x\in [0,1] \\ 0 \text{ elsewhere} \end{array}\right.](https://s0.wp.com/latex.php?latex=f%28x%29%3D%5Cleft%5C%7B%5Cbegin%7Barray%7D%7Bc%7D+x%2B1%2Cx+%5Cin+%5B-1%2C0%29+%5C%5C+1-x+%2Cx%5Cin+%5B0%2C1%5D+%5C%5C+0+%5Ctext%7B+elsewhere%7D+%5Cend%7Barray%7D%5Cright.++&bg=ffffff&fg=000000&s=0&c=20201002)

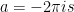 and do the integrals:
and do the integrals: and substitute and simplify later:
and substitute and simplify later:
 and the next two have the same anti-derivative which can be obtained by a “integration by parts” calculation:
and the next two have the same anti-derivative which can be obtained by a “integration by parts” calculation:  ; evaluating the limits yields:
; evaluating the limits yields:
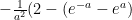 . NOW use
. NOW use  and we have the integral is
and we have the integral is  by Euler’s formula.
by Euler’s formula.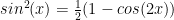 so
so  so our answer is
so our answer is  which is often denoted as
which is often denoted as  as
as  function
function (as we want the function to have zeros at integers and to “equal” one at
(as we want the function to have zeros at integers and to “equal” one at 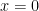 (remember that famous limit!)
(remember that famous limit!) made the algebra a whole lot easier.
made the algebra a whole lot easier. is is because, in electrical engineering,
is is because, in electrical engineering,  usually stands for “current”.
usually stands for “current”. (usual abuse of the equals sign) rather than writing it out in sines and cosines. of course,
(usual abuse of the equals sign) rather than writing it out in sines and cosines. of course, 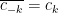 if
if  is real valued.
is real valued. for when
for when  . There is nothing to it; easy integral. Of course, one has to demonstrate the validity of
. There is nothing to it; easy integral. Of course, one has to demonstrate the validity of 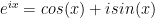 and show that the usual differentiation rules work ahead of time, but you need to do that only once.
and show that the usual differentiation rules work ahead of time, but you need to do that only once. 
 it isn’t hard to see that
it isn’t hard to see that 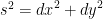 and so going with the portion in the first quadrant: one can derive that the circumference is given by the
and so going with the portion in the first quadrant: one can derive that the circumference is given by the  is a very famous example. Here is a good, accessible paper on the
is a very famous example. Here is a good, accessible paper on the 
 to obtain:
to obtain: 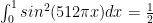

 gets cut in half as the rows go down).
gets cut in half as the rows go down).
 and do some mathematics!
and do some mathematics!
 is the n’th Legendre polynomial then:
is the n’th Legendre polynomial then: .
. has degree
has degree 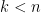 then
then 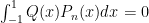 .
.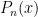 has n simple roots in
has n simple roots in  which are symmetric about 0.
which are symmetric about 0. form an orthogonal basis for the vector pace of polynomials of degree
form an orthogonal basis for the vector pace of polynomials of degree  where the
where the 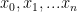 are all distinct, the Lagrange polynomial through these points (called “nodes”) is defined to be:
are all distinct, the Lagrange polynomial through these points (called “nodes”) is defined to be: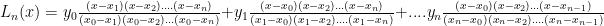
 because the associated coefficient for the
because the associated coefficient for the  term is 1 and the other coefficients are zero. We call the coefficient polynomials
term is 1 and the other coefficients are zero. We call the coefficient polynomials 
 continuous derivatives on some open interval containing
continuous derivatives on some open interval containing 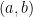 and if
and if  is the Lagrange polynomial running through the nodes
is the Lagrange polynomial running through the nodes 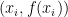 where all of the
where all of the ![x_i \in [a,b]](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) then the maximum of
then the maximum of 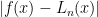 is bounded by
is bounded by 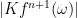 where
where ![\omega \in [a,b]](https://s0.wp.com/latex.php?latex=%5Comega+%5Cin+%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) . So if the n+1’st derivative of
. So if the n+1’st derivative of 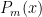 be the
be the 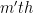 Legendre polynomial, let
Legendre polynomial, let  be the roots, and
be the roots, and 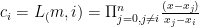 , the j’th coefficient polynomial for the Lagrange polynomial through the nodes
, the j’th coefficient polynomial for the Lagrange polynomial through the nodes  .
.  be any polynomial of degree less than
be any polynomial of degree less than  . First: the Lagrange polynomial
. First: the Lagrange polynomial  through the nodes
through the nodes  represents
represents  derivative of
derivative of 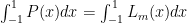


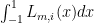 only depends on the Legendre polynomial being used and NOT on
only depends on the Legendre polynomial being used and NOT on 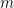 .
. whose degree are less than
whose degree are less than 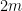 . This is where the orthogonality of the Legendre polynomials will be used.
. This is where the orthogonality of the Legendre polynomials will be used.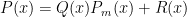 where BOTH
where BOTH  have degree less than
have degree less than  ; that is where the fact that the
; that is where the fact that the  are the roots of the Legendre polynomials matters.
are the roots of the Legendre polynomials matters. . Now because of property 2 above,
. Now because of property 2 above,  .
.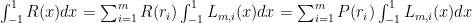
 with, say, n = 5. We know that the exact answer is
with, say, n = 5. We know that the exact answer is 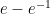 . But using the quadrature method with a spreadsheet:
. But using the quadrature method with a spreadsheet:
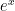 to the roots in column A; the products of the weights with
to the roots in column A; the products of the weights with  are in column G, and then we do a simple sum to get a very accurate approximation to the integral.
are in column G, and then we do a simple sum to get a very accurate approximation to the integral. . The inexactness comes from the higher order Taylor terms.
. The inexactness comes from the higher order Taylor terms.  , one uses the change of variable:
, one uses the change of variable:  to convert this to
to convert this to 
![[a,b]](https://s0.wp.com/latex.php?latex=%5Ba%2Cb%5D+&bg=ffffff&fg=000000&s=0&c=20201002) and a positive integer
and a positive integer ![x_i \in [a,b], i \in \{1,2,3,...n\}](https://s0.wp.com/latex.php?latex=x_i+%5Cin+%5Ba%2Cb%5D%2C+i+%5Cin+%5C%7B1%2C2%2C3%2C...n%5C%7D+&bg=ffffff&fg=000000&s=0&c=20201002) and weights
and weights  so that
so that  is estimated by
is estimated by 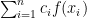 and that this estimate is exact for polynomials of degree
and that this estimate is exact for polynomials of degree  and uses
and uses  and is exact for polynomials of degree 3 or less.
and is exact for polynomials of degree 3 or less.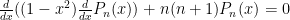 . To see that these solutions are indeed polynomials (for integer values of
. To see that these solutions are indeed polynomials (for integer values of  .
. for the vector space of all polynomials (real coefficients) of finite degree, these polynomials are mutually orthogonal; that is, if
for the vector space of all polynomials (real coefficients) of finite degree, these polynomials are mutually orthogonal; that is, if 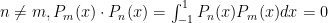 .
. .
.  form an orthogonal basis for the vector subspace of all polynomials of degree n or less. If follows immediately that if
form an orthogonal basis for the vector subspace of all polynomials of degree n or less. If follows immediately that if  , then
, then  (
(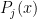 where each
where each  )
) 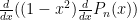 with associated eigenvalue
with associated eigenvalue 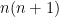 and such eigenfunctions are orthogonal.
and such eigenfunctions are orthogonal.  and let
and let 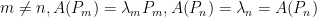 and
and  .
. . But because
. But because  . Therefore,
. Therefore, 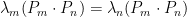 which means that
which means that 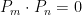 .
.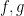 both meet an appropriate condition (say, twice differentiable on some interval containing
both meet an appropriate condition (say, twice differentiable on some interval containing  :
:  . But
. But  and the result follows by symmetry.
and the result follows by symmetry. 
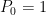 and let
and let  ; here the
; here the  are the polynomials normalized to unit length (that is,
are the polynomials normalized to unit length (that is,  . That is,
. That is, 
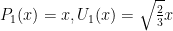
 Note that this is not too bad since many of the integrals are just integrals of an odd function over
Note that this is not too bad since many of the integrals are just integrals of an odd function over ![[-1,1]](https://s0.wp.com/latex.php?latex=%5B-1%2C1%5D&bg=ffffff&fg=000000&s=0&c=20201002) which become zero.
which become zero.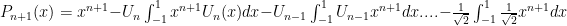
 . Let
. Let  ; note that
; note that 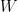 has degree
has degree 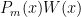 now has all roots of even multiplicity; hence the polynomial
now has all roots of even multiplicity; hence the polynomial  because
because 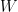 has degree strictly less than
has degree strictly less than 